论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息
论文标题:Self-supervised Graph Neural Networks without explicit negative sampling
论文作者:Zekarias T. Kefato, Sarunas Girdzijauskas
论文来源:2021, WWW
论文地址:download
论文代码:download
1 介绍
本文核心贡献:
- 使用孪生网络隐式实现对比学习;
- 本文提出四种特征增强方式(FA);
2 相关工作
Graph Neural Networks
GCN 和 GAT 存在的一个问题:GCN 和 GAT 需要全批处理训练,也就是说,整个图($H$)应该被加载到内存中,这使得它们是可转换的,不能扩展到大型网络。
3 方法
3.1 数据增强
拓扑结构:
- 基于随机游走的 $\text{PageRank}$ 算法:
$\boldsymbol{H}^{P P R}=\alpha(\boldsymbol{I}-(1-\alpha) \tilde{A})^{-1} \quad\quad\quad(2)$
$\boldsymbol{H}^{H K}=\exp \left(t A D^{-1}-t\right)\quad\quad\quad(3)$
其中 $\alpha$ 是心灵传输概率 ,$t$ 是扩散时间
- 基于 $\text{Katz}$ 指标的算法:
$\boldsymbol{H}^{k a t z}=(I-\beta \tilde{A})^{-1} \beta \tilde{A}\quad\quad\quad(4)$
Katz-index是一对节点之间所有路径集的加权和,路径根据其长度进行惩罚。衰减系数($\beta$)决定了处罚过程。
特征增强:
- Split:特征 $X$ 拆分成两部分 $\boldsymbol{X}=\boldsymbol{X}[:,: F / 2]$ 和 $\boldsymbol{X}^{\prime}=\boldsymbol{X}[:, F / 2:]$ ,然后分别用于生成两个视图。
- Standardize:特征矩阵进行 z-score standardization :
${\large X^{\prime}=\left(\frac{X^{T}-\bar{x}}{s}\right)^{T}} $
其中 $\bar{x} \in \mathbb{R}^{F \times 1}$ 和 $s \in \mathbb{R}^{F \times 1}$ 是与每个特征相关联的均值向量和标准差向量。
- Local Degree Profile (LDP):提出了一种基于节点局部度轮廓计算出的五个统计量的节点特征构建机制 $\mathbf{X}^{\prime} \in \mathbb{R}^{N \times 5}$ ,然后使用零填充 $X^{\prime} \in \mathbb{R}^{N \times F}$ 使其维度与 $X$ 一致。
- Paste:是一种功能增强技术,它简单地结合了 $X$ 和 LDP 功能,如增强功能 $\boldsymbol{X}^{\prime} \in \mathbb{R}^{N \times(F+5)}$。在这种情况下,在原始特征矩阵 $X$ 上应用了一个零填充,例如 $X \in \mathbb{R}^{N \times(F+5)}$ 。
3.2 框架
总体框架如下:
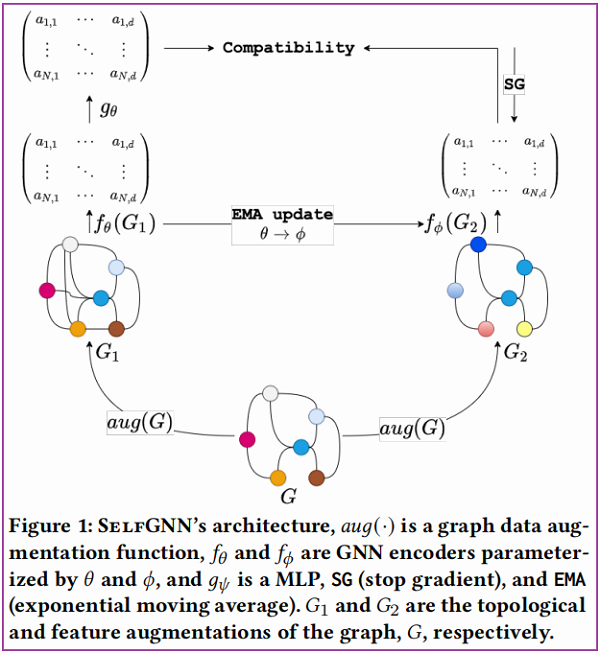
组成部分:
- 组件一:生成视图,$any(G)$ 是对原始图 $G$ 从拓扑或特征层面进行数据增强;
- 组件二:图自编码器 $f_{\theta}$ 和 $f_{\phi}$,一种堆叠架构,如 Figure 2 (A) 所示。概括为:$X_{1}=f_{\theta}\left(G_{1}\right)$, $X_{2}=f_{\phi}\left(G_{2}\right)$;
