Python 懂车帝口碑分爬虫
| 本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删! |
Python 懂车帝口碑分爬虫
需求
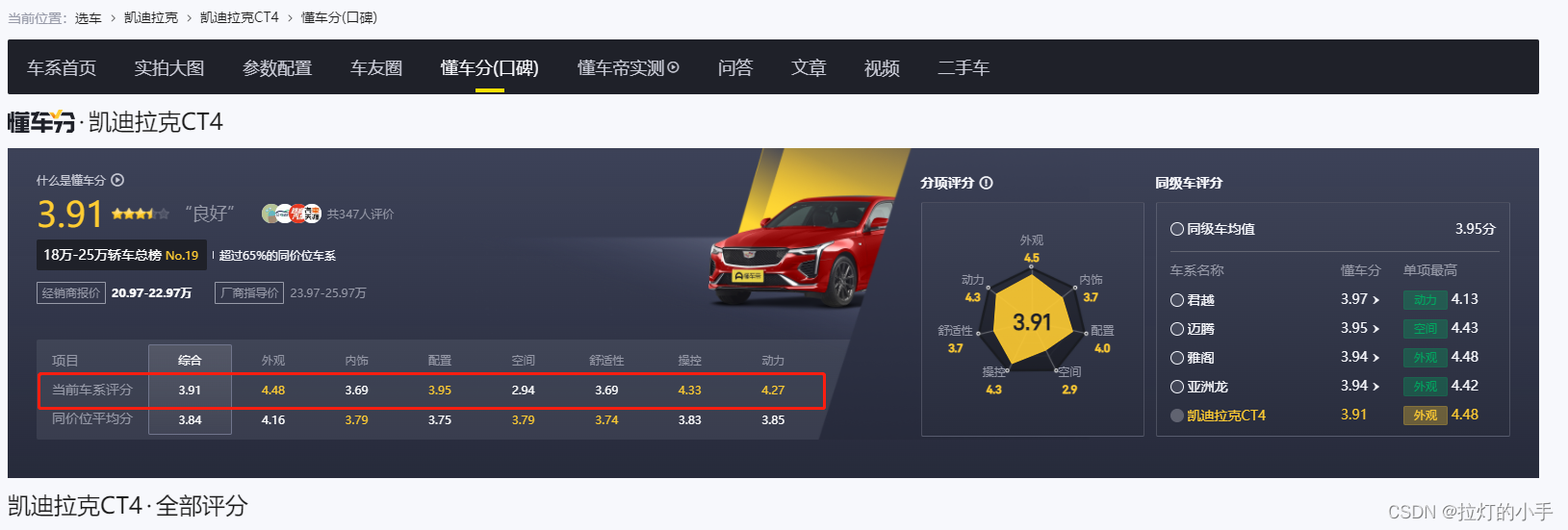
懂车帝全系车型懂车分(口碑)页面中的详细车系评分数据
操作环境
- win10
- Google nexus5x(root)
- Python3.9
- Charles
需求分析
先来web端试下能否找到需要的数据接口,随便找个车型打开口碑页面F12查看Network
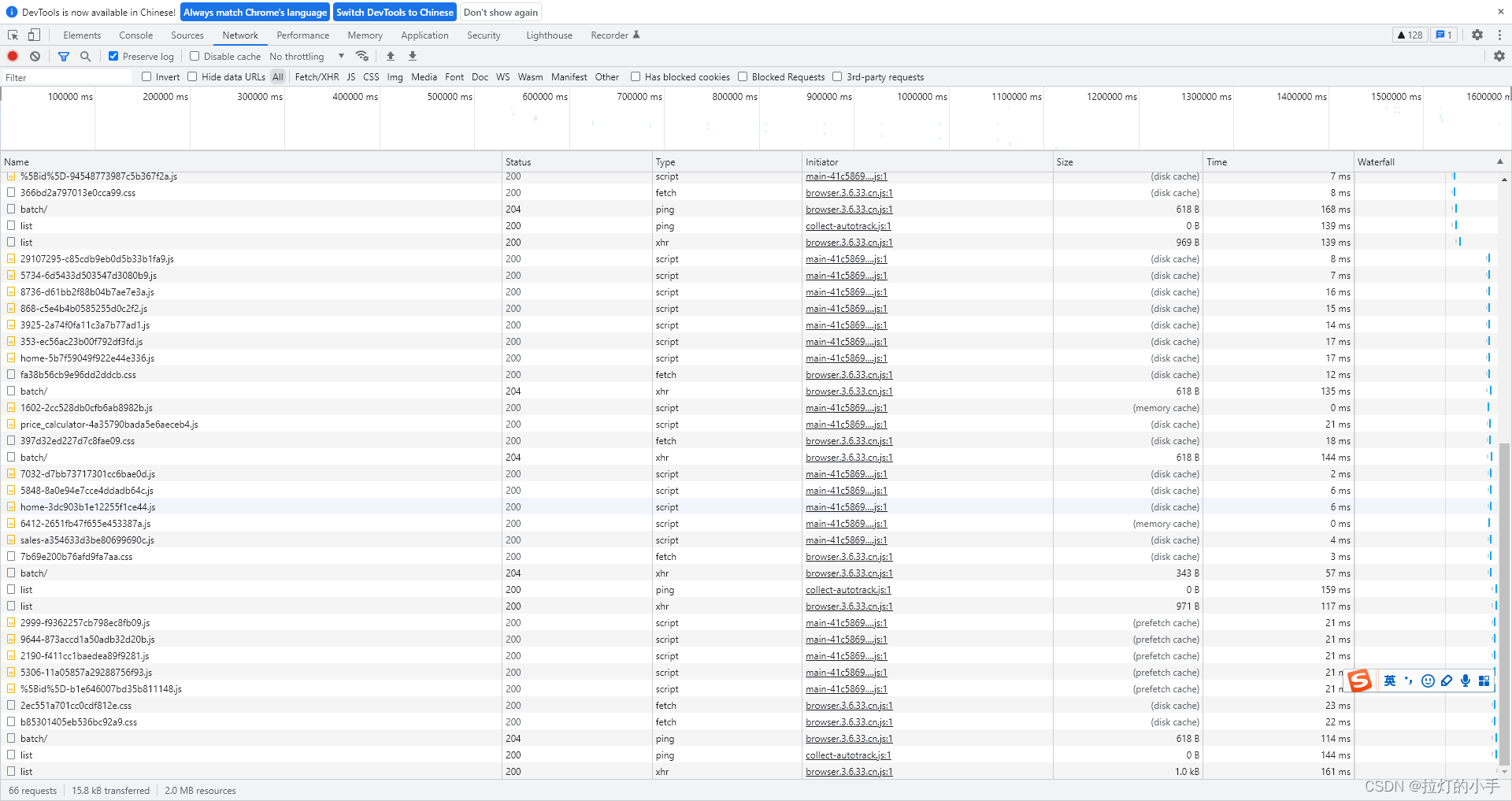
根据页面关键字先搜索一波
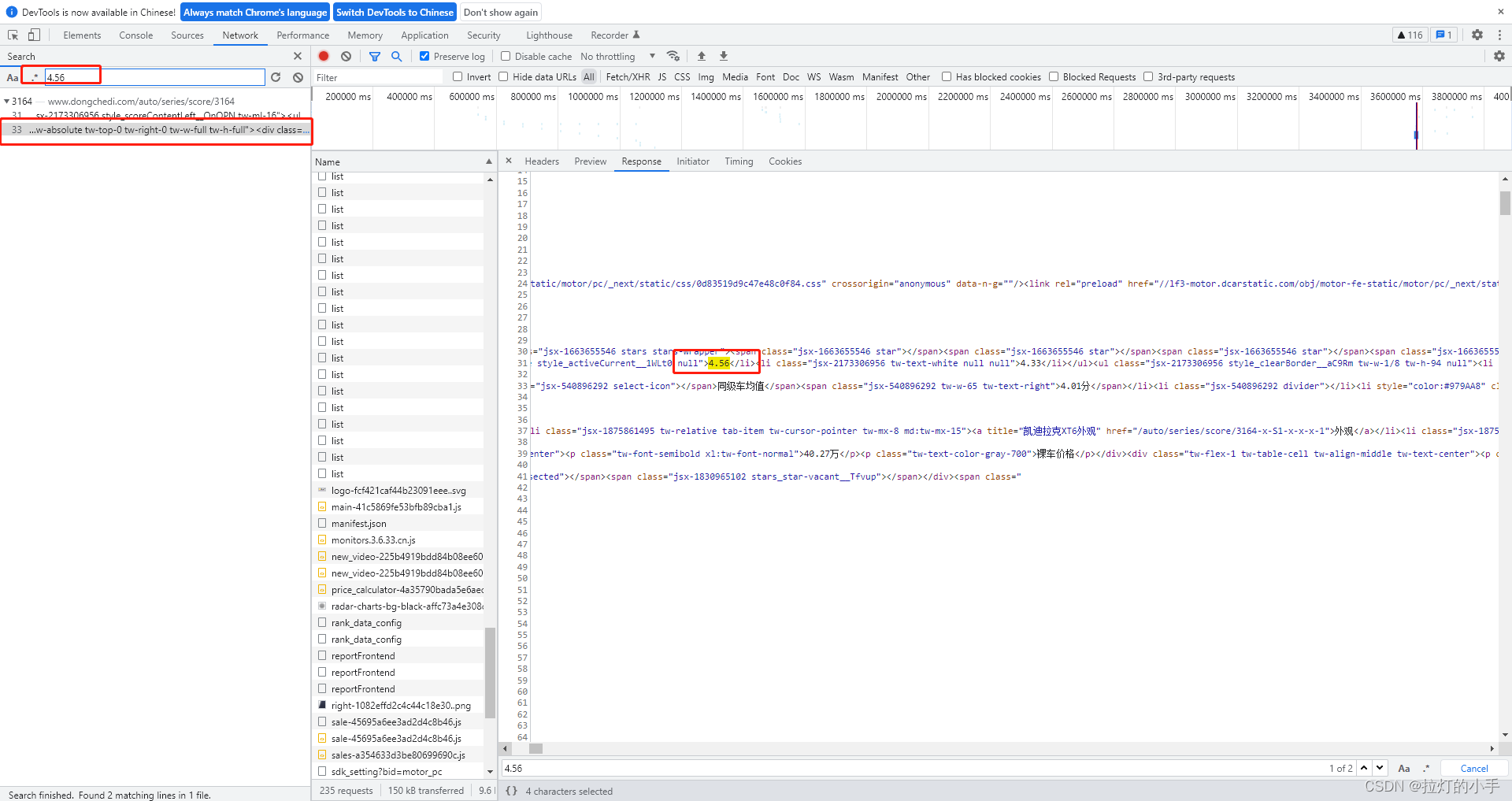
只在页面的标签中找到了数据,没有发现有明显的数据接口,其实用charles抓包的时候发现一个疑似的js好像数据是通过这个js加载出来的,打开看了一下数据相当混乱,暂且先放一边,先从APP分析一波看能否直接拿到数据接口
PS:手机环境、抓包环境的配置在这不在赘述,有兴趣的可参考之前的文章 APP抓包环境配置
