Python代码相似度计算(基于AST和SW算法)
代码相似度计算将基于AST和Smith-Waterman算法
AST (抽象语法树)
AST即Abstract Syntax Trees,是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构。一般的,在源代码的翻译和编译过程中,语法分析器创建出分析树,然后从分析树生成AST。
生成AST
使用Python中的ast库来生成源代码的AST
最简单的例子:
import ast
root_node = ast.parse("print('hello world')")
print(root_node)
输出: <_ast.Module object at 0x7f702f13a550>
这里返回一个object,并不能直观地看到这个树状结构,使用astpretty就能清晰地输出这棵树。
import ast
import astpretty
root_node = ast.parse("print('hello world')")
astpretty.pprint(root_node)
输出
Module(
body=[
Expr(
lineno=1,
col_offset=0,
value=Call(
lineno=1,
col_offset=0,
func=Name(lineno=1, col_offset=0, id='print', ctx=Load()),
args=[Str(lineno=1, col_offset=6, s='hello world')],
keywords=[],
),
),
],
)
现在可以更直观一点的看到这棵树的结构
AST图像
上述程序打印出来的AST虽然已经比较清晰了,但生成一个图像会更加清晰。
测试代码 test.py:
def func():
a = 2 + 3 * 4 + 5
return a
使用instaviz库可以查看AST结构图
import ast
import astpretty
import instaviz
from test import func
code = open("./test.py", "r").read()
code_node = ast.parse(code)
astpretty.pprint(code_node)
instaviz.show(func)
打印出来的AST结构
Module(
body=[
FunctionDef(
lineno=1,
col_offset=0,
name='func',
args=arguments(args=[], vararg=None, kwonlyargs=[], kw_defaults=[], kwarg=None, defaults=[]),
body=[
Assign(
lineno=2,
col_offset=4,
targets=[Name(lineno=2, col_offset=4, id='a', ctx=Store())],
value=BinOp(
lineno=2,
col_offset=18,
left=BinOp(
lineno=2,
col_offset=8,
left=Num(lineno=2, col_offset=8, n=2),
op=Add(),
right=BinOp(
lineno=2,
col_offset=12,
left=Num(lineno=2, col_offset=12, n=3),
op=Mult(),
right=Num(lineno=2, col_offset=16, n=4),
),
),
op=Add(),
right=Num(lineno=2, col_offset=20, n=5),
),
),
Return(
lineno=3,
col_offset=4,
value=Name(lineno=3, col_offset=11, id='a', ctx=Load()),
),
],
decorator_list=[],
returns=None,
),
],
)
Bottle v0.12.21 server starting up (using WSGIRefServer())...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.
访问localhost:8080可以看到生成的AST图
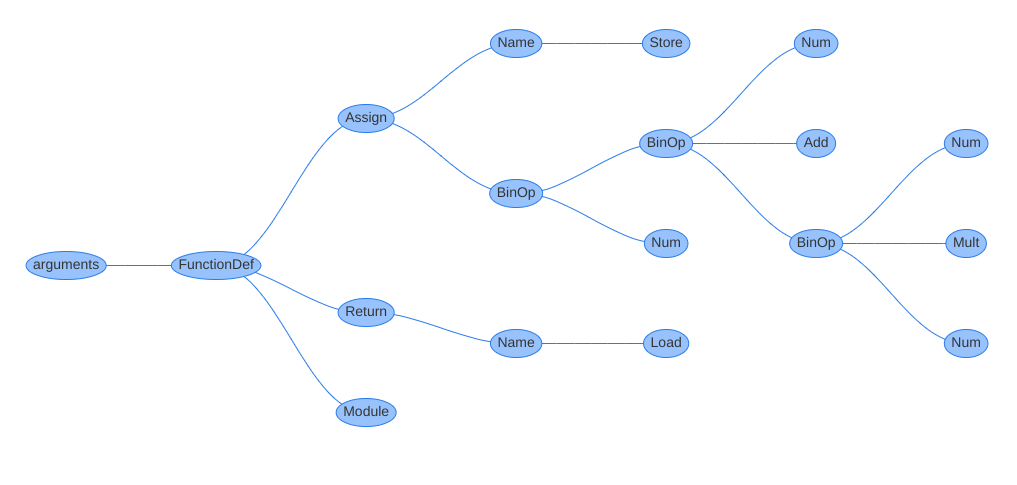
遍历AST
将使用ast库中的NodeVisitor类进行对树的遍历,如下是定义:
class NodeVisitor(object):
"""
A node visitor base class that walks the abstract syntax tree and calls a
visitor function for every node found. This function may return a value
which is forwarded by the `visit` method.
