GTID主从
GTID主从
GTID概念介绍
GTID即全局事务ID (global transaction identifier), 其保证为每一个在主上提交的事务在复制集群中可以生成一个唯一的ID。GTID最初由google实现,官方MySQL在5.6才加入该功能。mysql主从结构在一主一从情况下对于GTID来说就没有优势了,而对于2台主以上的结构优势异常明显,可以在数据不丢失的情况下切换新主。使用GTID需要注意: 在构建主从复制之前,在一台将成为主的实例上进行一些操作(如数据清理等),通过GTID复制,这些在主从成立之前的操作也会被复制到从服务器上,引起复制失败。也就是说通过GTID复制都是从最先开始的事务日志开始,即使这些操作在复制之前执行。比如在server1上执行一些drop、delete的清理操作,接着在server2上执行change的操作,会使得server2也进行server1的清理操作。
GTID实际上是由UUID+TID (即transactionId)组成的。其中UUID(即server_uuid) 产生于auto.conf文件(cat /data/mysql/data/auto.cnf),是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增,所以GTID能够保证每个MySQL实例事务的执行(不会重复执行同一个事务,并且会补全没有执行的事务)。GTID在一组复制中,全局唯一。 下面是一个GTID的具体形式 :
了解了GTID的格式,通过UUID可以知道这个事务在哪个实例上提交的。通过GTID可以极方便的进行复制结构上的故障转移,新主设置,这就很好地解决了下面这个图所展现出来的问题。
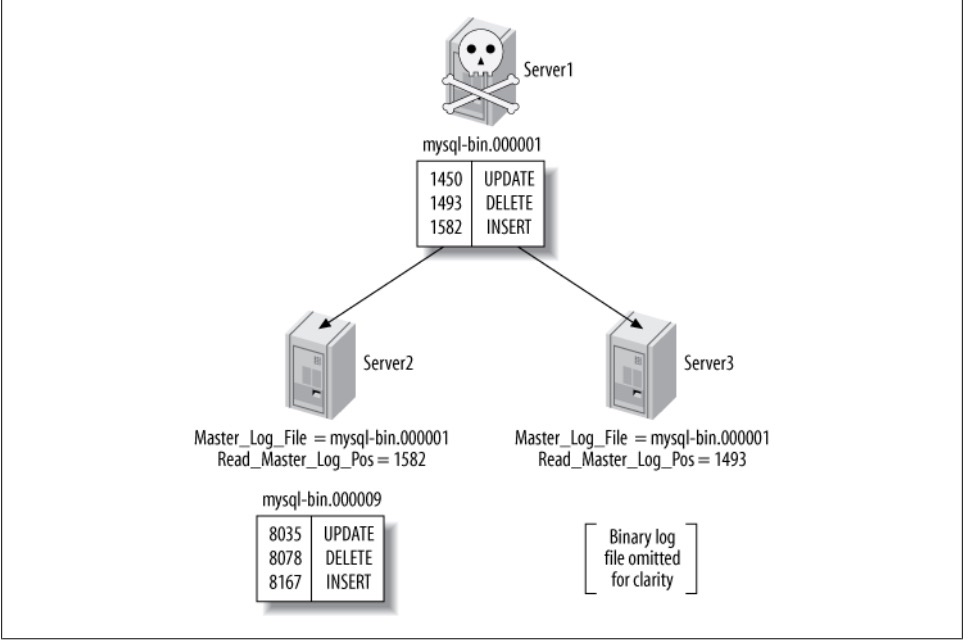
如图, Server1(Master)崩溃,根据从上show slave status获得Master_log_File/Read_Master_Log_Pos的值,Server2(Slave)已经跟上了主,Server3(Slave)没有跟上主。这时要是把Server2提升为主,Server3变成Server2的从。这时在Server3上执行change的时候需要做一些计算。
这个问题在5.6的GTID出现后,就显得非常的简单。由于同一事务的GTID在所有节点上的值一致,那么根据Server3当前停止点的GTID就能定位到Server2上的GTID。甚至由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION命令就可以直接完成failover的工作。
====== GTID和Binlog的关系 ======
- GTID在binlog中的结构

- GTID event 结构

- Previous_gtid_log_event
Previous_gtid_log_event 在每个binlog 头部都会有每次binlog rotate的时候存储在binlog头部Previous-GTIDs在binlog中只会存储在这台机器上执行过的所有binlog,不包括手动设置gtid_purged值。换句话说,如果你手动set global gtid_purged=xx; 那么xx是不会记录在Previous_gtid_log_event中的。 - GTID和Binlog之间的关系是怎么对应的呢? 如何才能找到GTID=? 对应的binlog文件呢?