下载懂车帝APP,并安装至手机

手机开启Postern,pc打开charles
至此抓包工作准备完成,打开懂车帝APP,随便找个车型进入懂车分页面
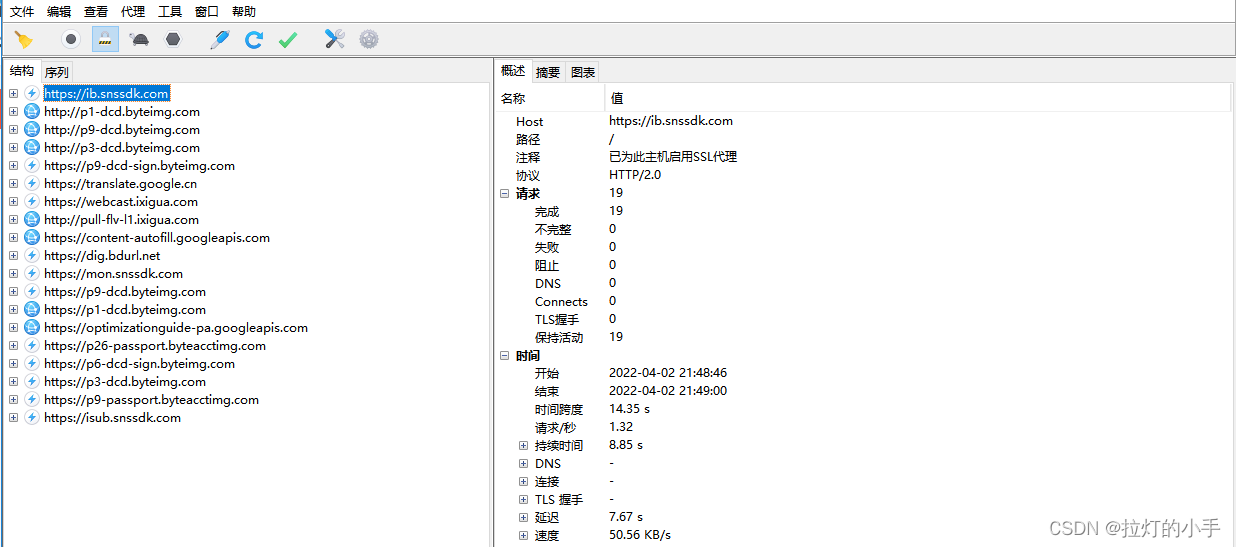
拿到加载的数据包,和web一样先搜索一波,看能否直接找到需要的数据
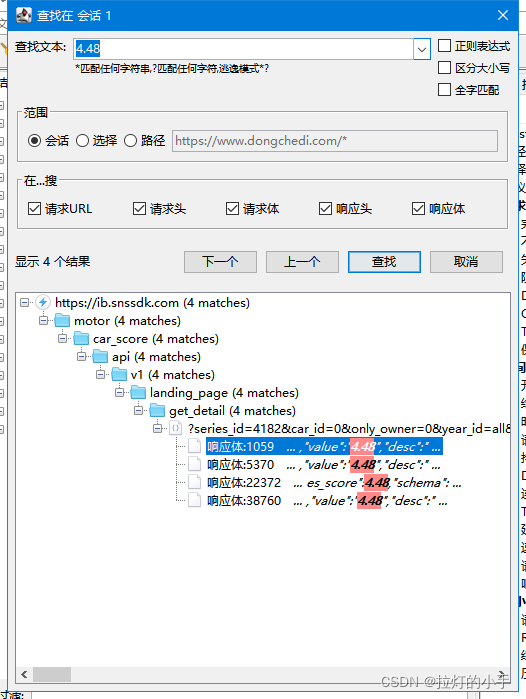
直接匹配到了多个结果,看接口是同一个接口返回的数据,双击点进去看一下详细数据
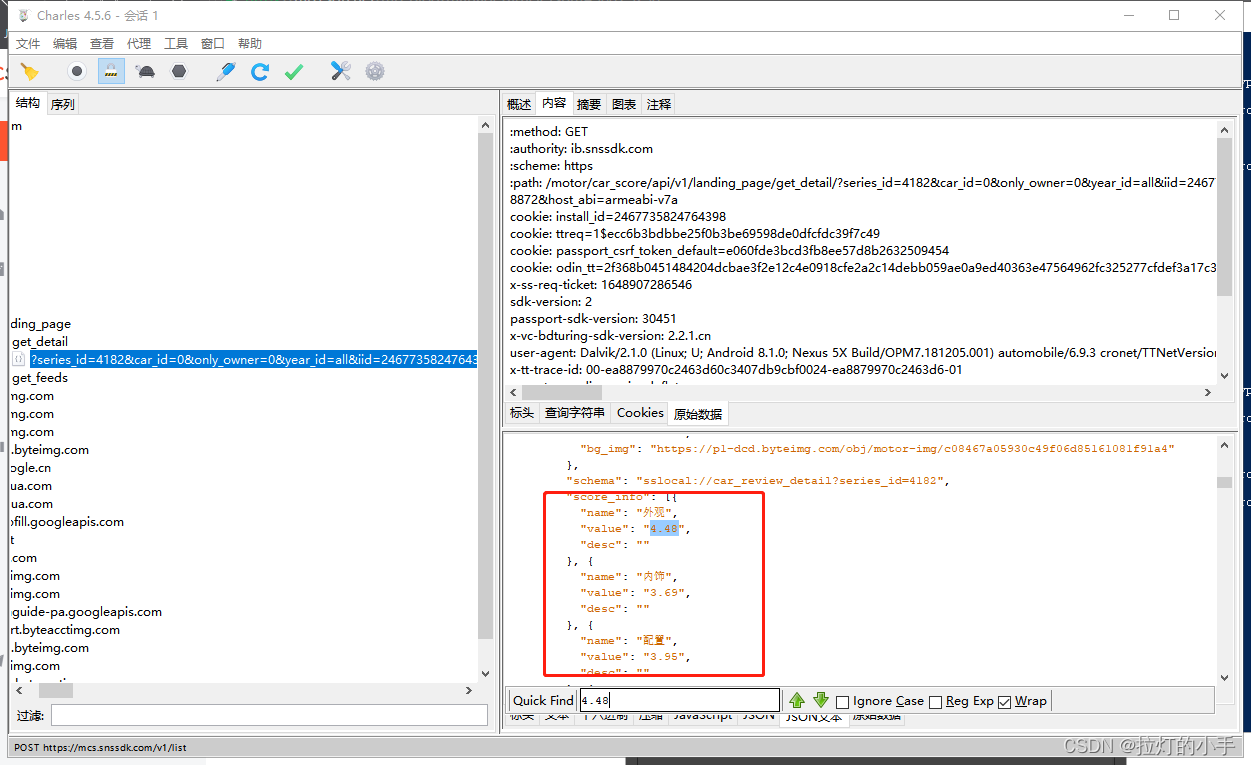

看数据结构和具体的数值和页面中的数据很像,Charles界面太小,将数据拷贝至网页中解析,方便分析,分享一个常用的json数据在线解析网站
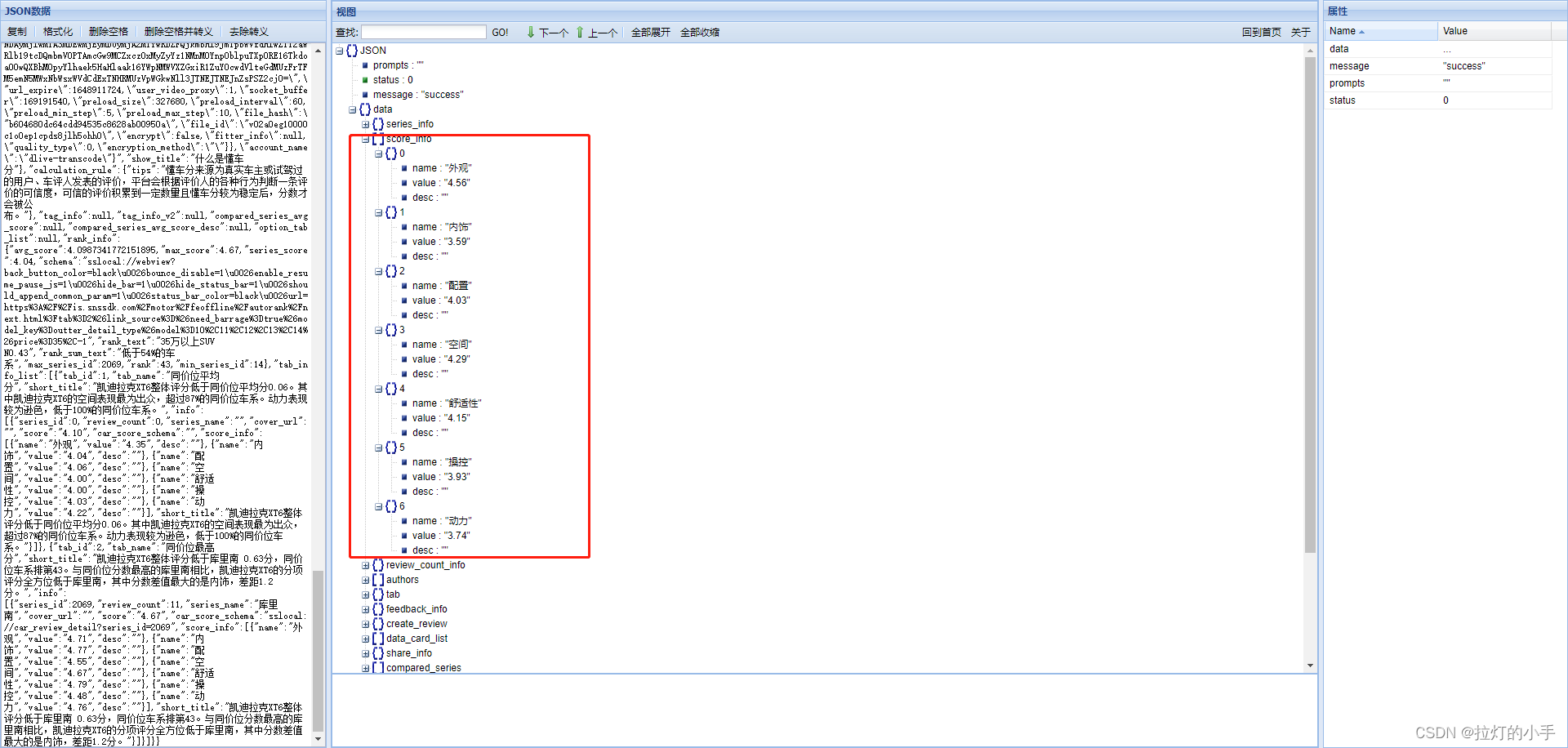
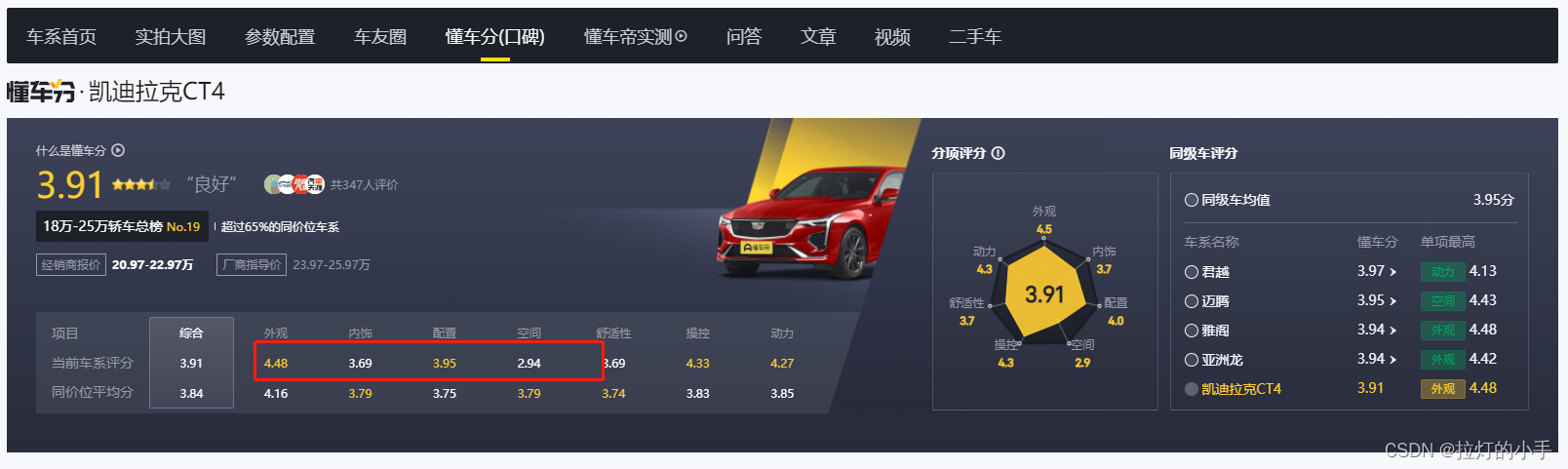
经过仔细分析,APP中展示的数据小数点第二位是四舍五入的,从下图的web页面中可以看出,数据是一样的,成功拿到数据接口!