This class is meant to be subclassed, with the subclass adding visitor
methods.
Per default the visitor functions for the nodes are ``'visit_'`` +
class name of the node. So a `TryFinally` node visit function would
be `visit_TryFinally`. This behavior can be changed by overriding
the `visit` method. If no visitor function exists for a node
(return value `None`) the `generic_visit` visitor is used instead.
Don't use the `NodeVisitor` if you want to apply changes to nodes during
traversing. For this a special visitor exists (`NodeTransformer`) that
allows modifications.
"""
def visit(self, node):
"""Visit a node."""
method = 'visit_' + node.__class__.__name__
visitor = getattr(self, method, self.generic_visit)
return visitor(node)
def generic_visit(self, node):
"""Called if no explicit visitor function exists for a node."""
for field, value in iter_fields(node):
if isinstance(value, list):
for item in value:
if isinstance(item, AST):
self.visit(item)
elif isinstance(value, AST):
self.visit(value)
上述代码递归地对节点进行访问,isinstance() 函数能判断一个对象是否是一个已知的类型,在generic_visit函数中,使用isinstance判断是列表还是AST,如果是列表则对其再进行遍历,如果是AST,则使用visit函数对其进行遍历。
拿上面astpretty.pprint举例,最外层的Module是AST,那么对其使用visit方法,其中的有些field对应的value,既不是list也不是AST,所以不做操作。args这个field的value是arguments,类型是AST,所以直接visit,body的value是列表,所以对其进行遍历,以此类推。
示例代码
import ast
import astpretty
class CodeVisitor(ast.NodeVisitor):
def __init__(self):
self.seq = []
def generic_visit(self, node):
ast.NodeVisitor.generic_visit(self, node)
self.seq.append(type(node).__name__)
def visit_FunctionDef(self, node):
ast.NodeVisitor.generic_visit(self, node)
self.seq.append(type(node).__name__)
def visit_Assign(self, node):
self.seq.append(type(node).__name__)
code = open("./hello.py", "r").read()
code_node = ast.parse(code)
visitor = CodeVisitor()
visitor.visit(code_node)
print(visitor.seq)
hello.py中的内容是hello.py
输出结果如下
arguments
Store
Name
Num
Add
Num
Mult
Num
BinOp
BinOp
Add
Num
BinOp
Assign
Load
Name
Return
FunctionDef
Module
这是对树的深度优先遍历得到的结果,这是目前得到的AST序列。
Smith-Waterman算法
利用该算法比较两份代码的AST序列。
基本概念
史密斯-沃特曼算法(Smith-Waterman algorithm)是一种进行局部序列比对(相对于全局比对)的算法,用于找出两个核苷酸序列或蛋白质序列之间的相似区域。该算法的目的不是进行全序列的比对,而是找出两个序列中具有高相似度的片段。
设要比对的两序列: A=a1a2...an,B=b1b2...bn
创建得分矩阵H,该矩阵的大小为n+1行,m+1列,全部初始化为0
设定: s(a,b)是组成序列的元素之间的相似性得分,Wk 表示长度为k的空位罚分。
那么设置罚分规则:
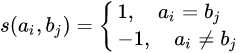
根据如下公式初始化该矩阵:
其中$H[i-1,j-1]+s(ai,bj)表示将ai,bj比对的相似性得分
$H[i-k,j]-Wk表示ai位于一段长度为k的删除的末端的得分
$H[i,j-l]-Wl表示bj位于一段长度为l的删除的末端的得分
0 表示 ai和bj到此为止无相关性
可以简化该算法,使用空位权值恒定模型的Smith Waterman算法,将空位罚分值固定。
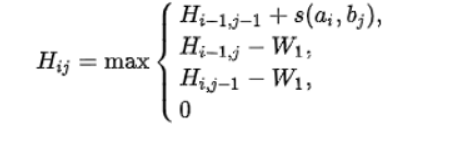
计算得分
根据如上所述来初始化这个矩阵,先设定空位罚分和罚分规则
