【机器学习】BP神经网络实现手写数字识别
最近用python写了一个实现手写数字识别的BP神经网络,BP的推导到处都是,但是一动手才知道,会理论推导跟实现它是两回事。关于BP神经网络的实现网上有一些代码,可惜或多或少都有各种问题,在下手写了一份,连带着一些关于性能的分析也写在下面,希望对大家有所帮助。
加一些简单的说明,算不得理论推导,严格的理论推导还是要去看别的博客或书。
BP神经网络是一个有监督学习模型,是神经网络类算法中非常重要和典型的算法,三层神经网络的基本结构如下:
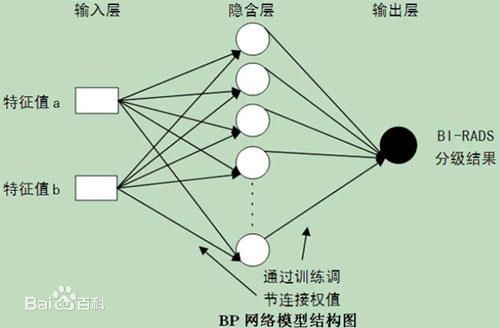
这是最简单的BP神经网络结构,其运行机理是,一个特征向量的各个分量按不同权重加权,再加一个常数项偏置,生成隐层各节点的值。隐层节点的值经过一个激活函数激活后,获得隐层激活值,隐层激活值仿照输入层到隐层的过程,加权再加偏置,获得输出层值,通过一个激活函数得到最后的输出。
上面的过程称为前向过程,是信息的流动过程。各层之间采用全连接方式,权向量初始化为随机向量,激活函数可使用值域为(0,1)的sigmoid函数,也可使用值域为(-1,1)的tanh函数,两个函数的求导都很方便。
BP神经网络的核心数据是权向量,经过初始化后,需要在训练数据的作用下一次次迭代更新权向量,直到权向量能够正确表达输入输出的映射关系为止。
权向量的更新是根据预测输出与真值的差来更新的,前面说过BP神经网络是一个有监督学习模型,对于一个特征向量,可以通过神经网络前向过程得到一个预测输出,而该特征向量的label又是已知的,二者之差就能表达预测与真实的偏差情况。这就是后向过程,后向过程是误差流动的过程。抛开具体的理论推导不谈,从编程来说,权值更新的后向过程分为两步。
第一步,为每个神经元计算偏差δ,δ是从后向前计算的,故称之为后向算法。对输出层来说,偏差是 act(预测值-真值),act为激活函数。对隐层而言,需要从输出层开始,逐层通过权值计算得到。确切的说,例如对上面的单隐层神经网络而言,隐层各神经元的δ就是输出层δ乘以对应的权值,如果输出层有多个神经元,则是各输出层神经元δ按连接的权值加权生成隐层的神经元δ。
第二步,更新权值,w=w+η*δ*v 其中η是学习率,是常数。v是要更新的权值输入端的数值,δ是要更新的权值输出端的数值。例如更新隐层第一个神经元到输出层的权值,则δ是第一步计算得到的输出层数值,v是该权值输入端的值,即隐层第一个神经元的激活值。同理如果更新输入层第一个单元到隐层第一个单元的权值,δ就是隐层第一个单元的值,而v是输入层第一个单元的值。
偏置可以看作“1”对各神经元加权产生的向量,因而其更新方式相当于v=1的更新,不再赘述。在编程中可以将1强行加入各层输入向量的末尾,从而不单独进行偏置更新,也可以不这样做,单独把偏置抽出来更新。下面的算法采用的是第二种方法。
OK,简单解释完了,下面介绍这个程序。
一、数据库
程序使用的数据库是mnist手写数字数据库,这个数据库我有两个版本,一个是别人做好的.mat格式,训练数据有60000条,每条是一个784维的向量,是一张28*28图片按从上到下从左到右向量化后的结果,60000条数据是随机的。测试数据有10000条吧好像,记不太清了。另一个版本是图片版的,按0~9把训练集和测试集分为10个文件夹,两个版本各有用处,后面会说到,本程序用的是第一个版本。第二个版本比较大,不好上传,第一个版本在https://github.com/MoyanZitto/BPNetwork/里可以找到。
二、程序结构
程序分四个部分,第一个部分数据读取,第二个部分是神经网络的配置,第三部分是神经网络的训练,第四部分是神经网络的测试,最后还有个神经网络的保存,保存效果很差,大概没有做优化的缘故,不过仔细按保存方法设置程序还是能读出来的,只关心神经网络的实现的同学无视就好。
三、代码和注释
# -*- coding: utf-8 -*-
#本程序由UESTC的BigMoyan完成,并供所有人免费参考学习,但任何对本程序的使用必须包含这条声明
import math
import numpy as np
import scipy.io as sio # 读入数据
################################################################################################
print "输入样本文件名(需放在程序目录下)"
filename = 'mnist_train.mat' # raw_input() # 换成raw_input()可自由输入文件名
sample = sio.loadmat(filename)
sample = sample["mnist_train"]
sample /= 256.0 # 特征向量归一化 print "输入标签文件名(需放在程序目录下)"
filename = 'mnist_train_labels.mat' # raw_input() # 换成raw_input()可自由输入文件名
label = sio.loadmat(filename)
label = label["mnist_train_labels"] ################################################################################################## # 神经网络配置
