Hive知识
HIVEQL
CREATE DATABASE financials(创建数据库)
SHOW DATABASES(显示数据库)
SHOW TABLES IN 数据库(列出数据库的所有表)
SHOW DATABASES LIKE 'h.*';(显示类似h以后任意多个字符)
LOCATION '/MY/preferred/directory';(指定数据库存放的路径)
COMMENT '**';(添加一个说明表)
DESCRIBE DATABASE financials(显示finacials数据库的一些信息))
DESCRIBE EXTENDEN table(列出表table的详细属性))
WITH DBPROPERTIES(‘*’,‘*’,)(添加注释说明的信息)
USE financials(切换到某个数据库下)
DROP DATABASE financials;(删除数据库)
ALTER DATABASE financials (修改数据库)
外部表:
CREATE EXTERNAL TABLE stocks(创建外部表)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/data/stocks';
分区表:
CREATE TABLE employees()
PARTITIONED BY(country STRING,state STRING);
一种有效减少io量的手段
//显示分区为us的所有字分区
SHOW PARTITIONS employees PARTITION(country='US')
load data语句
LOAD DATA LOCAL INPATH '${env:HOME}/california-employees'
OVERWRITE INTO TABLE employees
PARTITION (country='us',state='CA');
Insert overwrite语句//把一个没有分区的表变成分区的表方式
INSERT OVERWRITE TABLE employees
PARTITION (country=‘us’,state=‘or’)
SELECT * FROM STAGED_employees se
WHERE se.cnty='us' AND se.st='or';
Dynamic Partition inserts动态分区表
INSERT OVERWRITE TABLE employees
PARTITION (country,state)
SELECT ...., se.cty, se.st
FROM staged_employees se
WHERE se.cnty='us';
Create table ...as select...
CREATE TABLE CA_employees
AS SELECT name,salary,address
FROM emplyees
WHERE se.state='CA' ;
导出数据:
INSERT OVERWRITE LOCAL DIRECTORY'/tmp/data'
SELECT name,salary,address
FROM employees
WHERE se.state='CA'
查询语句select


连接操作:
Hiveql支持大部分常见的关系代数连接方式(各种内连接,外连接,半连接)
连接是缓慢的操作
使用map-side joins来优化连接
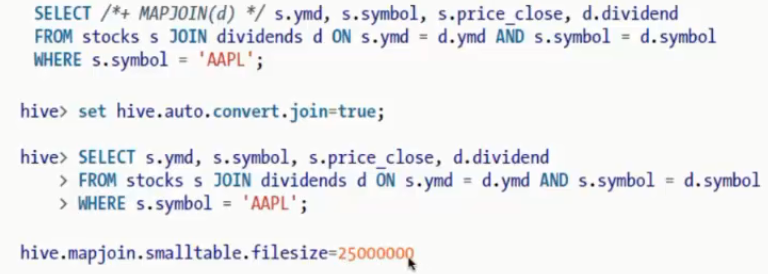
25000000=25m;
排序:

Hive知识的更多相关文章
- Hive知识汇总
两种Hive表 hive存储:数据+元数据 托管表(内部表) 创建表: hive> create table test2(id int,name String,tel String) > ...
- Hive 体系学习
Hive简介 Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并使用HQL作为查询接口.HDFS作为存储底层.MapReduce作为执行层,将HQL语句转换成M ...
- Trino总结
文章目录 1.Trino与Spark SQL的区别分析 2.Trino与Spark SQL解析过程对比 3.Trino基本概念 4.Trino架构 5.Trino SQL执行流程 6.Trino Ta ...
- Hive(一):架构及知识体系
Hive是一个基于Hadoop的数据仓库,最初由Facebook提供,使用HQL作为查询接口.HDFS作为存储底层.mapReduce作为执行层,设计目的是让SQL技能良好,但Java技能较弱的分析师 ...
- 《Programming Hive》读书笔记(两)Hive基础知识
<Programming Hive>读书笔记(两)Hive基础知识 :第一遍读是浏览.建立知识索引,由于有些知识不一定能用到,知道就好.感兴趣的部分能够多研究. 以后用的时候再具体看.并结 ...
- Hive 这些基础知识,你忘记了吗?
Hive 其实是一个客户端,类似于navcat.plsql 这种,不同的是Hive 是读取 HDFS 上的数据,作为离线查询使用,离线就意味着速度很慢,有可能跑一个任务需要几个小时甚至更长时间都有可能 ...
- Hive的基本知识与操作
Hive的基本知识与操作 目录 Hive的基本知识与操作 Hive的基本概念 为什么使用Hive? Hive的特点: Hive的优缺点: Hive应用场景 Hive架构 Client Metastor ...
- Hive基础知识梳理
Hive简介 Hive是什么 Hive是构建在Hadoop之上的数据仓库平台. Hive是一个SQL解析引擎,将SQL转译成MapReduce程序并在Hadoop上运行. Hive是HDFS的一个文件 ...
- Hive基础知识
一.产生背景 1.MapReudce编程繁琐,需要编写大量的代码 2.HDFS中存放的都是文件,在HDFS中没有Scheme的概念,无法用SQL进行快速的查询. 二.Hive的概念 Hive是基于Ha ...
随机推荐
- combobox下拉框
----------------------------------------------combobox下拉框----------------------------------------- f ...
- thymeleaf支持java8的日期实例
一.实体 @Entity public class Customer { @Id @GenericGenerator(name="generator",strategy = &qu ...
- JSP AJAX之Form序列化登录体验
package web; import java.io.IOException; import java.io.PrintWriter; import javax.servlet.ServletExc ...
- taotao购物车
功能分析: 1.在用户不登陆的情况下也可以使用购物车,那么就需要把购物车信息放入cookie中. 2.可以把商品信息,存放到pojo中,然后序列化成json存入cookie中. 3.取商品信息可以从c ...
- [poj 1743]差分+后缀数组
题目链接:http://poj.org/problem?id=1743 首先,musical theme只与前后位置的增减关系有关,而与绝对的数值无关,因此想到做一次差分. 然后对于差分后的数组,找到 ...
- URAL1277 Cops and Thieves(最小割)
Cops and Thieves Description: The Galaxy Police (Galaxpol) found out that a notorious gang of thieve ...
- nodejs npm insttall 带不带-g这个参数的区别
-g 中的g是global的意思所以带-g这个参数是全局安装,不带-g这个参数是本地安装. 在windows系统中全局安装的目录在:C:\Users\linsenq\AppData\Roaming\n ...
- Ubuntu1604 install netease-cloud music
Two issue: 1. There is no voice on my computer, and the system was mute and cannot unmute. eric@E641 ...
- css3中-moz、-ms、-webkit分别代表的意思
这三个分别是目前流行的三种浏览器的私有属性 -moz代表firefox浏览器私有属性 -ms代表ie浏览器私有属性(360浏览器是ie内核) -webkit代表safari.chrome私有属性 -o ...
- [Leetcode Week11]Kth Largest Element in an Array
Kth Largest Element in an Array 题解 题目来源:https://leetcode.com/problems/kth-largest-element-in-an-arra ...