A = "GGTTGACTA" # DNA序列
B = "TGTTACGG"
n, m = len(A), len(B) # 两个序列的长度
W = 2 # 空位罚分
# 罚分规则
def score(a, b):
if a == b:
return 3
else:
return -3
下面计算得分矩阵,首行和首列都初始化为0
for i in range(1, n+1):
for j in range(1, m+1):
s = score(A[i-1], B[j-1])
L = H[i-1, j-1] + s # 左上元素+score
P = H[i-1, j] - W # 左方元素-W
Q = H[i, j-1] - W # 上方元素-W
H[i, j] = max(L, P, Q, 0)
遍历两个下标,从1(即第二个元素)开始,按照上述公式计算得分。
完整代码
import numpy
A = "GGTTGACTA" # DNA序列
B = "TGTTACGG"
n, m = len(A), len(B) # 两个序列的长度
W = 2 # 空位罚分
def score(a, b):
if a == b:
return 3
else:
return -3
H = numpy.zeros([n+1, m+1], int)
for i in range(1, n+1):
for j in range(1, m+1):
s = score(A[i-1], B[j-1])
L = H[i-1, j-1] + s
P = H[i-1, j] - W
Q = H[i, j-1] - W
H[i, j] = max(L, P, Q, 0)
print(H)
输出如下:
[[ 0 0 0 0 0 0 0 0 0]
[ 0 0 3 1 0 0 0 3 3]
[ 0 0 3 1 0 0 0 3 6]
[ 0 3 1 6 4 2 0 1 4]
[ 0 3 1 4 9 7 5 3 2]
[ 0 1 6 4 7 6 4 8 6]
[ 0 0 4 3 5 10 8 6 5]
[ 0 0 2 1 3 8 13 11 9]
[ 0 3 1 5 4 6 11 10 8]
[ 0 1 0 3 2 7 9 8 7]]
这就是最终得到的得分矩阵。
回溯
从矩阵H中得分最高的元素开始根据得分的来源回溯至上一位置,如此反复直至遇到得分为0的元素。
首先得到矩阵中得分最高的元素的位置
若ai=bj,则回溯到左上角单元格 ,若ai≠bj,回溯到左上角、上边、左边中值最大的单元格,若有相同最大值的单元格,优先级按照左上角、上边、左边的顺序
根据回溯路径,写出匹配字符串:
若回溯到左上角单元格,将ai添加到匹配字串A1,将bj添加到匹配字串B1;
若回溯到上边单元格,将ai添加到匹配字串A1,将_添加到匹配字串B1;
若回溯到左边单元格,将_添加到匹配字串A1,将bj添加到匹配字串B1。

实际上上述操作就是从最大元素开始,找到产生该元素的元素的位置。例如最大元素是13,产生13的元素的位置是其左上角元素产生的。(10+3=13)
如果在生成这些元素的时候就保存这一回溯路径,那么会更高效,于是改写计算得分矩阵的代码:
path = {}
for i in range(0, n+1):
for j in range(0, m+1):
if i == 0 or j == 0:
path[point(i, j)] = None
else:
s = score(A[i-1], B[j-1])
L = H[i-1, j-1] + s
P = H[i-1, j] - W
Q = H[i, j-1] - W
H[i, j] = max(L, P, Q, 0)
# 添加进路径
path[point(i, j)] = None
if L == H[i, j]:
path[point(i, j)] = point(i-1, j-1)
if P == H[i, j]:
path[point(i, j)] = point(i-1, j)
if Q == H[i, j]:
path[point(i, j)] = point(i, j-1)
使用一个字典path来保存路径。在计算完H[i,j]后,判断是由左上元素、左边元素还是上边元素产生的,记录下位置,以字符串形式放入字典。
numpy.argwhere(H == numpy.max(H))
使用numpy.max找到最大元素的位置,该函数返回一个列表,如果有多个相等的最大值,那么将这些坐标都放入该列表,如果只有一个,那么该列表中只有一个元素。
end = numpy.argwhere(H == numpy.max(H))
for pos in end:
key = point(pos[0], pos[1])
traceback(path[key], [key])
找到最大值的坐标,然后在path找到该坐标对应的坐标,回溯找到的坐标,将沿途的坐标记录下来,直到访问到0值。
如下是回溯函数
def traceback(value, result):
if value:
result.append(value)
value = path[value]
x = int((value.split(',')[0]).strip('['))
y = int((value.split(',')[1]).strip(']'))
else:
return
if H[x, y] == 0: # 终止条件
print(result)
xx = 0
yy = 0
s1 = ''
s2 = ''
md = ''
for item in range(len(result) - 1, -1, -1):
position = result[item]
x = int((position.split(',')[0]).strip('['))
y = int((position.split(',')[1]).strip(']'))
if x == xx: # 判断是否为左方元素
s1 += '-'
s2 += B[y - 1]
