k-means聚类:擒贼先擒王,找到中心点,它附近的都是一类
属于无监督学习,聚类算法事先并不需要知道数据的类别标签,只是根据数据特征去学习,找到相似数据的特征,然后把已知的数据集划分成几个不同的类别
算法原理:
假设数据总共有m条,计划分成3个类别
先随机在这个空间中选取三个点,称之为中心点;计算所有的点到这三个点的距离,这里的距离计算使用的是欧氏距离;使用每个组的数据计算出这些数据的一个均值,使用这个均值作为下一轮迭代的中心点
如何确定k值
手肘法(适用于k值不那么大)
循环尝试k值,计算在不同的k值情况下,所有数据的损失即用每一个数据点到中心点的距离之和计算平均距离
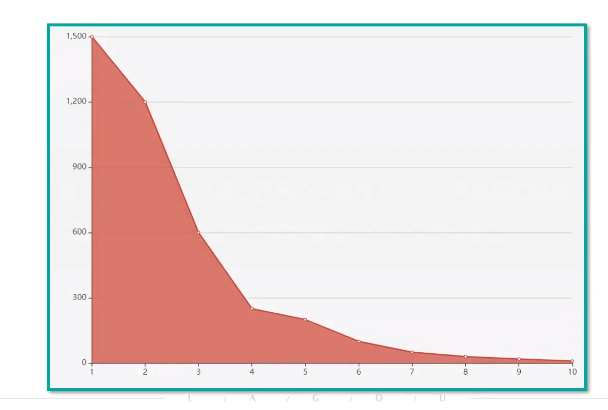
k=4时左侧数值变化大,右侧较为平缓
算法优点
简洁明了,计算复杂度低
收敛速度较快
算法缺点
结果不稳定
无法解决样本不均衡的问题
容易收敛到局部最优解
受噪声影响较大
from sklearn import datasets import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans """
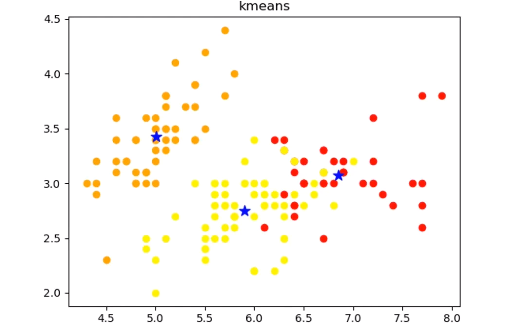
画出聚类后的图像
labels:聚类后的label,从0开始的数字
cents:质心坐标
n_cluster:聚类后簇的数量
"""
def draw_result(train_x,labels,cents,title):
n_clusters = np.unique(labels).shape[0]
color = ["red","orange","yellow"]
plt.figure()
plt.title(title)
for i in range(n_clusters):
current_data = train_x[labels ==i]
plt.scatter(current_data[:,0],current_data[:,1],c=color[i])
#使用蓝色的星形表示中心点位置
plt.scatter(cents[i,0],cents[i,1],c="blue",marker="*",s=100)
return plt if _name_ == '__main__':
iris = datasets.load_iris()
iris_x - iris.data
#设定聚类数目为3
clf = KMeans(n_clusters=3,max_iter=10,n_init=10,init="k-means++",algorithm="full",tol=1e-4,n_jobs=-1,random_state=1)
clf.fit(iris_x)
print("SSE={0}".format(clf.inertia_))
draw_result(iris_x,clf.labels_,clf.cluster_centers_,"kmeans").show()
#SEE是误差平方和,越接近0说明效果越好
k-means聚类:擒贼先擒王,找到中心点,它附近的都是一类的更多相关文章
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- R与数据分析旧笔记(十五) 基于有代表性的点的技术:K中心聚类法
基于有代表性的点的技术:K中心聚类法 基于有代表性的点的技术:K中心聚类法 算法步骤 随机选择k个点作为"中心点" 计算剩余的点到这个k中心点的距离,每个点被分配到最近的中心点组成 ...
- 第十篇:K均值聚类(KMeans)
前言 本文讲解如何使用R语言进行 KMeans 均值聚类分析,并以一个关于人口出生率死亡率的实例演示具体分析步骤. 聚类分析总体流程 1. 载入并了解数据集:2. 调用聚类函数进行聚类:3. 查看聚类 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
随机推荐
- LaunchScreen&LaunchImage
优先级:LaunchScreen > LaunchImage 在xcode配置了,不起作用 1.清空xcode缓存 2.直接删掉程序 重新运行 如果是通过LaunchImage设置启动界面,那么 ...
- LVS+Keepalived群集
LVS+Keepalived群集 目录 LVS+Keepalived群集 一.Keepalived实现原理 1. 单服务器的风险 2. Keepalived工具 3. Keepalived解决单点故障 ...
- ROS::message_filters中的一个报错(mt::TimeStamp……)
『方便检索』 ros::Time msg_time = mt::TimeStamp<typename mpl::at_c<Messages, i>::type>::value( ...
- Windows系统禁止自动更新
Windows + R键 输入services.msc(服务管理窗口) 找到Windows Update 停止且禁用 恢复->第一次失败 无操作 Windows + r 输入gpedit.msc ...
- 基于UDP传输协议局域网文件接收软件设计 Java版
网路传输主要的两大协议为TCP/IP协议和UDP协议,本文主要介绍基于UDP传输的一个小软件分享,针对于Java网络初学者是一个很好的练笔,大家可以参考进行相关的联系,但愿能够帮助到大家. 话不多说, ...
- Solution -「CF 923E」Perpetual Subtraction
\(\mathcal{Description}\) Link. 有一个整数 \(x\in[0,n]\),初始时以 \(p_i\) 的概率取值 \(i\).进行 \(m\) 轮变换,每次均匀随机 ...
- 小程序入门心得(不谈api)
小程序入门 一.准备 首先先去微信公众平台注册一个小程序账号,去拿到一个AppID(没AppID也可以开发,只是有些功能会受限),注册成功后到开发设置获取自己的AppID,即使有AppID有些功能还是 ...
- .Net Core Aop之IResourceFilter
一.简介 在.net core 中Filter分为一下六大类: 1.AuthorizeAttribute(权限验证) 2.IResourceFilter(资源缓存) 3.IActionFilter(执 ...
- Redis 源码简洁剖析 15 - AOF
AOF 是什么 AOF 持久化的实现 命令追加 AOF 文件的写入和同步 AOF 文件的载入和数据还原 AOF 重写 为什么需要重写 什么是重写 如何重写 AOF 后台重写 为什么需要后台重写 带来的 ...
- 对称加密算法之DES算法
数据加密标准(data encryption standard): DES是一种分组加密算法,输入的明文为64位,密钥为56位,生成的密文为64位. DES对64位的明文分组进行操作.通过一个初始置换 ...