##################################################################################################
samp_num = len(sample) # 样本总数
inp_num = len(sample[0]) # 输入层节点数
out_num = 10 # 输出节点数
hid_num = 9 # 隐层节点数(经验公式)
w1 = 0.2*np.random.random((inp_num, hid_num))- 0.1 # 初始化输入层权矩阵
w2 = 0.2*np.random.random((hid_num, out_num))- 0.1 # 初始化隐层权矩阵
hid_offset = np.zeros(hid_num) # 隐层偏置向量
out_offset = np.zeros(out_num) # 输出层偏置向量
inp_lrate = 0.3 # 输入层权值学习率
hid_lrate = 0.3 # 隐层学权值习率
err_th = 0.01 # 学习误差门限 ################################################################################################### # 必要函数定义
###################################################################################################
def get_act(x):
act_vec = []
for i in x:
act_vec.append(1/(1+math.exp(-i)))
act_vec = np.array(act_vec)
return act_vec def get_err(e):
return 0.5*np.dot(e,e) ################################################################################################### # 训练——可使用err_th与get_err() 配合,提前结束训练过程
################################################################################################### for count in range(0, samp_num):
print count
t_label = np.zeros(out_num)
t_label[label[count]] = 1
#前向过程
hid_value = np.dot(sample[count], w1) + hid_offset # 隐层值
hid_act = get_act(hid_value) # 隐层激活值
out_value = np.dot(hid_act, w2) + out_offset # 输出层值
out_act = get_act(out_value) # 输出层激活值 #后向过程
e = t_label - out_act # 输出值与真值间的误差
out_delta = e * out_act * (1-out_act) # 输出层delta计算
hid_delta = hid_act * (1-hid_act) * np.dot(w2, out_delta) # 隐层delta计算
for i in range(0, out_num):
w2[:,i] += hid_lrate * out_delta[i] * hid_act # 更新隐层到输出层权向量
for i in range(0, hid_num):
w1[:,i] += inp_lrate * hid_delta[i] * sample[count] # 更新输出层到隐层的权向量 out_offset += hid_lrate * out_delta # 输出层偏置更新
hid_offset += inp_lrate * hid_delta ################################################################################################### # 测试网络
###################################################################################################
filename = 'mnist_test.mat' # raw_input() # 换成raw_input()可自由输入文件名
test = sio.loadmat(filename)
test_s = test["mnist_test"]
test_s /= 256.0 filename = 'mnist_test_labels.mat' # raw_input() # 换成raw_input()可自由输入文件名