md += ' '
elif y == yy: # 判断是否为上方元素
s1 += A[x - 1]
s2 += '-'
md += ' '
else: # 判断是否为左上元素
s1 += A[x - 1]
s2 += B[y - 1]
md += '|'
xx = x # 保存位置
yy = y
# 输出最佳匹配序列
print('s1: %s' % s1)
print(' ' + md)
print('s2: %s' % s2)
else:
traceback(value, result)
完整代码:
import numpy
A = "GGTTGACTA" # DNA序列
B = "TGTTACGG"
n, m = len(A), len(B) # 两个序列的长度
W = 2 # 空位罚分
# 判分
def score(a, b):
if a == b:
return 3
else:
return -3
# 字符串
def point(x, y):
return '[' + str(x) + ',' + str(y) + ']'
# 回溯
def traceback(value, result):
if value:
result.append(value)
value = path[value]
x = int((value.split(',')[0]).strip('['))
y = int((value.split(',')[1]).strip(']'))
else:
return
if H[x, y] == 0: # 终止条件
xx = 0
yy = 0
s1 = ''
s2 = ''
md = ''
for item in range(len(result) - 1, -1, -1):
position = result[item] # 取出坐标
x = int((position.split(',')[0]).strip('['))
y = int((position.split(',')[1]).strip(']'))
if x == xx: # 判断是否为左方元素
s1 += '-'
s2 += B[y - 1]
md += ' '
elif y == yy: # 判断是否为上方元素
s1 += A[x - 1]
s2 += '-'
md += ' '
else: # 判断是否为左上元素
s1 += A[x - 1]
s2 += B[y - 1]
md += '|'
xx = x
yy = y
# 输出最佳匹配序列
print('s1: %s' % s1)
print(' ' + md)
print('s2: %s' % s2)
else: # 未到终点 继续回溯
traceback(value, result)
H = numpy.zeros([n+1, m+1], int)
path = {}
for i in range(0, n+1):
for j in range(0, m+1):
if i == 0 or j == 0:
path[point(i, j)] = None
else:
s = score(A[i-1], B[j-1])
L = H[i-1, j-1] + s
P = H[i-1, j] - W
Q = H[i, j-1] - W
H[i, j] = max(L, P, Q, 0)
# 添加进路径
path[point(i, j)] = None
if L == H[i, j]:
path[point(i, j)] = point(i-1, j-1)
if P == H[i, j]:
path[point(i, j)] = point(i-1, j)
if Q == H[i, j]:
path[point(i, j)] = point(i, j-1)
end = numpy.argwhere(H == numpy.max(H))
for pos in end:
key = point(pos[0], pos[1])
traceback(path[key], [key])
输出
s1: GTTGAC
||| ||
s2: GTT-AC
计算相似度
将两部分功能整合
首先封装生成AST序列的功能
class CodeVisitor(ast.NodeVisitor):
def __init__(self):
self.seq = []
def generic_visit(self, node):
ast.NodeVisitor.generic_visit(self, node)
self.seq.append(type(node).__name__)
def visit_FunctionDef(self, node):
ast.NodeVisitor.generic_visit(self, node)
self.seq.append(type(node).__name__)
def visit_Assign(self, node):
self.seq.append(type(node).__name__)
class CodeParse(object):
def __init__(self, fileA, fileB):
self.visitorB = None
self.visitorA = None
self.codeA = open(fileA, encoding="utf-8").read()
self.codeB = open(fileB, encoding="utf-8").read()
self.nodeA = ast.parse(self.codeA)
self.nodeB = ast.parse(self.codeB)
self.seqA = ""
self.seqB = ""
self.work()
def work(self):
self.visitorA = CodeVisitor()
self.visitorA.visit(self.nodeA)
self.seqA = self.visitorA.seq