- 组件三:孪生网络(Siamese Network,用于评估两个输入样本的相似性)是一个投影头,类似$g_{\theta}$的架构,如 Figure 2 (B) 所示。本文在这发现使用这个投影头对性能没有多大提升,所以实际上并没有使用;
- 组件四:预测块(prediction block),对学生网络(左边)使用,这个预测块可以是 MLP ,也可以是 $g_{\theta}$,架构如Figure 2 (B) 所示。学生网络用于从教师网络(右边)中学到有用的信息;【$g_{\theta}\left(\mathbf{X}_{1}\right) \approx \mathbf{X}_{2}$】
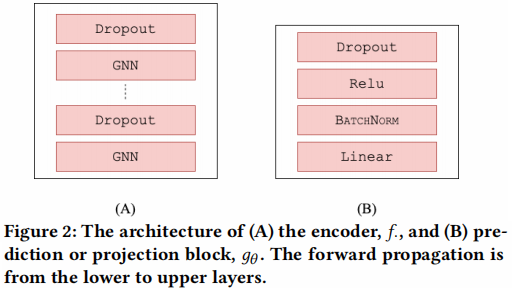
须知:
只对学生网络的参数通过梯度更新(SG),学生网络使用的损失函数如下:
$\mathcal{L}_{\theta}=2-2 \cdot \frac{\left\langle g_{\theta}\left(X_{1}\right), X_{2}\right\rangle}{\left\|g_{\theta}\left(X_{1}\right)\right\|_{F} \cdot\left\|X_{2}\right\|_{F}}\quad\quad\quad(5)$
教师网络参数通过学生网络使用指数移动平均(EMA,exponential moving average)进行更新。指数移动平均如下:
$\phi \leftarrow \tau \phi+(1-\tau) \theta\quad\quad\quad(6)$
这里 $\tau$ 是衰减率。
4 实验
数据集:
- citation networks (Cora, Citeseer, Pubmed)
- author collaboration networks (CS, Physics)
- co-purchased products network (Photo, Computers)
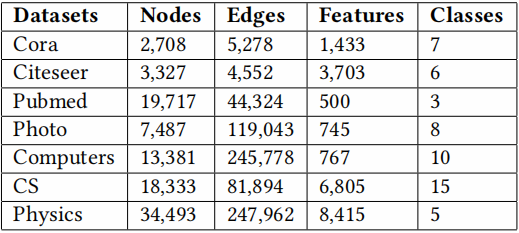
实验设置:
- 70/10/20–train/validation/test
- $\alpha=0.15$, $t=3$, $\beta=0.1$
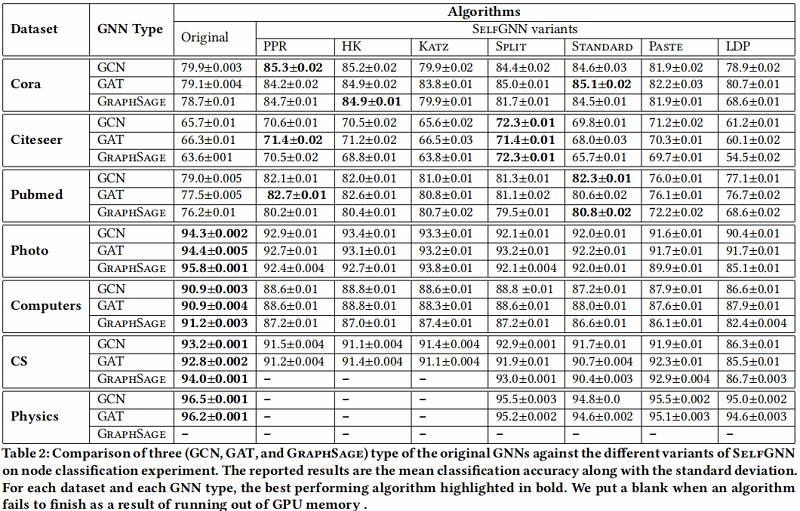
与原始 GNN 的比较:
对比 ClusterSelfGNN 性能的提升:

与自监督 GNN 的比较:

消融实验:
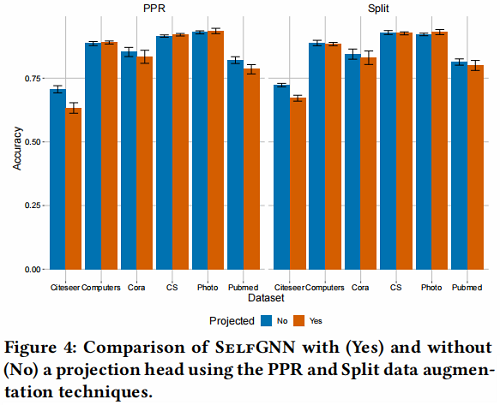
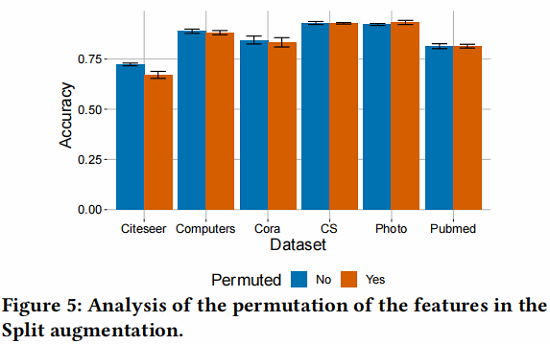
Split 策略的有效性:
5 结论
本研究提出了一种新的对比自监督方法SelfGNN,它不需要显式的对比项,负样本。虽然负样本对对比学习的成功至关重要,但我们采用了批量归一化,以引入隐式负样本。此外,我们还介绍了四种与拓扑节点特征增强技术一样有效的节点特征增强技术。我们使用7个真实数据集进行了广泛的实验,结果表明SelfGNN获得了与监督GNNs相当的性能,同时明显优于半监督和自监督方法。SelfGNN依赖于两个并行的gnn同时加载到内存中,这给大型网络造成了一个主要的瓶颈。虽然本研究提出了基于聚类的改进,但需要做仔细和有原则的工作来适当地解决这个问题。这是我们未来工作的目标。
相关论文
论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》的更多相关文章
- 论文解读二代GCN《Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering》
Paper Information Title:Convolutional Neural Networks on Graphs with Fast Localized Spectral Filteri ...
