【离线数仓】Day04-即席查询(Ad Hoc):Presto链接不同数据源查询、Druid建多维表、Kylin使用cube快速查询


一、Presto
1、简介
概念:大数据量、秒级、分布式SQL查询engine【解析SQL但不是数据库】
架构

不同worker对应不同的数据源(各数据源有对应的connector连接适配器)
优缺点
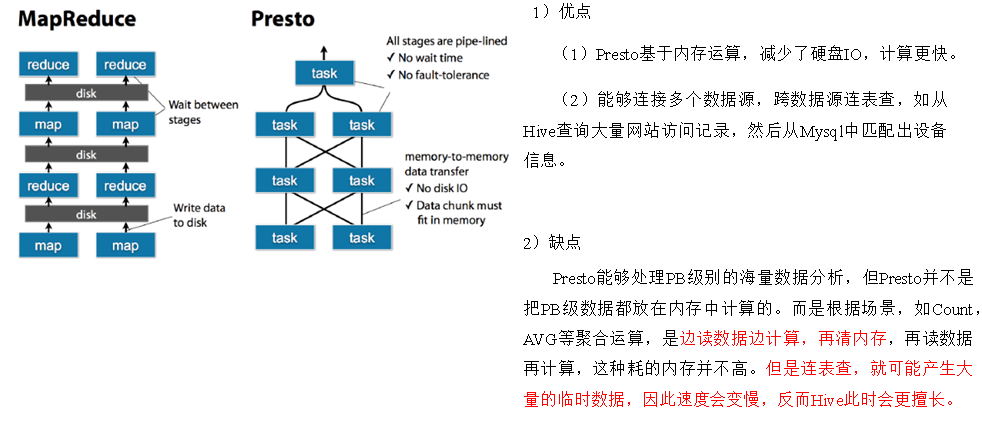
缺点:读数据连查表会产生大量临时数据
与impala比较
Impala性能稍领先于Presto,但是Presto在数据源支持上非常丰富,如redis
2、安装
server安装
配置一个Hive的catalog
在hadoop102上配置成coordinator,在hadoop103、hadoop104上配置为worker
client安装:[atguigu@hadoop102 presto]$ ./prestocli --server hadoop102:8881 --catalog hive --schema default
可视化client安装:
[atguigu@hadoop102 yanagishima-18.0]$
nohup bin/yanagishima-start.sh >y.log 2>&1 &
3、Presto优化之数据存储
合理设置分区
使用列式存储:相对于Parquet,Presto对ORC支持更好
使用压缩:采用Snappy压缩
4、Presto优化之查询SQL
选择使用的字段
过滤条件加分区字段:where语句中优先使用分区字段进行过滤
Group By优化:合理安排Group by语句中字段顺序,按照每个字段distinct数据多少进行降序排列
Order By时使用Limit:查询Top N或者Bottom N
使用Join语句时将大表放在左边:join左边的表分割到多个worker,然后将join右边的表数据整个复制一份
5、其他注意事项
字段名反引用:MySQL对字段加反引号`、Presto对字段加双引号分割,以避免和关键字冲突
时间函数:SELECT t FROM a WHERE t > timestamp '2017-01-01 00:00:00';
不支持INSERT OVERWRITE语法:先delete,然后insert into
PARQUET格式:支持Parquet格式,支持查询,但不支持insert
二、Druid
1、简介
概念:快速、列式、分布式、支持实时分析的数据存储系统,性能比OLAP高(PB数据、毫秒查询、实时处理)
与阿里的Druid连接池无关
特点