self.visitorB = CodeVisitor()
self.visitorB.visit(self.nodeB)
self.seqB = self.visitorB.seq
之后将SW算法封装进类
class CalculateSimilarity(object):
def __init__(self, A, B, W, M, N):
self.A = A
self.B = B
self.W = W
self.M = M
self.N = N
self.similarity = []
self.SimthWaterman(self.A, self.B, self.W)
def score(self,a, b):
if a == b:
return self.M
else:
return self.N
def traceback(self,A, B, H, path, value, result):
if value:
temp = value[0]
result.append(temp)
value = path[temp]
x = int((temp.split(',')[0]).strip('['))
y = int((temp.split(',')[1]).strip(']'))
else:
return
if H[x, y] == 0: # 终止条件
xx = 0
yy = 0
sim = 0
for item in range(len(result) - 2, -1, -1):
position = result[item]
x = int((position.split(',')[0]).strip('['))
y = int((position.split(',')[1]).strip(']'))
if x == xx:
pass
elif y == yy:
pass
else:
sim = sim + 1
xx = x
yy = y
self.similarity.append(sim * 2 / (len(A) + len(B)))
else:
self.traceback(A, B, H, path, value, result)
def SimthWaterman(self, A, B, W):
n, m = len(A), len(B)
H = numpy.zeros([n + 1, m + 1], int)
path = {}
for i in range(0, n + 1):
for j in range(0, m + 1):
if i == 0 or j == 0:
path[point(i, j)] = []
else:
s = self.score(A[i - 1], B[j - 1])
L = H[i - 1, j - 1] + s
P = H[i - 1, j] - W
Q = H[i, j - 1] - W
H[i, j] = max(L, P, Q, 0)
# 添加进路径
path[point(i, j)] = []
if math.floor(L) == H[i, j]:
path[point(i, j)].append(point(i - 1, j - 1))
if math.floor(P) == H[i, j]:
path[point(i, j)].append(point(i - 1, j))
if math.floor(Q) == H[i, j]:
path[point(i, j)].append(point(i, j - 1))
end = numpy.argwhere(H == numpy.max(H))
for pos in end:
key = point(pos[0], pos[1])
value = path[key]
result = [key]
self.traceback(A, B, H, path, value, result)
def Answer(self): # 取均值
return sum(self.similarity) / len(self.similarity)
完整代码
import math
import numpy
import ast
Similarity = []
def point(x, y):
return '[' + str(x) + ',' + str(y) + ']'
class CodeVisitor(ast.NodeVisitor):
def __init__(self):
self.seq = []
def generic_visit(self, node):
ast.NodeVisitor.generic_visit(self, node)
self.seq.append(type(node).__name__)
def visit_FunctionDef(self, node):
ast.NodeVisitor.generic_visit(self, node)
self.seq.append(type(node).__name__)
def visit_Assign(self, node):
self.seq.append(type(node).__name__)
class CodeParse(object):
def __init__(self, fileA, fileB):
self.visitorB = None
self.visitorA = None
self.codeA = open(fileA, encoding="utf-8").read()
self.codeB = open(fileB, encoding="utf-8").read()
self.nodeA = ast.parse(self.codeA)
self.nodeB = ast.parse(self.codeB)
self.seqA = ""
self.seqB = ""
self.work()
def work(self):
self.visitorA = CodeVisitor()
