基于ABP实现DDD--聚合和聚合根实践
在下面的例子中涉及Repository、Issue、Label、User这4个聚合根,接下来以Issue聚合为例进行分析,其中Issue聚合是由Issue[聚合根]、Comment[实体]、IssueLabel[值对象]组成的集合。
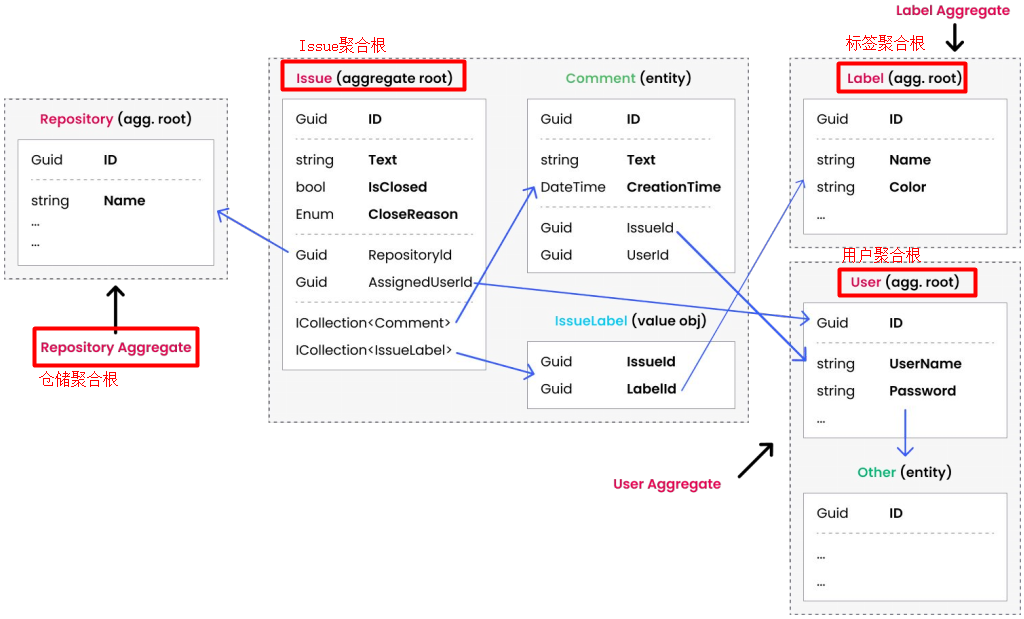
1.单个单元原则
简单理解,一个聚合就是由实体和值对象组成的集合,通过聚合根将所有关联对象绑定在一起,一个聚合是一个相对独立的业务单元。聚合和聚合根原则包括:包含业务原则,单个单元原则,事务边界原则,可序列化原则。接下来通过例子重点介绍下什么是单个单元原则,本质上是为了实现业务规则并保持数据的一致性和完整性。比如,要向Issue中添加Comment,操作如下:
- 通过聚合根Issue加载所有的实体Comments[该问题的评论列表]和值对象IssueLabels[该问题的标签集合]等。
- 在Issue类中有个AddComment()方法可以添加一个新的Comment。
- 通过数据库更新操作将Issue聚合,包括实体和值对象等保存到数据库。
添加Comment到Issue如下所示:
public class IssueAppService : ApplicationService, IIssueAppService
{
private readonly IRepository<IssueAppService, Guid> _issueRepository;
public IssueAppService(IRepository<Issue, Guid> issueRepository)
{
_issueRepository = issueRepository;
}
[Authorize]
public async Task CreateCommentAsync(CreateCommentInput input)
{
// 加载Issue对象并包含所有子集合
var issue = await _issueRepository.GetAsync(input.IssueId);
// 哪个用户评论了什么内容
issue.AddComment(CurrentUser.GetId(), input.Text);
// 保存更改到数据库,执行完后自动调用DbContext.SaveChanges()
await _issueRepository.UpdateAsync(issue);
}
}
2.只通过ID引用其它聚合
Repository和Issue的关系是一对多,即一个Repository对应多个Issue:
public class GitRepository : AggregateRoot<Guid>
{
public string name { get; set; }
public int StarCount { get; set; }
public Collection<Issue> Issues { get; set; } //错误实践,不能添加导航属性到其它聚合根
}
public class Issue : AggregateRoot<Guid>
{
public string Text { get; set; }
public GitRepository Repository { get; set; } //错误实践,不能添加导航属性到其它聚合根
public Guid RepositoryId { get; set; } //正确实践
}
3.聚合根要足够小
因为一个聚合将做为一个整体被加载和保存,如果聚合根很大,在读写一个大对象的时候会影响到性能问题。
using Microsoft.VisualBasic;
public class UserRole : ValueObject //值对象
{
public Guid UserId { get; set; }
public Guid RoleId { get; set; }
}
public class Role : AggregateRoot<Guid>
{
public string Name { get; set; }
public Collection<UserRole> Users { get; set; } //错误实践,理由是角色对应的用户是增加的
}
public class User : AggregateRoot<Guid>
{
public string Name { get; set; }
public Collection<UserRole> Roles { get; set; } //正确实践,理由是用户对应的角色总是有限的
}
官方的建议是一个子集合最多不应包含超过100-150条记录,否则建议为实体单独提取为一个新的聚合根。
4.聚合根/实体中的主键
聚合根通常使用Guid作为主键,聚合根中的实体[不是聚合根]可以使用复合主键。
// 聚合根:单个主键
public class Organization
{
public Guid Id { get; set; }
public string Name { get; set; }
// ...