口碑分数据接口:
https://*******/get_detail/?series_id=4182&car_id=0&only_owner=0&year_id=all&iid=2467735824764398&device_id=40011211486215&ac=wifi&channel=dcd-yd-11zh-and-74&aid=36&app_name=automobile&version_code=693&version_name=6.9.3&device_platform=android&os=android&ab_client=a1%2Cc2%2Ce1%2Cf2%2Cg2%2Cf7&ab_group=3167590%2C3577236%2C3333988&ssmix=a&device_type=Nexus+5X&device_brand=google&language=zh&os_api=27&os_version=8.1.0&manifest_version_code=693&resolution=1080*1794&dpi=420&update_version_code=6931&_rticket=1648907286543&cdid=f3163204-7faf-45d7-89c4-e82215c3216c&city_name=%E8%81%8A%E5%9F%8E&gps_city_name=%E8%81%8A%E5%9F%8E&selected_city_name&rom_version=27&longi_lati_type=1&longi_lati_time=1648907102913&content_sort_mode=0&total_memory=1.77&cpu_name=Qualcomm+Technologies%2C+Inc+MSM8992&overall_score=4.873&cpu_score=4.8872&host_abi=
对!你没看错,就是这么长,验证一下数据接口,在网页中直接请求一下这个url

这儿推荐安装一个网页json可视化的插件,这儿偷懒没装,在线解析了一下json数据,和Charles抓到的数据是一样,经过分析得知: series_id是车系id,修改此参数即可
获取全部车系id
获取车系id就很简单了,先拿到品牌id然后根据品牌id请求车系信息,注意这是一个post接口
def get_series(self, brand_id):
"""
获取品牌所有车系
brand_id:品牌id
"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
param = {
'offset': 0,
'limit': 1000,
'is_refresh': 1,
'city_name': '北京',
'brand': brand_id
}
response = requests.post(url=url, data=param, headers=headers)
rep_json = json.loads(response.text)
# print(response.text)
if rep_json['status'] == 'success':
return rep_json['data']['series']
else:
raise Exception("get car series has exception!")