self.visitorA.visit(self.nodeA)
self.seqA = self.visitorA.seq
self.visitorB = CodeVisitor()
self.visitorB.visit(self.nodeB)
self.seqB = self.visitorB.seq
class CalculateSimilarity(object):
def __init__(self, A, B, W, M, N):
self.A = A
self.B = B
self.W = W
self.M = M
self.N = N
self.similarity = []
self.SimthWaterman(self.A, self.B, self.W)
def score(self,a, b):
if a == b:
return self.M
else:
return self.N
def traceback(self,A, B, H, path, value, result):
if value:
temp = value[0]
result.append(temp)
value = path[temp]
x = int((temp.split(',')[0]).strip('['))
y = int((temp.split(',')[1]).strip(']'))
else:
return
if H[x, y] == 0: # 终止条件
xx = 0
yy = 0
sim = 0
for item in range(len(result) - 2, -1, -1):
position = result[item]
x = int((position.split(',')[0]).strip('['))
y = int((position.split(',')[1]).strip(']'))
if x == xx:
pass
elif y == yy:
pass
else:
sim = sim + 1
xx = x
yy = y
self.similarity.append(sim * 2 / (len(A) + len(B)))
else:
self.traceback(A, B, H, path, value, result)
def SimthWaterman(self, A, B, W):
n, m = len(A), len(B)
H = numpy.zeros([n + 1, m + 1], int)
path = {}
for i in range(0, n + 1):
for j in range(0, m + 1):
if i == 0 or j == 0:
path[point(i, j)] = []
else:
s = self.score(A[i - 1], B[j - 1])
L = H[i - 1, j - 1] + s
P = H[i - 1, j] - W
Q = H[i, j - 1] - W
H[i, j] = max(L, P, Q, 0)
# 添加进路径
path[point(i, j)] = []
if math.floor(L) == H[i, j]:
path[point(i, j)].append(point(i - 1, j - 1))
if math.floor(P) == H[i, j]:
path[point(i, j)].append(point(i - 1, j))
if math.floor(Q) == H[i, j]:
path[point(i, j)].append(point(i, j - 1))
end = numpy.argwhere(H == numpy.max(H))
for pos in end:
key = point(pos[0], pos[1])
value = path[key]
result = [key]
self.traceback(A, B, H, path, value, result)
def Answer(self): # 取均值
return sum(self.similarity) / len(self.similarity)
def main():
AST = CodeParse("test1.py","test2.py")
RES = CalculateSimilarity(AST.seqA, AST.seqB, 1, 1, -1/3)
print(RES.Answer())
if __name__ == "__main__":
main()
向CodeParse传入两个python文件名,即可计算出最终的相似度值.
Python代码相似度计算(基于AST和SW算法)的更多相关文章
- 【codenet】代码相似度计算框架调研 -- 把内容与形式分开
首发于我的gitpages博客 https://helenawang.github.io/2018/10/10/代码相似度计算框架调研 代码相似度计算框架调研 研究现状 代码相似度计算是一个已有40年 ...
- python 文本相似度计算
参考:python文本相似度计算 原始语料格式:一个文件,一篇文章. #!/usr/bin/env python # -*- coding: UTF-8 -*- import jieba from g ...
- [python] 使用scikit-learn工具计算文本TF-IDF值
在文本聚类.文本分类或者比较两个文档相似程度过程中,可能会涉及到TF-IDF值的计算.这里主要讲述基于Python的机器学习模块和开源工具:scikit-learn. 希望文章对你有所帮 ...
- 皮尔逊相似度计算的例子(R语言)
编译最近的协同过滤算法皮尔逊相似度计算.下顺便研究R简单使用的语言.概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 由于这里每一个数都是等概率的.所以就当做是数 ...
