【Python3 爬虫】15_Fiddler抓包分析
我们要抓取一些网页源码看不到的信息,例如:淘宝的评论等
我们可以使用工具Fiddler进行抓取
软件下载地址:https://pan.baidu.com/s/1nPKPwrdfXM62LlTZsoiDsg 密码:wche
安装不详细介绍,直接下一步即可
安装完成后,运行程序如下:
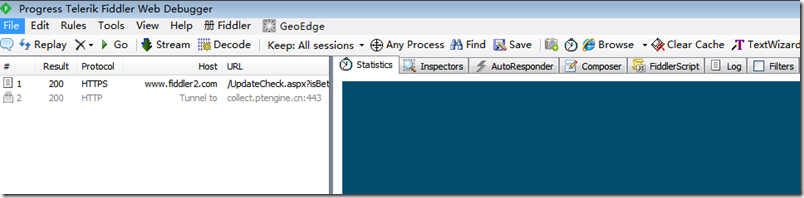
设置代理
打开火狐浏览器
如下设置:
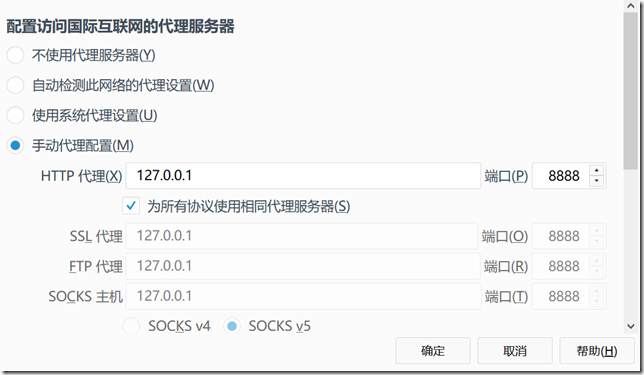
Fiddler默认只能抓取HTTP协议的网页,不能抓取HTTPS协议的网页,而我们很多时候,都需要抓HTTPS协议的网页。
Tool-----Options-----HTTPS,设置如下:
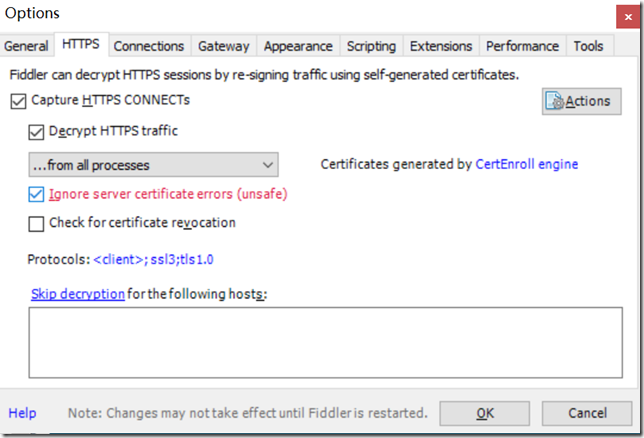
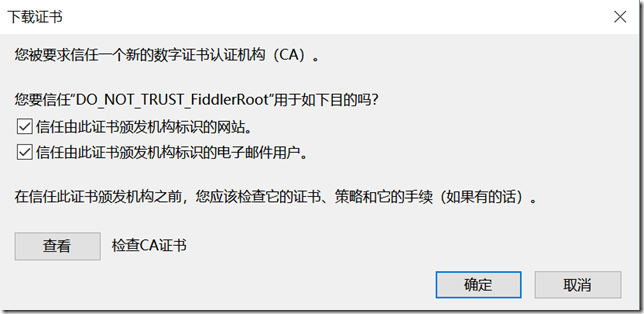
设置过程中或许会提示如下,直接点击Yes即可
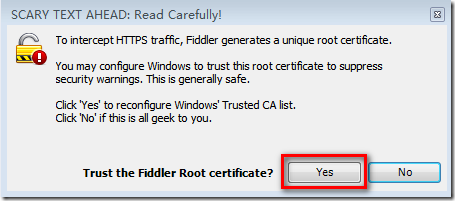
然后点击Actions----Export Root Certificate to Desktop

点击确定后,桌面上就出现该图标
接着,我们可以在浏览器导入该证书,我们打开火狐浏览器
【选项】---【隐私与安全】--【证书】---【查看证书】---【导入】
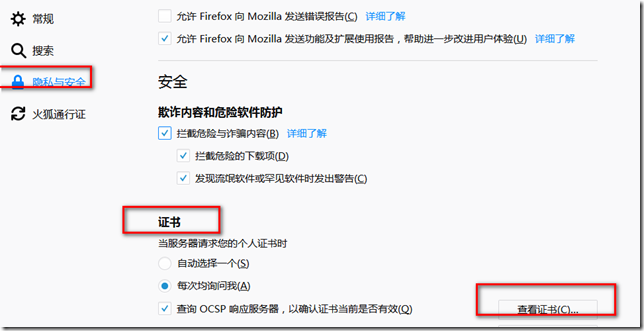