应用场景(单表、不更新),按照时间分片


2、框架原理

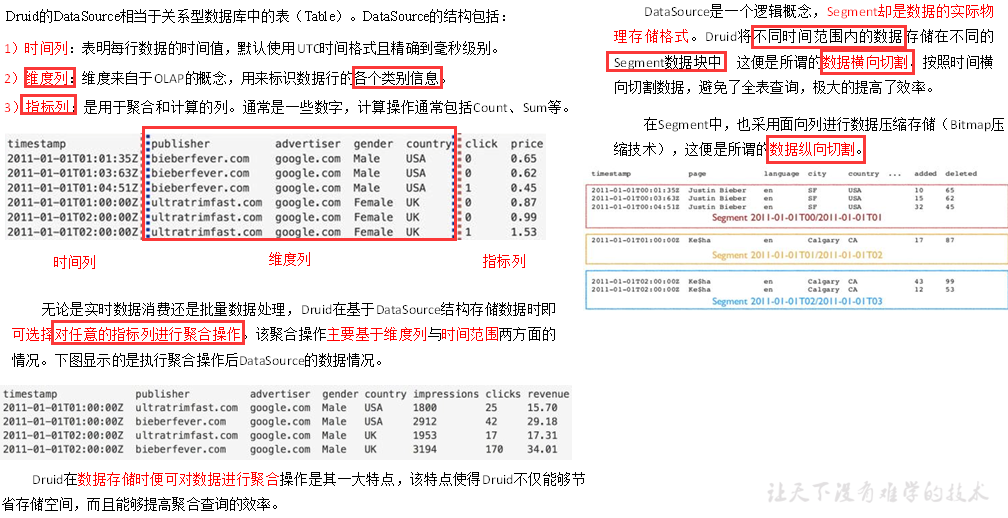
3、数据结构
4、Druid安装(单机版)
改配置(不用内置zk)
启动:[atguigu@hadoop102 imply]$ bin/supervise -c conf/supervise/quickstart.conf
启动采集Flume和Kafka
web页面
启动日志生成程序,登录页面加载数据,创建数据库表配置及时间字段
使用SQL查询
三、Kylin
1、Kylin简介
定义
分布式分析引擎,快速查询巨大的Hive表
架构
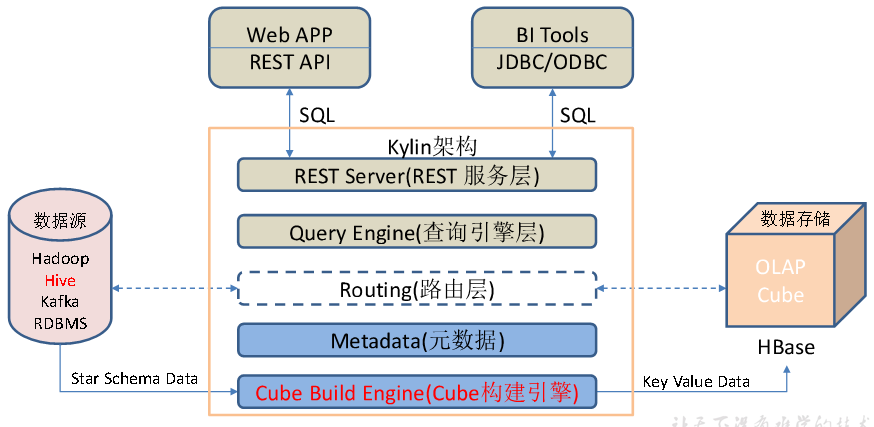
Kylin的元数据存储在hbase中
任务引擎对Kylin当中的全部任务加以管理与协调
特点:支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等
2、安装
依赖环境:先部署好Hadoop、Hive、Zookeeper、HBase
启动:bin/kylin.sh start
http://hadoop102:7070/kylin查看Web页面
3、使用:使用Kylin进行OLAP分析
建工程
添加数据源(导入hive表)
创建model
选择维度表,并指定事实表和维度表的关联条件
构建cube,添加维度或者度量字段
选择要构建的时间区间
实现每日自动构建cube-编写脚本
4、cube构建原理

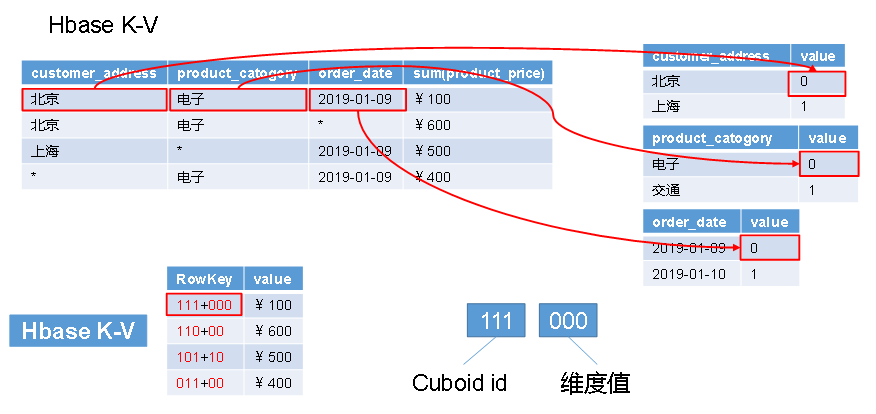
构建算法:逐层构建、快速构建
5、cube构建优化
使用衍生维度-中间表实现主到非主的映射
使用聚合组:强制维度、层级维度、联合维度
Row Key优化:用作where过滤的维度放在前边、基数大的维度放在基数小的维度前边
并发粒度优化
6、Kylin Bi工具集成
与Kylin结合使用的可视化工具很多,例如:
ODBC:与Tableau、Excel、PowerBI等工具集成
JDBC:与Saiku、BIRT等Java工具集成
RestAPI:与JavaScript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
JDBC
Zepplin:[atguigu@hadoop102 zeppelin]$ bin/zeppelin-daemon.sh start
修改配置
添加Note并编写SQL语句查询