- 皮尔森相似度计算举例(R语言)
整理了一下最近对协同过滤推荐算法中的皮尔森相似度计算,顺带学习了下R语言的简单使用,也复习了概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 因为这里每个数都是等 ...
- python 代码检测工具
对于我这种习惯了 Java 这种编译型语言,在使用 Python 这种动态语言的时候,发现错误经常只能在执行的时候发现,总感觉有点不放心. 而且有一些错误由于隐藏的比较深,只有特定逻辑才会触发,往往导 ...
- Python简单实现基于VSM的余弦相似度计算
在知识图谱构建阶段的实体对齐和属性值决策.判断一篇文章是否是你喜欢的文章.比较两篇文章的相似性等实例中,都涉及到了向量空间模型(Vector Space Model,简称VSM)和余弦相似度计算相关知 ...
- 余弦相似度及基于python的三种代码实现、与欧氏距离的区别
1.余弦相似度可用来计算两个向量的相似程度 对于如何计算两个向量的相似程度问题,可以把这它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向.两条线段之间形成一个夹角, ...
- 相似度与距离计算python代码实现
#定义几种距离计算函数 #更高效的方式为把得分向量化之后使用scipy中定义的distance方法 from math import sqrt def euclidean_dis(rating1, r ...
- win7基于mahout推荐之用户相似度计算
http://www.douban.com/note/319219518/?type=like win7基于mahout推荐之用户相似度计算 2013-12-03 09:19:11 事情回到半年 ...
随机推荐
- 按list大小进行分组
package cn.tk.netcore.rest;import java.util.ArrayList;import java.util.Arrays;import java.util.List; ...
- Matlab字体设置中找不到字体的解决方法(转载)
Matlab字体设置中找不到字体 Matlab默认的字体实在不好看,一般都需要重新设置字体. 在其字体设置中有些字体不能同时支持中文和英文,我在之前的博客中说过,如何为Matlab设置一款好看的同时兼 ...
- SQL字符匹配
一般形式 列名 [not] like 'str' 匹配串可以是以下四种通配符: 单下划线 _:匹配任意一个字符: %:匹配0个或多个字符: [ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的, ...
- selenium 使用ddt,运行提示错误信息no such test method
测试用例test_asg测试数据是通过ddt的方式添加,使用suite.addTest方法添加该用例提示错误信息no such test method in <class 'unitest_lo ...
- 对利用jsp模板编写登录、注册界面的方法言
使用模板的相关操作步骤详解 1.可以在相关的网站上面找相关的css或者js文件,下载到一个特定的文件夹里面,以备使用 2.然后,将存有相关代码的文件夹直接复制粘贴到web文件下,就会直接保存,可以根据 ...
- Nacos与OpenFeign开发
目录 1.前言 2.生产者 3.消费者 4.扩展 1.前言 我的话是微服务B调用微服务A的controller层 2.生产者 微服务A请求接口如下: @GetMapping("/listUn ...
- 2019徐州网络赛 M Longest subsequence 序列自动机
题目链接https://nanti.jisuanke.com/t/41395 题意:给两个字符串,s和t,在s中求字典序严格大于t的最长子序列. 思路:分类讨论即可.先建个s的序列自动机. 1 如果有 ...
- University of Toronto Faculty of Arts and Science MAT344– Final Assessment Combinatorics Instructors: Stanislav Balchev and Max Klambauer 19 August 2020
目录 随便找的一份测试题 T7 T9 T6 T5 solution to (a) solution to (b) solution to (c) solution to (d) T1 T2 T3 T4 ...
- Learning with Mini-Batch
在机器学习中,学习的目标是选择期望风险\(R_{exp}\)(expected loss)最小的模型,但在实际情况下,我们不知道数据的真实分布(包含已知样本和训练样本),仅知道训练集上的数据分布.因此 ...
- es6中clss做了些什么 怎么继承
我的理解是clss实际是一种语法糖 凡是es6中clss能做的 我们通过es5也同样可以完成传统的javascript中只有对象,没有类的概念.它是基于原型的面向对象语言.原型对象特点就是将自身的属性 ...