点击【导入】
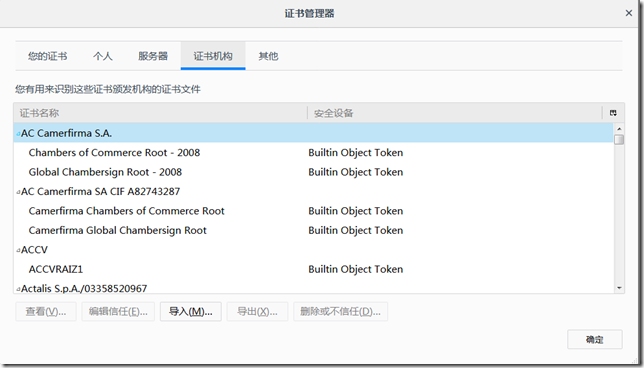
勾选下图所示2个按钮
上述信息设置完毕之后,我们刷新网址:https://www.taobao.com/

再看Fiddler什么也没有
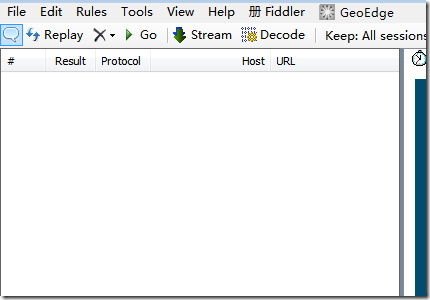
那么是什么问题呢?
接下来,我们win+R 并输入certmgr.msc并回车打开证书管理器
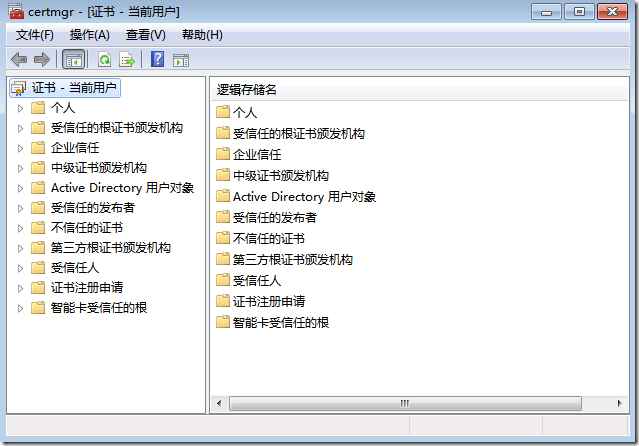
【操作】---【查找证书】
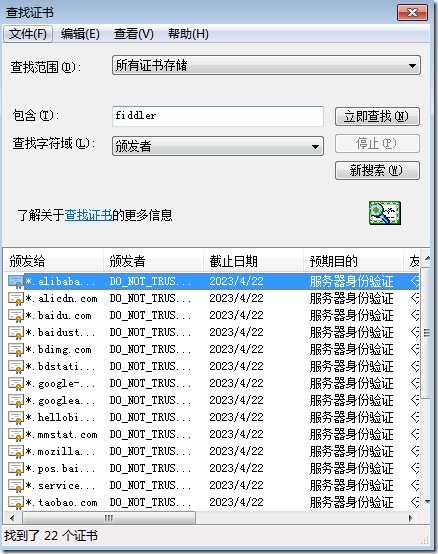
此处,我们找到了很多个证书,我们通过右键--删除所有证书
删除完成之后如下图:
接下来,删除火狐中的相关证书
【选项】---【隐私与安全】---【证书】---【查看证书】
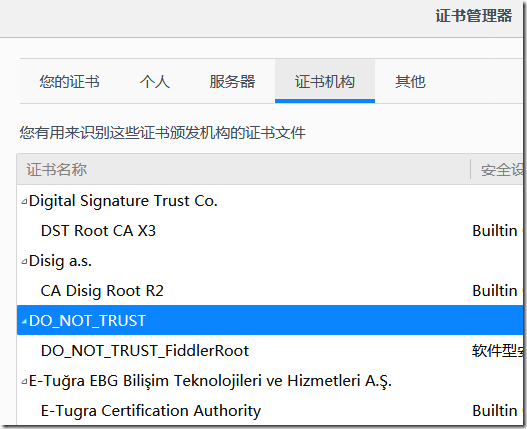
找到DO_NOT开头的Fiddler证书进行删除
依次删除【个人】、【服务器】、【其他】下的证书
这些证书删除完毕以后
点击以下地址下载文件
https://files.cnblogs.com/files/OliverQin/fiddlercertmaker.zip
下载后解压,直接打开,报错忽略即可
接着重启Fiddler,重启完毕后,随便打开一个商品的评论

先使用clear清除内容,然后刷新评论
我刷新的页面如下:

刷新完毕之后再次看Fiddler
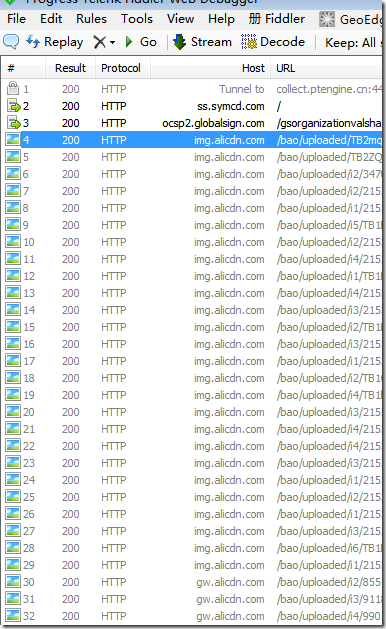
我们可以看到,已经可以抓取了,如果上述设置还是不行,那么打开Fiddler安装的目录:例如(D:\soft\fiddler)
在cmd中进入到该目录,执行以下代码
makecert.exe -r -ss my -n "CN=DO_NOT_TRUST_FiddlerRoot, O=DO_NOT_TRUST, OU=Created by http://www.fiddler2.com" -sky signature -eku 1.3.6.1.5.5.7.3.1 -h 1 -cy authority -a sha1 -m 120 -b 09/05/2012
执行结果如下:

执行完毕之后再次导出导入CA证书。
【Python3 爬虫】15_Fiddler抓包分析的更多相关文章
- 抓包分析、多线程爬虫及xpath学习
1.抓包分析 1.1 Fiddler安装及基本操作 由于很多网站采用的是HTTPS协议,而fiddler默认不支持HTTPS,先通过设置使fiddler能抓取HTTPS网站,过程可参考(https:/ ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续一)
通过前一节得出地址可能的构建规律,如下: https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksT ...