testlabel = sio.loadmat(filename)
test_l = testlabel["mnist_test_labels"]
right = np.zeros(10)
numbers = np.zeros(10)
# 以上读入测试数据
# 统计测试数据中各个数字的数目
for i in test_l:
numbers[i] += 1 for count in range(len(test_s)):
hid_value = np.dot(test_s[count], w1) + hid_offset # 隐层值
hid_act = get_act(hid_value) # 隐层激活值
out_value = np.dot(hid_act, w2) + out_offset # 输出层值
out_act = get_act(out_value) # 输出层激活值
if np.argmax(out_act) == test_l[count]:
right[test_l[count]] += 1
print right
print numbers
result = right/numbers
sum = right.sum()
print result
print sum/len(test_s)
###################################################################################################
# 输出网络
###################################################################################################
Network = open("MyNetWork", 'w')
Network.write(str(inp_num))
Network.write('\n')
Network.write(str(hid_num))
Network.write('\n')
Network.write(str(out_num))
Network.write('\n')
for i in w1:
for j in i:
Network.write(str(j))
Network.write(' ')
Network.write('\n')
Network.write('\n') for i in w2:
for j in i:
Network.write(str(j))
Network.write(' ')
Network.write('\n')
Network.close()
四、几点分析和说明
1.基本上只要有numpy和scipy,把github上的数据拷下来和程序放在一个文件夹里,就可以运行了。为了处理其他数据,应该把数据读入部分注释掉的raw_input()取消注释,程序运行时手动输入文件名。
2.关于输入特征向量,简单的把像素点的值归一化以后作为输入的特征向量理论上是可行的,因为真正有用的信息如果是这个特征向量的一个子集的话,训练过程中网络会自动把这些有用的信息选出来(通过增大权重),然而事实上无用信息,也会对结果造成负面影响,因而各位可以自己做一个特征提取的程序优化特征,有助于提高判断准确率。我懒,就这么用吧。
3.关于隐层的层数和神经元节点数,隐层的层数这里只有一层,因为理论上三层神经网络可以完成任意多种的分类,实际上隐层的数目在1~2层为好,不要太多。隐层的神经元节点数是个神奇的存在,目前没有任何理论能给出最佳节点数,只有经验公式可用。这里用的经验公式是sqrt(输入节点数+输出节点数)+0~9之间的常数,也可以用log2(输入节点数),具体多少需要反复验证,这个经验公式还是有点靠谱的,至少数量级上没有太大问题。如果隐层节点数太多,程序一定会过拟合,正确率一定惨不忍睹(我曾经10%,相当于瞎猜)。
4.关于训练方法,本程序用的是在线学习,即来一个样本更新一次,这种方式的优点是更容易收敛的好,避免收敛到局部最优点上去。
5.学习率、误差门限和最大迭代次数,学习率决定了梯度下降时每步的步长,会影响收敛速度,同时学习率太大容易扯着蛋(划掉),容易在山谷处来回倒腾hit不到谷底,学习率太大容易掉进局部的小坑里出不来,也是一个需要仔细设置的量。误差门限本程序虽然设置了但是没有使用,最大迭代次数我连设置都没设置,这两个量的作用主要在提前结束训练,而因为我的程序连训练带测试跑一次也就20s,所以懒得提前结束训练。但在应用时还是应该设置一下的。
6.这个程序是最简单的BP神经网络,没有使用所谓动量因子加速收敛,也没有乱七八糟别的玩意,基本上就是原生的BP神经网络算法,代码注释都是中文而且写的很全,仔细阅读应该理解上并不难。推荐使用pycharm阅读和修改。
7.补充一下实验结果,表格行为不同的隐层神经元数目,列为不同学习率,内容都是overall的正确率,可见最佳神经元个数在15附近,最佳学习率在0.2附近。

以上,有问题欢迎评论提问。
【机器学习】BP神经网络实现手写数字识别的更多相关文章
- BP神经网络的手写数字识别
BP神经网络的手写数字识别 ANN 人工神经网络算法在实践中往往给人难以琢磨的印象,有句老话叫“出来混总是要还的”,大概是由于具有很强的非线性模拟和处理能力,因此作为代价上帝让它“黑盒”化了.作为一种 ...