- Deep Learning 论文解读——Session-based Recommendations with Recurrent Neural Networks
博客地址:http://www.cnblogs.com/daniel-D/p/5602254.html 新浪微博:http://weibo.com/u/2786597434 欢迎多多交流~ Main ...
- 论文解读(DAGNN)《Towards Deeper Graph Neural Networks》
论文信息 论文标题:Towards Deeper Graph Neural Networks论文作者:Meng Liu, Hongyang Gao, Shuiwang Ji论文来源:2020, KDD ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(LA-GNN)《Local Augmentation for Graph Neural Networks》
论文信息 论文标题:Local Augmentation for Graph Neural Networks论文作者:Songtao Liu, Hanze Dong, Lanqing Li, Ting ...
- 论文解读(GraphSMOTE)《GraphSMOTE: Imbalanced Node Classification on Graphs with Graph Neural Networks》
论文信息 论文标题:GraphSMOTE: Imbalanced Node Classification on Graphs with Graph Neural Networks论文作者:Tianxi ...
- 论文解读(PPNP)《Predict then Propagate: Graph Neural Networks meet Personalized PageRank》
论文信息 论文标题:Predict then Propagate: Graph Neural Networks meet Personalized PageRank论文作者:Johannes Gast ...
- 论文解读(soft-mask GNN)《Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks》
论文信息 论文标题:Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks论文作者:Mingqi Yang, Ya ...
- 论文解读(ChebyGIN)《Understanding Attention and Generalization in Graph Neural Networks》
论文信息 论文标题:Understanding Attention and Generalization in Graph Neural Networks论文作者:Boris Knyazev, Gra ...
随机推荐
- metinfo 6.0 任意文件读取漏洞
一. 启动环境 1.双击运行桌面phpstudy.exe软件 2.点击启动按钮,启动服务器环境 二.代码审计 1.双击启动桌面Seay源代码审计系统软件 2.点击新建项目按钮,弹出对画框中选择(C:\ ...
- ubuntu忘记密码,用root修改Ubuntu密码
今天突发奇想,想改一下ubuntu的用户名,仅仅修改了/etc/passwd中的用户名. 改完后没有用命令修改密码,直接reboot了. 结果悲剧了,登不进去了. 赶紧百度一下,结果发现,本宝宝看不懂 ...
- docker知识点扫盲
最近给部门同事培训docker相关的东西,把我的培训内容总结下,发到博客园上,和大家一起分享.我的培训思路是这样的 首先讲解docker的安装.然后讲下docker的基本的原理,最后讲下docker的 ...
- 为什么使用 Executor 框架比使用应用创建和管理线程好?
为什么要使用 Executor 线程池框架 1.每次执行任务创建线程 new Thread()比较消耗性能,创建一个线程是比较耗 时.耗资源的. 2.调用 new Thread()创建的线程缺乏管理, ...
- @Qualifier 注解 ?
当有多个相同类型的 bean 却只有一个需要自动装配时,将@Qualifier 注解和 @Autowire 注解结合使用以消除这种混淆,指定需要装配的确切的 bean.
- Redis String Type
Redis字符串的操作命令和对应的api如下: set [key] [value] JedisAPI:public String set(final String key, final String ...
- Spring 应用程序有哪些不同组件?
Spring 应用一般有以下组件:接口 - 定义功能.Bean 类 - 它包含属性,setter 和 getter 方法,函数等.Spring 面向切面编程(AOP) - 提供面向切面编程的功能.Be ...
- 图灵机器人 V1 和 V2 接入方法
API1.0使用方法: import requests import json import yuyinhecheng as hc def Tuling(words): Tuling_API_ ...
- C语言之开发流程(知识点7)
一.C程序的运行步骤: 1.编辑:进入C语言编译系统,建立源程序文件,扩展名为"c"或"cpp",编辑并修改.保存源程序. 2.编译:计算机不能识别和执行高级语 ...
- 我常用的插件之“Mybatis Log plugin”sql日志格式转化
前言 今天重新装了IDEA2020,顺带重装了一些插件,毕竟这些插件都是习惯一直在用,其中一款就是Mybatis Log plugin,按照往常的思路,在IDEA插件市场搜索安装,艹,眼睛一瞟,竟然收 ...