}
// 实体:复合主键[值对象]
public class OrganizationUser
{
public Guid OrganizationId { get; set; } //主键
public Guid UserId { get; set; } //主键
public bool IsOwner { get; set; }
// ...
}
一般聚合根中的实体[不是聚合根]是单个主键的,而值对象基本都是复合主键,比如IssueLabel,通过复合主键关联Issue和Label这2个聚合根。
5.业务逻辑和实体中的异常处理
假定有2个业务原则:第1个是锁定的Issue不能重新打开,第2个是不能锁定一个关闭的Issue:
public class Issue:AggregateRoot<Guid>
{
//...
public bool IsLocked {get;private set;}
public bool IsClosed{get;private set;}
public IssueCloseReason? CloseReason {get;private set;}
public void Close(IssueCloseReason reason)
{
IsClose = true;
CloseReason =reason;
}
public void ReOpen() //重新打开
{
if(IsLocked)
{
throw new IssueStateException("不能打开⼀个锁定的问题!请先解锁!");
}
IsClosed=false;
CloseReason=null;
}
public void Lock() //锁定
{
if(!IsClosed)
{
throw new IssueStateException("不能锁定⼀个关闭的问题!请先打开!");
}
}
public void Unlock() //解锁
{
IsLocked = false;
}
}
这时会遇到2个问题,一个是异常消息本地化,另一个是HTTP状态码。通过ABP的异常处理系统可以解决这些问题,即IssueStateException类继承自BusinessException类[1]。重写ReOpen方法:
public void ReOpen()
{
if (IsLocked)
{
throw new IssueStateException("IssueTracking:CanNotOpenLockedIssue");
}
IsClosed = false;
CloseReason = null;
}
为了实现本地化消息处理,只用在本地化资源中添加"IssueTracking:CanNotOpenLockedIssue":"不能打开⼀个锁定的问题!请先解锁!"即可。HTTP状态码在BusinessException类中已经处理好了,比如403表示请求禁用,500表示服务器内部错误等。
6.实体中业务逻辑需要用到外部服务
假如业务规则是:一个用户不能同时分配超过3个未解决的问题。这时就需要一个服务,根据User的Id获取已经分配的未解决问题的数目。如何在实体类中实现它呢?暂时解决问题的思路是将外部依赖项作为方法的参数:
public class Issue : AggregateRoot<Guid>
{
// ...
public Guid? AssignedUserId { get; private set; } //将实体属性访问器设置私有,这样只能通过方法来访问
// 问题分配方法
// IUserIssueService:用于获取分配给用户的未解决问题的数量
public async Task AssignToAsync(AppUser user, IUserIssueService userIssueService)
{
var openIssueCount = await userIssueService.GetOpenIssueCountAsync(user.Id);
if (openIssueCount >= 3)
{
throw new BusinessException("IssueTracking:CanNotOpenLockedIssue");
}
AssignedUserId = user.Id;
}
// 清空分配方法
public void CleanAssignment()
{
AssignedUserId = null;
}
}
这种实现方式虽然满足了业务实现,但是实体变的复杂且难用,一方面实体类依赖外部服务,另一方面在调用方法AssignToAsync的时候需要注入依赖的外部服务IUserIssueService作为参数。比较优雅的实现此业务逻辑的方式是引入领域服务。
说明:聚合和聚合根最佳实践中的用于EF Core和关系型数据库、聚合根/实体构造函数、实体属性访问器和方法这3个部分就不介绍了,感兴趣参考《基于ABP Framework实现领域驱动设计》[2]。
参考文献:
[1]ABP异常处理:https://docs.abp.io/zh-Hans/abp/latest/Exception-Handling
[2]基于ABP Framework实现领域驱动设计:https://url39.ctfile.com/f/2501739-616007877-f3e258?p=2096 (访问密码: 2096)
基于ABP实现DDD--聚合和聚合根实践的更多相关文章
- 基于ABP落地领域驱动设计-02.聚合和聚合根的最佳实践和原则
目录 前言 聚合 聚合和聚合根原则 包含业务原则 单个单元原则 事务边界原则 可序列化原则 聚合和聚合根最佳实践 只通过ID引用其他聚合 用于 EF Core 和 关系型数据库 保持聚合根足够小 聚合 ...