假设有4个binlog: bin.001,bin.002,bin.003,bin.004
bin.001 : Previous-GTIDs=empty; binlog_event有: 1-40
bin.002 : Previous-GTIDs=1-40; binlog_event有: 41-80
bin.003 : Previous-GTIDs=1-80; binlog_event有: 81-120
bin.004 : Previous-GTIDs=1-120; binlog_event有: 121-160
假设现在我们要找GTID=$A,那么MySQL的扫描顺序为: - 从最后一个binlog开始扫描(即: bin.004)
- bin.004的Previous-GTIDs=1-120,如果$A=140 > Previous-GTIDs,那么肯定在bin.004中
- bin.004的Previous-GTIDs=1-120,如果$A=88 包含在Previous-GTIDs中,那么继续对比上一个binlog文件 bin.003,然后再循环前面2个步骤,直到找到为止.
====== GTID 重要参数的持久化 =======
- GTID相关参数
| 参数 | comment |
|---|---|
| gtid_executed | 执行过的所有GTID |
| gtid_purged | 丢弃掉的GTID |
| gtid_mode | GTID模式 |
| gtid_next | session级别的变量,下一个gtid |
| gtid_owned | 正在运行的GTID |
| enforce_gtid_consistency | 保证GTID安全的参数 |
====== 开启GTID的必备条件 =====
gtid_mode=on (必选)
enforce-gtid-consistency=1 (必选)
log_bin=mysql-bin (可选) #高可用切换,最好开启该功能
log-slave-updates=1 (可选) #高可用切换,最好打开该功能
GTID工作原理
从服务器连接到主服务器之后,把自己执行过的GTID (Executed_Gtid_Set: 即已经执行的事务编码) 、获取到的GTID (Retrieved_Gtid_Set: 即从库已经接收到主库的事务编号) 发给主服务器,主服务器把从服务器缺少的GTID及对应的transactions发过去补全即可。当主服务器挂掉的时候,找出同步最成功的那台从服务器,直接把它提升为主即可。如果硬要指定某一台不是最新的从服务器提升为主, 先change到同步最成功的那台从服务器, 等把GTID全部补全了,就可以把它提升为主了。
GTID是MySQL 5.6的新特性,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
简而言之,GTID的工作流程为:
- master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
- slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
- sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
- 如果有记录,说明该GTID的事务已经执行,slave会忽略。
- 如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。
GTID主从配置
环境说明:
| 数据库角色 | IP | 应用与系统版本 |
|---|---|---|
| 主数据库 | 192.168.244.120 | centos8/redhat8 mysql-5.7 |
| 从数据库 | 192.168.244.121 | centos8/redhat8 mysql-5.7 |
主库配置。vi /etc/my.cnf,添加以下配置,重启mysql。
[root@rh1 ~]# vim /etc/my.cnf
[mysqld]
basedir = /usr/local/mysql
datadir = /opt/data
socket = /tmp/mysql.sock
port = 3306
pid-file = /opt/data/mysql.pid
user = mysql
skip-name-resolve
sql-mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#添加以下配置
log_bin = mysql_bin
server-id = 10
gtid_mode = on
enforce-gtid-consistency = true
log-slave-updates = on
[root@rh1 ~]# systemctl restart mysqld.service #重启mysql服务
从库配置。vi /etc/my.cnf, 添加以下配置,重启mysql。
[root@rh2 ~]# vim /etc/my.cnf
[mysqld]
basedir = /usr/local/mysql
datadir = /opt/data
socket = /tmp/mysql.sock
port = 3306
pid-file = /opt/data/mysql.pid
user = mysql
skip-name-resolve
sql-mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#添加以下配置
server-id=20
relay-log=myrelay
gtid_mode=on
enforce-gtid-consistency=true
log-slave-updates=on
read_only=on
master-info-repository=TABLE
relay-log-info-repository=TABLE
[root@rh2 ~]# systemctl restart mysqld.service
主库授权复制用户。
mysql> grant replication slave on *.* to 'keli'@'192.168.244.121' identified by '1234';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show master status;
+------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+------------------------------------------+
| mysql_bin.000001 | 621 | | | 7dd47f79-10af-11ed-aac3-000c29135e86:1-2 |
+------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
从库设置要同步的主库信息,并开启同步
mysql> change master to master_host='192.168.244.120',
-> master_port=3306,master_user='keli',
-> master_password='1234',
-> master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
#查看详细信息
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.244.120
Master_User: keli
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql_bin.000002
Read_Master_Log_Pos: 451
Relay_Log_File: myrelay.000002
Relay_Log_Pos: 664
Relay_Master_Log_File: mysql_bin.000002
Slave_IO_Running: Yes #要为yes才有效
Slave_SQL_Running: Yes #要为yes才有效
测试
#在主库上删除一个数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| centos |
| linux |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> drop database centos;
Query OK, 0 rows affected (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linux |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
#查看从库,发现centos库也被删除了
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linux |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
GTID主从的更多相关文章
- 解决mysql开启GTID主从同步出现1236错误问题【转】
最近遇到mysql开启gtid做复制时,从库出现1236错误,导致同步无法进行,本文就这问题记录下处理步骤,有关gtid知识在这里不做介绍,mysql版本为5.7.16. 一.错误原因分析 错误信息如 ...
