我的 Kafka 旅程 - broker
broker在kafka的服务端运行,一台服务器相当于一个broker;每个broker下可以有多个topic,每个topic可以有多个partition,在producer端可以对消息进行分区,每个partiton可以有多个副本,可以使得数据不丢失。
通常以集群模式,下面来阐述一下broker的几个状况。
分区数据与副本
kafka的partition有一个leader的数据区域,是为了接收producer端发送的数据;也可以通过克隆leader的方式创建副本,leader与副本保持数据同步,也就是为了在极端情况下的数据备份,每个分区的副本交错的存在于其它分区中,尽量以平均方式存放于各分区中,也可以手动指定存放的分区(假设是因服务器硬件的配置不同),当极端情况下,leader宕机后,自动启用副本作为新leader角色,负责接收消息。
leader与副本保持通信,副本持续向leader发送健康请求,超过30秒无连接的副本,从关联的副本中删除关系;副本数据默认为1个,通常我们至少设置为2个。
# 副本数量配置项(默认为1)
mis.insync.replicas
broker的应答机制
在上一章阐述过,broker是对producer的应答,它会告诉producer,对接收到的数据处理情况;
应答等级:(配置项为 acks)
- 0:不用等落地磁盘,直接应答
- 1:leader落地磁盘后应答
- all:leader和副本都落地磁盘后再应答(默认)
精准数据
数据的不重复
- broker单次启动运行,会有一个唯一的运行编号
- 每个分区都会有一个唯一的分区编号
- producer发送的每条消息都会有一个唯一的消息编号
像以上这种,对每个环节都会有唯一编号,kafka很方便的区分出每条消息的归属,为幂等性。
# 幂等性(默认开启)
enable.idempotence=true
数据防丢失
通过以上内容的了解,为防止数据的丢失,这里可以这样做:
1、应答机制设为-1,确保leader和副本都保存完成
2、分区副本至少有两个,确保随时有可启用的副本数据
当做到 数据不重复 + 数据防丢失,体现出数据的完整性、安全性、一致性。
数据的按序
broker中的leader在接收数据时,分区缓存按序最多可存5个请求数据,成功的消息请求会落地,消息请求按序落地磁盘,若一次消息请求失败,producer会尝试重发,此时leader分区的数据落地动作会暂停,但会缓存新收到的请求数据,积满5个后暂停接收,直至之前失败的消息请求成功后,再从此消息处,重新开始按序落地磁盘。多分区按发送序号落地磁盘。
leader分区缓存接收消息示意图
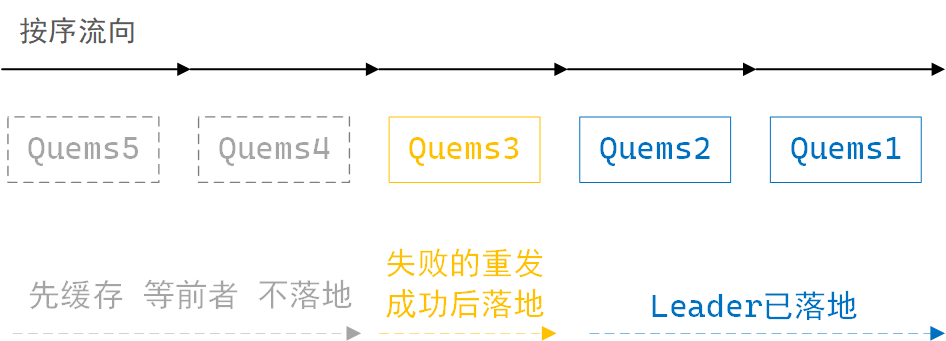
这里认为:开启幂等性 + 接收积压个数 + 按序落地磁盘,可以确保单个topic多分区消息不乱序。
leader partition 的自动平衡
假如,个别broker中的分区过多,个别broker中的分区过少,这不符合负载均衡。
kafka默认开启了每间隔一段时间,自动检测分区分布的差异值是否超过了警戒值,当超过设定的警戒值时,自动触发平均分布的动作。
# 开启自动平衡分布(默认)
auto.leader.rebalance.enable=true
# 不平衡警戒触发值(默认1%)
leader.imbalance.per.broker.percentage
# 检测间隔时间(默认300秒)
leader.imbalance.check.interval.seconds=300
通常不建议开启,或者把警戒触发值调大,或者把间隔时间设长,为减少被触发的次数;频繁性的触发平均分配,造成不必要的资源消耗。
管理节点(broker)
通常是向集群中添加新节点;每个broker启动后,会先向ZK注册,每个broker有个选举leader的controller,按注册的顺序为leader角色的替代者,leader的contraller负责监听ZK的broker.Ids并管理。以下阐述对节点(broker)的管理操作。
注册新节点
首先确保各IP及主机名的对应,便于后续节点相关的配置。
再次确保一个全新的节点,broker.id的设置、zookeeper.connect的配置、数据及日志目录为空。
启动该节点(自动注册并加入集群中)
手动设定节点分区
# 指定成员节点,重新分配分区,自动将数据同步到其它节点
bin/kafka-reassign-partitions.sh --broker-list '0,1,2'
减少/删除节点,同上,改变 --broker-list 的成员节点,数据将自动同步到其它节点
宕机后的数据同步
leader(broker)宕机恢复后,以当前leader数据为准,这里为了数据的一致性。
副本(broker)宕机恢复后,向leader请求同步数据。
我的 Kafka 旅程 - broker的更多相关文章
- Flume连接Kafka的broker出错
在启动Flume的时候,出现下面的异常,但是程序照样能运行,Kafka也能够收到数据,只是偶尔会断点. 2016-08-25 15:32:54,561 (SinkRunner-PollingRunne ...