获取车系口碑分
实际的运行过程中,发现一个问题,不同的城市同价位平均分是不一样的,所以需要指定城市获取
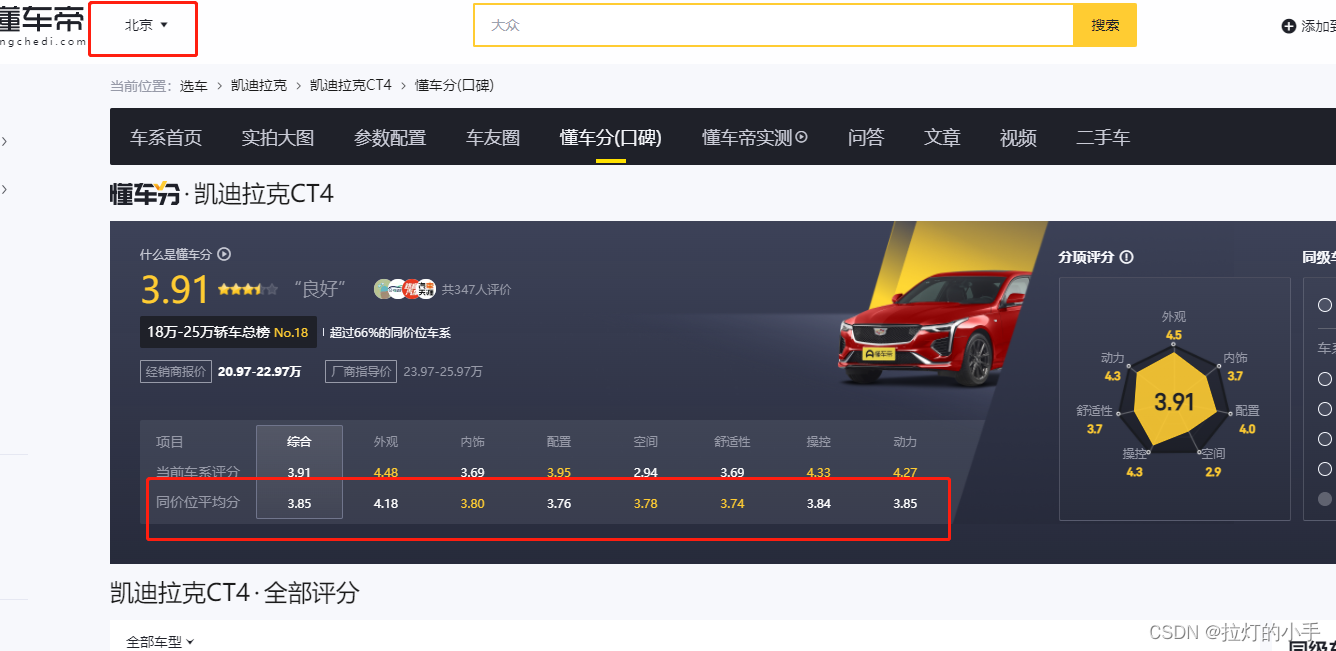
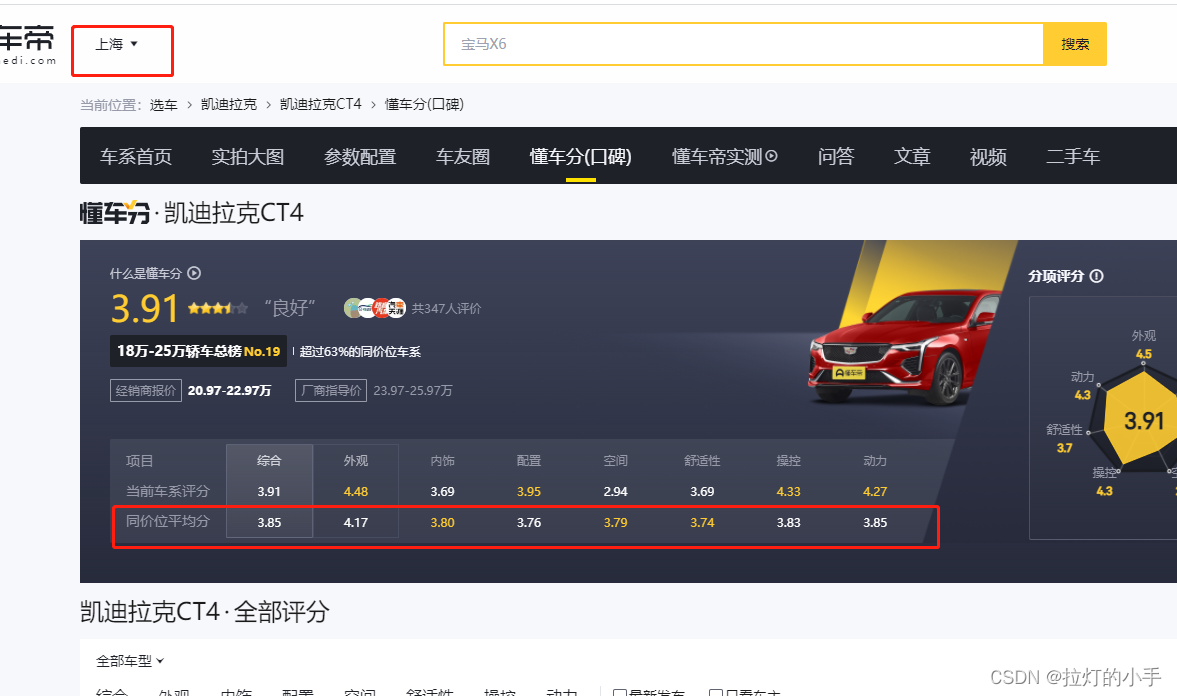
def get_score(self, series_id, city):
"""
获取车系口碑分
series_id: 车系id
"""
response = self._parse_url(url).json()
# 当前车系评分 综合
series_info = list()
series_info.append(response.get('data').get('series_info').get('score'))
# 当前车系评分 详细
score_info = response.get('data').get('score_info')
if not score_info:
return ['-'] * 16
score = series_info + [i.get('value') for i in score_info]
# 同价位平均分 综合
tab_info_score = list()
if response.get('data').get('tab_info_list'):