- 解决mysql开启GTID主从同步出现1236错误问题
解决mysql开启GTID主从同步出现1236错误问题 最近遇到mysql开启gtid做复制时,从库出现1236错误,导致同步无法进行,本文就这问题记录下处理步骤,有关gtid知识在这里不做介 ...
- Mysql5.7的gtid主从半同步复制和组复制
(一)gtid主从半同步复制 一.半同步复制原理 mysql默认的复制是异步的,主库在执行完客户端提交的事务后会立即将结果返回给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主库如果cr ...
- GTID主从 与 传统主从复制
一.主从复制 1.)普通主从复制: 普通主从复制主要是基于二进制日志文件位置的复制,因此主必须启动二进制日志记录并建立唯一的服务器ID,复制组中的每个服务器都必须配置唯一的服务器ID.如果您省略ser ...
- GTID主从与传统主从复制
目录 1.主从复制 2.靠什么同步 3.pos与GTID的什么区别 4.GTID的工作原理 5.GTID参数配置 5.1 在主数据库里创建一个同步账号授权给从数据库使用 5.2 配置主数据库 5.3配 ...
- GTID主从和lamp架构运行原理
目录 GTID主从 GTID概念介绍 GTID工作原理 GTID主从配置 lamp lamp简介 web服务器工作流程 cgi与fastcgi http协议 是什么? lamp架构运行的原理 Apac ...
- mysql GTID主从配置
主数据库配置 [mysqld] server_id=1 gtid_mode=on enforce_gtid_consistency=on skip_slave_start=1log_bin=maste ...
- MySQL 基于 GTID 主从架构添加新 Slave 的过程
内容全部来自: How to create/restore a slave using GTID replication in MySQL 5.6 需求说明 需求: 对于已经存在的 MySQL 主从架 ...
- mysql+gtid主从同步
安装mysql yum install mysql-community-client-5.7.17-1.el6.x86_64.rpm mysql-community-common-5.7.17-1. ...
随机推荐
- Javascript 构造函数、原型对象、实例之间的关系
# Javascript 构造函数.原型对象.实例之间的关系 # 创建对象的方式 # 1.new object() 缺点:创建多个对象困难 var hero = new Object(); // 空对 ...
- 使用.NET简单实现一个Redis的高性能克隆版(一)
译者注 该原文是Ayende Rahien大佬业余自己在使用C# 和 .NET构建一个简单.高性能兼容Redis协议的数据库的经历. 首先这个"Redis"是非常简单的实现,但是他 ...
- 论文解读(PPNP)《Predict then Propagate: Graph Neural Networks meet Personalized PageRank》
论文信息 论文标题:Predict then Propagate: Graph Neural Networks meet Personalized PageRank论文作者:Johannes Gast ...
- Win10使用fvm管理多个Flutter版本
Win10使用fvm管理多个Flutter版本 参考:https://blog.csdn.net/PyMuma/article/details/115298645 1.升级Flutter 由于现在的f ...
- Luogu3594 [POI2015]WIL-Wilcze doły (双端队列)
单调性显然,双端队列队列维护严格单调递减手写双端队列真的可恶. #include <iostream> #include <cstdio> #include <cstri ...
- 概述:基于事件的优化方法 / 事件驱动优化 / Event-Based Optimization / EBO
大家好,我是月出 本文基于这篇综述,介绍了 事件驱动优化(Event-Based Optimization, EBO). 事件驱动优化,是一种建模现实场景.做优化的思路,理论和 MDP / 强化学习很 ...
- 刷题记录:Codeforces Round #739 (Div. 3)
Codeforces Round #739 (Div. 3) 20210907.网址:https://codeforces.com/contest/1560. --(叹). A 不希望出现带" ...
- rh358 001 Linux网络与systemd设置
358 rhel7 ce ansible 部署服务 dhcp nginx vanish haproxy 打印机服务 服务管理自动化 systemd与systemctl systemctl 来管理sys ...
- AtCoder Beginner Contest 260 (D-E)
AtCoder Beginner Contest 260 - AtCoder D - Draw Your Cards 题意:N张卡牌数字 1-n,以某种顺序排放,每次拿一张,如果这一张比前面某一张小( ...
- SCP远程传输文件
今天想用SCP通过局域网传输文件到服务器,但却发生了下面这种事情: 上面描述 连接主机端口22被拒绝,失去连接 后发现因为没有指定端口,我服务器这边改了端口,所以根据自己情况改一下命令 scp -29 ...