- 【Kafka】Broker之Server.properties的重要参数说明
名称 描述 类型 默认值 有效值区间 重要程度 zookeeper.connect zk地址 string 高 advertised.host.name 过时的:只有当advertised.liste ...
- 我的 Kafka 旅程 - Linux下的安装 & 基础命令
准备工作 安装解压缩工具 tar # 检查是否安装了解压缩工具 tar yum list tar # 如未安装 tar yum install tar -y 安装必备的 java # 检查是否安装了 ...
- 我的 Kafka 旅程 - 文件存储机制
存储机制 Topic在每个Broker下存储所属的Partition,Partition下由 Index.Log 两类文件组成. 写入 Log 由多个Segment文件组成,每个Segment文件容量 ...
- 我的 Kafka 旅程 - Consumer
kafka采用Consumer消费者Pull主动拉取数据的方式,当Broker无数据时,消费者空转.Kafka并不删除已消费的消息,各自独立的消费者可消费同一个Broker分区数据. 消费流程 1.消 ...
- 我的 Kafka 旅程 - Producer
原理阐述 Producer生产者是数据的入口,它先将数据序列化后于内存的不同队列中,它用push模式再将内存中的数据发送到服务端的broker,以追加的方式到各自分区中存储.生产者端有两大线程,以先后 ...
- 我的 Kafka 旅程 - 性能调优
Producer 于 config/producer.properties 配置文件中的项 # 序列化数据压缩方式 [none/gzip/snappy/lz4/zstd] compression.ty ...
- Kafka权威指南——broker的常用配置
前面章节中的例子,用来作为单个节点的服务器示例是足够的,但是如果想要把它应用到生产环境,就远远不够了.在Kafka中有很多参数可以控制它的运行和工作.大部分的选项都可以忽略直接使用默认值就好,遇到一些 ...
- Kafka源码分析及图解原理之Broker端
一.前言 https://www.cnblogs.com/GrimMjx/p/11354987.html 上一节说过,任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer).消息消费者 ...
随机推荐
- Solution -「BZOJ3894」文理分科
Sol. 说实话,对于一个初学者,这道题很难看出是一道网络流-最小割.对于一个熟练者,这是比较套路的一种模型. 最小割,可以看做是在一个图中删掉最小的边权和使得源点.汇点不连通.或者换一个角度,可以看 ...
- docker部署练习
三个部署任务 docker部署nginx docker pull nginx #拉取nginx镜像 docker images #检查拉取的镜像 docker run -d -p 3344:80 -- ...
- 图文并茂演示小程序movable-view的可移动范围
前言 开发过小程序的同学可能对这两个内置组件并不陌生,他们配合用来实现在页面中可以拖拽滑动,其中: movable-area表示元素可移动的区域,它决定元素移动的区域范围 movable-view表示 ...
- GDOI 2022 普及组游记
To LuoguDAY -1 期中考成绩下来了,全无了除了历史 (96) 和生物 (95) 还能看,剩下的-,语文 101.5 ,少错一道选择和断句就 107.5 了,居然比雌兔还低 数学少错一道选择 ...
- 聊聊 C++ 中的几种智能指针 (下)
一:背景 上一篇我们聊到了C++ 的 auto_ptr ,有朋友说已经在 C++ 17 中被弃用了,感谢朋友提醒,今天我们来聊一下 C++ 11 中引入的几个智能指针. unique_ptr shar ...
- ESP8266 使用 DRV8833驱动板驱动N20电机
RT 手里这块ESP8266是涂鸦的板子,咸鱼上三块一个买了一堆,看ESP8266-12F引脚都差不多的.裸焊了个最小系统,加两个按钮(一个烧录,一个复位) 1. 准备工作 搜索过程中发现 DRV88 ...
- 第十九天python3 json和messagepack
json的数据类型官网:https://www.json.org/ 值: 双引号内的字符串,数值,true和false,null,对象,数组:字符串: 双引号内的任意字符的组合,可以有专一字符:数值: ...
- 丽泽普及2022交流赛day22 无社论
开始掉分模式 . T3 有人上费用流了???(id) 不用 TOC 了 . T1 暴力 T2 没看见 任意两圆不相交,gg 包含关系容易维护,特判相切 . 单调栈即可 T3 贪心 T4 神秘题
- Win10环境下使用Flask配合Celery异步推送实时/定时消息(Socket.io)/2020年最新攻略
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_163 首先得明确一点,和Django一样,在2020年Flask 1.1.1以后的版本都不需要所谓的三方库支持,即Flask-Ce ...
- SqlServer获取当前日期的详细写法
SqlServer获取当前日期1. 获取当前日期 select GETDATE()格式化: select CONVERT(varchar,GETDATE(),120) --2018-04-23 14: ...