- 从壹开始微服务 [ DDD ] 之六 ║聚合 与 聚合根 (下)
前言 哈喽大家周二好,上次咱们说到了实体与值对象的简单知识,相信大家也是稍微有些了解,其实实体咱们平时用的很多了,基本可以和数据库表进行联系,只不过值对象可能不是很熟悉,值对象简单来说就是在DDD领域 ...
- DDD之4聚合和聚合根
聚合就是归类的意思,把同类事物统一处理: 聚合根也就是最抽象,最普遍的特性: 背景 领域建模的过程回顾: 那么问题来了? 为什么要在限界上下文和实体之间增加聚合和聚合根的概念,即作用是什么? 如何设计 ...
- DDD中聚合、聚合根的含义以及作用
聚合与聚合根的含义 聚合: 聚合往往是一些实体为了某项业务而聚类在一起形成的集合 , 举个例子, 社会是由一个个的个体组成的,象征着我们每一个人.随着社会的发展,慢慢出现了社团.机构.部门等组织,我们 ...
- 关于领域驱动设计(DDD)中聚合设计的一些思考
关于DDD的理论知识总结,可参考这篇文章. DDD社区官网上一篇关于聚合设计的几个原则的简单讨论: 文章地址:http://dddcommunity.org/library/vernon_2011/, ...
- ASP.NET Core Web API下事件驱动型架构的实现(四):CQRS架构中聚合与聚合根的实现
在前面两篇文章中,我详细介绍了基本事件系统的实现,包括事件派发和订阅.通过事件处理器执行上下文来解决对象生命周期问题,以及一个基于RabbitMQ的事件总线的实现.接下来对于事件驱动型架构的讨论,就需 ...
- NET Core Web API下事件驱动型架构CQRS架构中聚合与聚合根的实现
NET Core Web API下事件驱动型架构在前面两篇文章中,我详细介绍了基本事件系统的实现,包括事件派发和订阅.通过事件处理器执行上下文来解决对象生命周期问题,以及一个基于RabbitMQ的事件 ...
- [2018-12-07]用ABP入门DDD
前言 ABP框架一直以来都是用DDD(领域驱动设计)作为宣传点之一.但是用过ABP的人都知道,ABP并不是一个严格遵循DDD的开发框架,又或者说,它并没有完整实现DDD的所有概念. 但是反过来说,认真 ...
- 基于ABP落地领域驱动设计-01.全景图
什么是领域驱动设计? 领域驱动设计(简称:DDD)是一种针对复杂需求的软件开发方法.将软件实现与不断发展的模型联系起来,专注于核心领域逻辑,而不是基础设施细节.DDD适用于复杂领域和大规模应用,而不是 ...
随机推荐
- OA办公软件篇(三)—审批流
背景 作用 迭代历程 具体实现 写在最后 背景 在前面两篇文章中,我们分别讲了组织架构和权限管理,今天我们来讲一个跟组织架构关系比较密切的功能-审批流. 审批流,通俗来说就是一个完整的审批流程,是 ...
- plicp 点云迭代最近邻点配准法
输入参数 点云A的极坐标集合 点云A对应Lidar所在pose 点云B的极坐标集合 点云B对应Lidar所在pose Features 根据两个点云的弧度关系确定找点的起始位置 根据两个点云的弧度关系 ...
- 弃用!Github 上用了 Git.io 缩址服务的都注意了
GitHub 是面向开源及私有软件项目的托管平台,因为只支持 Git 作为唯一的版本库格式进行托管,故名 GitHub.对程序员来说,GitHub 可以说是开源精神之所系.在 GitHub 任何职业程 ...
- django 备件管理系统
views 1 class limit: 2 3 def limit(self,res,obj): 4 limit = int(res.GET.get('limit',1)) 5 pagelimit ...
- ucontext的简单介绍
简介 结构体 函数 getcontext setcontext makecontext swapcontext 简介 ucontext.h是GNU C库的一个头文件,主要用于用户态下的上下文切换.需要 ...
- Python实现将csv文件转化为html文件
核心技术: Pandas 需要转化的csv文件(business.csv): 源代码: import pandas as pd f=pd.read_csv("business.csv&quo ...
- ML第6周学习小结
本周收获 总结一下本周学习内容: 1.学习了<深入浅出Pandas>的第六章:Pandas分组聚合 6.1概述 6.2分组 6.3分组对象的操作 我的博客链接: Pandas 分组聚合 : ...
- JavaSE_多线程入门 线程安全 死锁 状态 通讯 线程池
1 多线程入门 1.1 多线程相关的概念 并发与并行 并行:在同一时刻,有多个任务在多个CPU上同时执行. 并发:在同一时刻,有多个任务在单个CPU上交替执行. 进程与线程 进程:就是操作系统中正在运 ...
- django框架9
内容概要 用户名动态校验 删除二次确认 sweetalert前端插件 django自带的序列化组件 批量数据操作 分页器推导流程 自定义分页器封装代码 自定义分页器使用方法 校验性组件之forms组件 ...
- 介绍python和库文件管理
一.Python 特点 1.易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单. 2.易于阅读:Python代码定义的更清晰. 3.易于维护:Python的成功 ...