- 爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析,更加深入的了解网络爬虫的本质与内涵 1.测试环境 浏览器:Chrome 浏览器 浏览器版本:67.0.33 ...
- python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池 用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用. 作用:每次访问代表使用的浏览器不一样 import urllib.request import re import rand ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续二)
一.URL分析 通过对“Python机器学习”结果抓包分析,有两个无规律的参数:_ksTS和callback.通过构建如下URL可以获得目标关键词的检索结果,如下所示: https://s.taoba ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析
一.抓包基础 在淘宝上搜索“Python机器学习”之后,试图抓取书名.作者.图片.价格.地址.出版社.书店等信息,查看源码发现html-body中没有这些信息,分析脚本发现,数据存储在了g_page_ ...
- Wireshark抓包分析/TCP/Http/Https及代理IP的识别
前言 坦白讲,没想好怎样的开头.辗转三年过去了.一切已经变化了许多,一切似乎从没有改变. 前段时间调研了一次代理相关的知识,简单整理一下分享之.如有错误,欢迎指正. 涉及 Proxy IP应用 原理/ ...
- HTTP2特性预览和抓包分析
背景 近年来,http网络请求量日益添加,以下是httparchive统计,从2012-11-01到2016-09-01的请求数量和传输大小的趋势图: 当前大部份客户端&服务端架构的应用程序, ...
- 抓包分析SSL/TLS连接建立过程【总结】
1.前言 最近在倒腾SSL方面的项目,之前只是虽然对SSL了解过,但是不够深入,正好有机会,认真学习一下.开始了解SSL的是从https开始的,自从百度支持https以后,如今全站https的趋势越来 ...
随机推荐
- 关于oracle的sqlplus的另一些小技巧
执行脚本的命令在上一节已经讲过,不再重复. sqlplus user/password@ip:port/servicename @/path/sqltest.sql; sqltest的内容及注释: - ...
- openssl生成证书链多级证书
操作系统CentOS6.6 注:windows版本的Openssl无法做这个实验,由于所有编译的window版本openssl没有对openssl目录重新定向,导致在windows下找不到pki目录 ...
- hdu1269(有向图强连通分量)
hdu1269 题意 判断对于任意两点是否都可以互相到达(判断有向图强连通分量个数是否为 1 ). 分析 Tarjan 算法实现. code #include<bits/stdc++.h> ...
- Linux命令之free
free [选项] 显示系统中未使用和使用的内存情况,包括物理内存.交换区内存(swap)和内核缓冲区内存.共享内存将被忽略. (1).选项 -b,-k,-m,-g 以Byte,KB,MB,GB为单位 ...
- intellij idea android错误: Missing styles. Is the correct theme chosen for this layout?
Missing styles. Is the correct theme chosen for this layout? Use the Theme combo box above the layou ...
- [BZOJ4367][IOI2014]Holiday(决策单调性+分治+主席树)
4367: [IOI2014]holiday假期 Time Limit: 20 Sec Memory Limit: 64 MBSubmit: 421 Solved: 128[Submit][Sta ...
- 洛谷 P3803 多项式乘法
题目背景 这是一道FFT模板题 题目描述 给定一个n次多项式F(x),和一个m次多项式G(x). 请求出F(x)和G(x)的卷积. 输入输出格式 输入格式: 第一行2个正整数n,m. 接下来一行n+1 ...
- 【最近公共祖先】【线段树】URAL - 2109 - Tourism on Mars
Few people know, but a long time ago a developed state existed on Mars. It consisted of n cities, nu ...
- vs生成命令和属性的宏
在vs属性页面中编辑后期生成事件... 下面是vs中宏的描述信息. http://i.cnblogs.com/EditPosts.aspx?opt=1 高级用法: 磨刀不误砍柴工——VS生成事件
- PhantomJS 基础及示例
腾讯云技术社区-掘金主页持续为大家呈现云计算技术文章,欢迎大家关注! 作者:link 概述 PhantomJS is a headless WebKit scriptable with a JavaS ...