tab_info_score.append(response.get('data').get('tab_info_list')[0].get('info')[0].get('score'))
tab_info_score_info = response.get('data').get('tab_info_list')[0].get('info')[0].get('score_info')
tab_info_score_info = tab_info_score + [i.get('value') for i in tab_info_score_info]
else:
tab_info_score_info = ['-'] * 8
data = score + tab_info_score_info
return data
运行结果
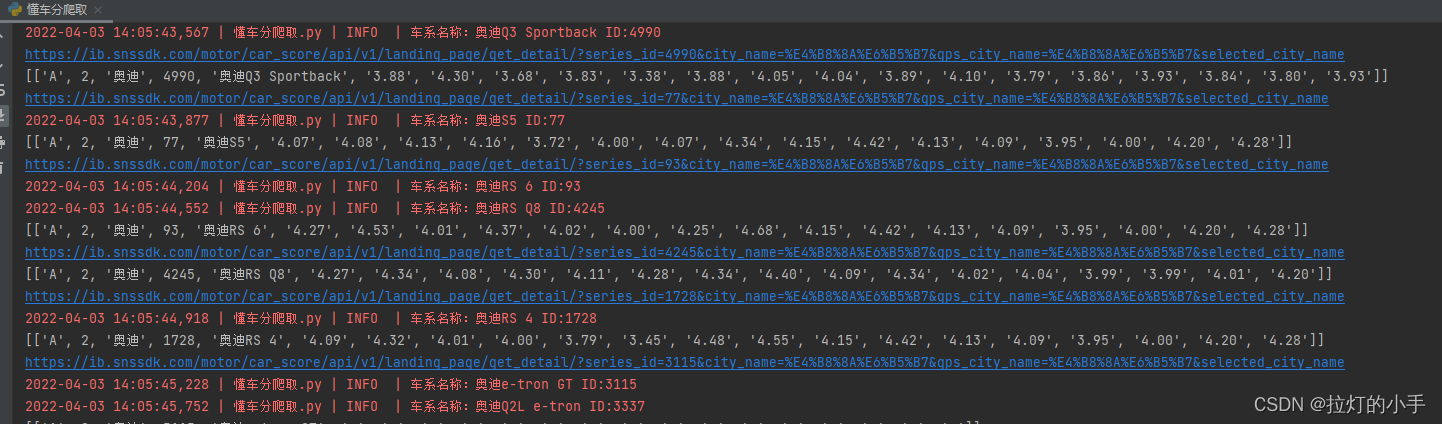
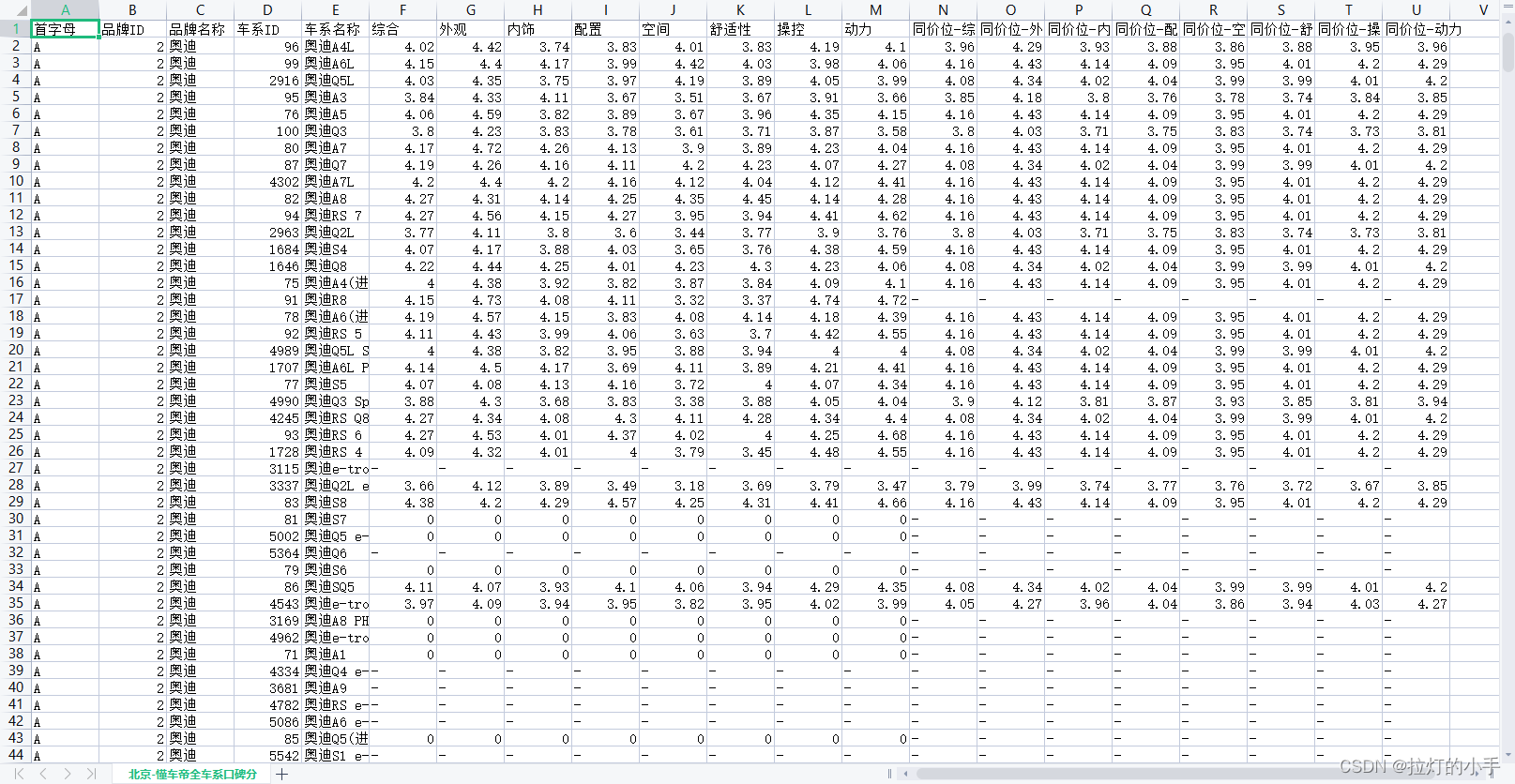
资源下载
https://download.csdn.net/download/qq_38154948/85072078
| 本文仅供学习交流使用,如侵立删! |
Python 懂车帝口碑分爬虫的更多相关文章
- 【原创】Python 懂车帝口碑爬虫
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! 懂车帝综合口碑 需求 操作环境 win1 ...