【离线数仓】Day04-即席查询(Ad Hoc):Presto链接不同数据源查询、Druid建多维表、Kylin使用cube快速查询的更多相关文章
- 技术专家说 | 如何基于 Spark 和 Z-Order 实现企业级离线数仓降本提效?
[点击了解更多大数据知识] 市场的变幻,政策的完善,技术的革新--种种因素让我们面对太多的挑战,这仍需我们不断探索.克服. 今年,网易数帆将持续推出新栏目「金融专家说」「技术专家说」「产品专家说」等, ...
- 即席查询(Ad Hoc)如何做到又快又稳?
数字化与数字生态建设,是当前所有企业成长发展的必经之路.随着"加强新型基础设施建设"第一次被写入政府工作报告,5G.人工智能.工业互联网.智慧城市等新型基建彻底激发了数字的价值. ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- Optimize For Ad Hoc Workloads
--临时工作负载优化 即席查询:也就是查询完没放到Cache当中,每次查询都要重新经过编译,并发高的时候很耗性能: 参数化查询: 一方面解决了重编译问题,但随着数据库数据数据的变更,统计信息的更新 ...
- 数仓1.1 分层| ODS& DWD层
数仓分层 ODS:Operation Data Store原始数据 DWD(数据清洗/DWI) data warehouse detail数据明细详情,去除空值,脏数据,超过极限范围的明细解析具体表 ...
- 阿里下一代云分析型数据库AnalyticDB入选Forrester云化数仓象限
前言 近期, 全球权威IT咨询机构Forrester发布"The Forrester Wave: CloudData Warehouse Q4 2018"研究报告,阿里巴巴分析型数 ...
- 阿里巴巴下一代云分析型数据库AnalyticDB入选Forrester Wave™ 云数仓评估报告 解读
前言近期, 全球权威IT咨询机构Forrester发布"The Forrester WaveTM: CloudData Warehouse Q4 2018"研究报告,阿里巴巴分析型 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Spark篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- ETL数仓测试
前言 datalake架构 离线数据 ODS -> DW -> DM https://www.jianshu.com/p/72e395d8cb33 https://www.cnblogs. ...
随机推荐
- Minio设置永久下载链接
目前了解到的有如下两种方法 建议采用第二种办法 第一种方法:设置Access Policy为public 不论文件是否已经操作过分享动作,只要存储桶中有这个文件就能通过如下形式直接访问: http:/ ...
- Winsw将jar包部署为windows服务
1. 下载Winsw https://github.com/winsw/winsw/releases 下载winsw官网上的xml文件和.exe文件 2. 编辑配置文件 创建一个文件夹demo,将所需 ...
- Elasticsearch:使用 GeoIP 丰富来自内部专用 IP 地址
转载自:https://blog.csdn.net/UbuntuTouch/article/details/108614271 对于公共 IP,可以创建表来指定 IP 属于哪个城市的特定范围.但是,互 ...
- 工厂想采购一套信息化生产执行系统mes,不知道用哪家比较好?
好的信息化生产执行系统MES多的是,但是否适用于贵工厂那就不得而知了,要知道,不同行业.不同产品.不同规模的工厂用同一套系统效果呈现出来都不一样的,所以匹配很重要,个性化差异化.变化性等决定了一个工厂 ...
- 适用于纯64位Linux系统无需multilib运行win32软件的Wine
链接: https://pan.baidu.com/s/1qbDGz8mI-TtZLOFvEQetbg 提取码: uk6u 食用方法:解包到~ export HOQEMU=$HOME/hangover ...
- 仿B站小火箭发射上升
效果图: CSS代码块: <style type="text/css"> .goTop { background-image: url(img/rocket_top ...
- Codeforces Round #804 (Div. 2) C(组合 + mex)
Codeforces Round #804 (Div. 2) C(组合 + mex) 本萌新的第一篇题解qwq 题目链接: 传送门QAQ 题意: 给定一个\(\left [0,n-1 \right ] ...
- 方法的重载(overload)
1.定义:在同一个类中,允许存在一个以上的同名方法,只要它们的参数个数或者参数类型不同即可. "两同一不同":同一个类.相同方法名 参数列表不同:参数个数不同,参数类型不同 2.举 ...
- Selenium+Python系列(二) - 元素定位那些事
一.写在前面 今天一实习生小孩问我,说哥你自动化学了多久才会的,咋学的? 自学三个月吧,真的是硬磕呀,当时没人给讲! 其实,学什么都一样,真的就是你想改变的决心有多强罢了. 二.元素定位 这部分内容可 ...
- 使用ssm框架搭建的图书管理系统
等下贴代码 学生图书管理系统 实现的功能: 1.图书信息查询(暂时未分页处理) 2.图书信息修改(点击保存按钮后返回修改后的图书信息界面) 3.删除一本图书(删除某一本书籍,在图书管理界面则不存在该条 ...