- 利用c++编写bp神经网络实现手写数字识别详解
利用c++编写bp神经网络实现手写数字识别 写在前面 从大一入学开始,本菜菜就一直想学习一下神经网络算法,但由于时间和资源所限,一直未展开比较透彻的学习.大二下人工智能课的修习,给了我一个学习的契机. ...
- BP神经网络(手写数字识别)
1实验环境 实验环境:CPU i7-3770@3.40GHz,内存8G,windows10 64位操作系统 实现语言:python 实验数据:Mnist数据集 程序使用的数据库是mnist手写数字数据 ...
- TensorFlow卷积神经网络实现手写数字识别以及可视化
边学习边笔记 https://www.cnblogs.com/felixwang2/p/9190602.html # https://www.cnblogs.com/felixwang2/p/9190 ...
- TensorFlow.NET机器学习入门【5】采用神经网络实现手写数字识别(MNIST)
从这篇文章开始,终于要干点正儿八经的工作了,前面都是准备工作.这次我们要解决机器学习的经典问题,MNIST手写数字识别. 首先介绍一下数据集.请首先解压:TF_Net\Asset\mnist_png. ...
- 【机器学习】李宏毅机器学习-Keras-Demo-神经网络手写数字识别与调参
参考: 原视频:李宏毅机器学习-Keras-Demo 调参博文1:深度学习入门实践_十行搭建手写数字识别神经网络 调参博文2:手写数字识别---demo(有小错误) 代码链接: 编程环境: 操作系统: ...
- 第二节,TensorFlow 使用前馈神经网络实现手写数字识别
一 感知器 感知器学习笔记:https://blog.csdn.net/liyuanbhu/article/details/51622695 感知器(Perceptron)是二分类的线性分类模型,其输 ...
- 卷积神经网络CNN 手写数字识别
1. 知识点准备 在了解 CNN 网络神经之前有两个概念要理解,第一是二维图像上卷积的概念,第二是 pooling 的概念. a. 卷积 关于卷积的概念和细节可以参考这里,卷积运算有两个非常重要特性, ...
- 100天搞定机器学习|day39 Tensorflow Keras手写数字识别
提示:建议先看day36-38的内容 TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edge ...
随机推荐
- 关于document.write
document.write的用处 document.write是JavaScript中对document.open所开启的文档流(document stream操作的API方法,它能够直接在文档流中 ...
- hdu 1879 继续畅通工程
/************************************************************************/ /* hdu 1879 继续畅通工程 Time L ...
- IOS绘图
#import "ViewController.h" #import "DrawView.h" @interface ViewController () @pr ...
- IntellijIDEA 使用技巧
1:显示工具栏目 toolbar:view ->ToolBar 2:加载源码 new project ->选择java project ->选择源码所在目录 ->ok
- ExtJS实战 01——HelloWorld
前言 Extjs5的发布已经有些日子了,目前的最新稳定版本是Extjs5.1.0,我们可以在官方网站进行下载.不过笔者今天访问得到的是502Bad Gateway,原因可能是sencha的nigix没 ...
- 基于ArcGIS API for JavaScript的统计图表实现
感谢原作者分享:https://github.com/shevchenhe/ChartLayer,在使用的过程中,需要自己进行调试修改,主要还是_draw函数,不同的ArcGIS JS API函数有差 ...
- visual studio中创建单元测试
1 打开 工具--自定义 2 选择 上下文菜单--编辑器上下文菜单|代码窗口 3 在这里我们可以看到“创建单元测试”这个菜单了,将它移到运行测试菜单下面 4 关闭VS并重启 重启后再对着类名,点击右 ...
- Ubontu使用技巧
1. ctrl + alt + T => 打开命令行窗口 2. sudo su => 开启root权限 3. cd => 打开文件夹 4. cd "Program F ...
- Redis 一:安装篇
.安装环境,虚拟机 + centos6. PS::前提已经安装了yum的情况下 第一步:安装 mkdir /usr/redis 新建redis目录 cd /usr/redis 进入目录 wget ht ...
- c#读写注册表示例分享
c#读写注册表示例,示例中有详细注释. 代码: //写注册表RegistryKey regWrite;//往HKEY_CURRENT_USER主键里的Software子键下写一个名为“Test”的子键 ...