- Python 懂车帝综合口碑数据
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! Python 懂车帝综合口碑数据 需求 ...
- Python 懂车帝全车系销量排行榜
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! Python 懂车帝全车系销量排行榜 需 ...
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
- 【python】一个简单的贪婪爬虫
这个爬虫的作用是,对于一个给定的url,查找页面里面所有的url连接并依次贪婪爬取 主要需要注意的地方: 1.lxml.html.iterlinks() 可以实现对页面所有url的查找 2.获取页面 ...
- Python爬取mc皮肤【爬虫项目】
首先,找到一个皮肤网站,其中一个著名的皮肤网站就是 https://littleskin.cn .进入网站,我们就会见到一堆皮肤,这就是今天我们要爬的皮肤.给各位分享一下代码. PS:另外很多人在学习 ...
- python 全栈开发,Day137(爬虫系列之第4章-scrapy框架)
一.scrapy框架简介 1. 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前S ...
随机推荐
- ajax与python后端交互
目录 ajax简介 前后端传输数据编码格式 ajax发送json格式数据 ajax携带文件数据 回调机制处理策略 ajax简介 ajax可以在页面不刷新的情况下可以与后端进行数据交互,异步提交,局部刷 ...
- python3在使用类基础时,遇到错误TypeError: module.**init**() takes at most 2 arguments (3 given)
python3在使用类基础时,遇到错误TypeError: module.init() takes at most 2 arguments (3 given) 1.原因:直接导入的py文件,而没有导入 ...
- 管理订单状态,该上状态机吗?轻量级状态机COLA StateMachine保姆级入门教程
前言 在平常的后端项目开发中,状态机模式的使用其实没有大家想象中那么常见,笔者之前由于不在电商领域工作,很少在业务代码中用状态机来管理各种状态,一般都是手动get/set状态值.去年笔者进入了电商领域 ...
- 2021.03.06【NOIP提高B组】模拟 总结
T1 看起来十分复杂,打表后发现答案是 \(n*m\mod p\) 具体的证明... 原式的物理意义,就是从坐标原点(0,0),用每一种合法的斜率, 穿过坐标[1 ~ n , 1 ~ m]的方阵中的整 ...
- 修改SQL Server用户的密码-使用SSMS
更新日志 2022年6月13日 发布文章. 2022年5月21日 开始文章. 打开软件Microsoft SQL Server Management Studio(简写:SSMS). 登录连接具体的数 ...
- 【Redis】ziplist压缩列表
压缩列表 压缩列表是列表和哈希表的底层实现之一: 如果一个列表只有少量数据,并且数据类型是整数或者比较短的字符串,redis底层就会使用压缩列表实现. 如果一个哈希表只有少量键值对,并且每个键值对的键 ...
- 修改jupyter notebook文件保存目录
我们安装好jupyter notebook之后,打开的默认地址是在C盘,文件保存的文字也是C盘,会有其它乱七八糟的东西放一起,很不方便,所以可以换一个保存位置 1. 首先,在要存放文件的位置新建文件夹 ...
- 十分钟快速实战Three.js
前言 本文不会对Three.js几何体.材质.相机.模型.光源等概念详细讲解,会首先分成几个模块给大家快速演示一盒小案例.大家可以根据这几个模块快速了解Three.js的无限魅力.学习 我们会使用Th ...
- NC23053 月月查华华的手机
NC23053 月月查华华的手机 题目 题目描述 月月和华华一起去吃饭了.期间华华有事出去了一会儿,没有带手机.月月出于人类最单纯的好奇心,打开了华华的手机.哇,她看到了一片的QQ推荐好友,似乎华华还 ...
- React key究竟有什么作用?深入源码不背概念,五个问题刷新你对于key的认知
壹 ❀ 引 我在[react]什么是fiber?fiber解决了什么问题?从源码角度深入了解fiber运行机制与diff执行一文中介绍了react对于fiber处理的协调与提交两个阶段,而在介绍协调时 ...