selenium+python的网站爬虫
爬取网站听起来就是程序员的标配,之前一直没有时间学一下,最近有空学习一下顺便记录一下
爬取网站实际上就是利用计算机模拟人的操作来对网站的前端进行访问,而各大浏览器也给计算机提供了访问的接口,也就是浏览器驱动,计算机通过编写好的库访问浏览器驱动,就可以直接访问网页,但与人去访问不同的事,没有图形化的界面给计算机去进行点击的操作,选中输入框,输入文字,点击提交,这一系列操作的前提都是得先选中输入框,因此先了解计算机如何选中输入框的,以及如何定位到位置
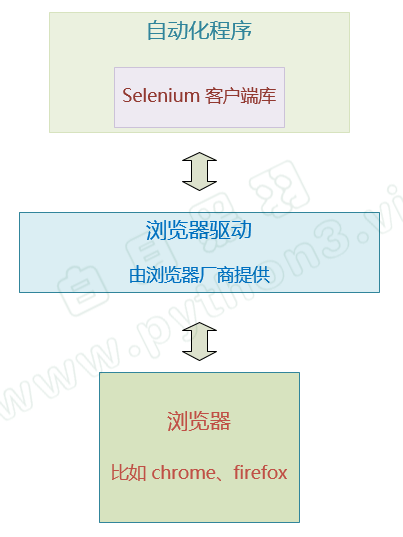
虽然呈现给用户的界面是图形化界面,但本质还是使用HTML、CSS和js来构建的,点击实际上也是触发了前端元素的事件,因此直接选择前端元素,和鼠标操作的目的是一样的
选择元素的两种方式:(1)使用元素的id、名称、类别进行直接选择,通过find_elements(By.ID,"ID")执行操作,与之相同的还有find_elements(By.CLASS_NAME,"class"),find_elements(By.TAG_NAME,"tagname")
#导入selenium
from selenium import webdriver
#导入对对应浏览器驱动的包,这里我使用的是微软的edge,不同的浏览器,驱动不同
from selenium.webdriver.edge.service import Service
#导入选择
from selenium.webdriver.common.by import By
#通过webdriver加载对应浏览器的驱动,这样需要加载全限定名,r表示后面的字符串不使用\转义,另一种方法是将路径加入到环境变量中,可以省去这一步
wb=webwebdriver.Edge(service=Service(r"D:\softwore in compile\Edge-driver\msedgedriver.exe"))
#让浏览器驱动加载一个页面,这个页面实际上就是一个html,如果这个html里还嵌套了一个html是无法访问的
wb.get("https://www.baidu.com/")
#选择了一个元素,并将之赋值给element
element=wb.find_elements(By.ID,"kw") #此时可以对element做操作,由于使用的是wb.find_elements,因此返回的是一个元素数组,
element[0].send_key("黑色")#此时向输入框输入了黑色两个字,但没有点击 element=wb.find_element(By.ID,"su")
element.click()#这里定位到了”百度一下“的元素,并执行了点击操作
(2)通过CSS选择器
类似于By.id方法,使用了By.CSS_SELECTOR,"参数”,不需要在前面规定参数到底是id还是Tag名称还是类,使用id作为参数时在以"#id"传参,使用类名时以 ”.类名“ 作为传参
在选择的元素内,依旧可以执行选择元素的操作,但是如果选择的元素是一个iframe或者是另一个html,就无法执行选择操作了,因为元素选择这个操作是使用加载了网页的webDriver来实现的,而最开始的webDriver加载的网页已经确定了,也就是已经绑定了一个html,这个时候要加载内部的iframe或者html,是属于另一个页面,需要执行wd.switch_to.frame(frame_reference)
其中, frame_reference 可以是 frame 元素的属性 name 或者 ID 。也可以填写frame 所对应的 WebElement 对象。
比如这里,就可以填写 iframe元素的id ‘frame1’ 或者 name属性值 ‘innerFrame’
selenium+python的网站爬虫的更多相关文章
- python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 2.请求资源列表页面,定位获得左侧目录每一章的跳转url(难点) 3.请求每个跳转url,定位右侧下载 ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用(转)
阅读目录 一.Selenium介绍 二.爬虫为什么要用selenium? 三.PhantomJS介绍 四.PhantomJS安装 五.操作实战 六.在此推荐虫师博客的学习资料 selenium + p ...
- selenium+python爬虫环境搭建
前言: 准备使用selenium爬取网站数据,先搭建selenium+python爬虫环境搭建 系统环境: 64位win10系统,同时装python2.7和python3.6两个版本,IDE为pych ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用
最近按公司要求,爬取相关网站时,发现没有找到js包的地址,我就采用selenium来爬取信息,相关实战链接:python爬虫实战(一)--------中国作物种质信息网 一.Selenium介绍 Se ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- selenium+python+eclipse 实现 “问卷星”网站,登录与检查登录示例!
1.使用selenium+python+eclipse实现的登录"问卷星",问卷星访问地址:https://www.sojump.com/ 2.实现步骤:1)进入链接---首页-- ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- 初探爬虫 ——《python 3 网络爬虫开发实践》读书笔记
零.背景 之前在 node.js 下写过一些爬虫,去做自己的私人网站和工具,但一直没有稍微深入的了解,借着此次公司的新项目,体系的学习下. 本文内容主要侧重介绍爬虫的概念.玩法.策略.不同工具的列举和 ...
随机推荐
- Javaweb-1note C/S B/S HTML CSS javaScript一点点语法
------------恢复内容开始------------ Java web概念: *javaweb:使用java语言开发基于互联网的项目 *软件架构: 1.c/s:Clienr/Server 客户 ...
- Maven依赖冲突解决总结
转载请注明出处: 1.Jar包冲突的通常表现 Jar包冲突往往是很诡异的事情,也很难排查,但也会有一些共性的表现. 抛出java.lang.ClassNotFoundException:典型异常,主要 ...
- Syntax Error: Error: Cannot find module ‘node-sass‘
出现问题原因: vscode运行前端项目输入npm run dev命令触发此错误 解决办法: 指定淘宝镜像安装node-sass win+r 打开cmd控制台输入 npm install -g cnp ...
- C++练习12 字符串成员函数的使用
1 #include <iostream> 2 #include <string> 3 using namespace std; 4 int main() 5 { 6 stri ...
- Redis(安装、启动、测试、环境)
Redis 概述: Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数 ...
- Fiegn 声明式接口调用
五:Fiegn 声明式接口调用 什么是Fiegn Netfix,Fiegn 是一个提供模板式的Web Service客户端,使用Fiegn 可以简化Web Service 客户端的编写,开发者可以通过 ...
- 字符串(str)内置方法补充、列表(list)内置方法、可变类型与不可变类型、队列和栈
目录 一.字符串(str)的内置方法(补充) 了解方法 二.列表(list)的内置方法 三.可变类型与不可变类型 四.队列和栈 一.字符串(str)的内置方法(补充) # upper()把当前字符串中 ...
- JZOJ 7392. 【2021.11.17NOIP提高组联考】数 (ds)
\(\text{Problem}\) 元素带类型与权值,每次修改权值或类型,求区间每种类型和的 \(k\) 次方和 强制在线 \(\text{Solution}\) 显然简单分块,根据询问需要发现要 ...
- 任何人均可上手的数据库与API搭建平台
编写API可能对于很多后端开发人员来说,并不是什么难事儿,但如果您主要从事前端功能,那么可能还是有一些门槛. 那么有没有工具可以帮助我们降低编写API的学习门槛和复杂度呢? 今天就来给大家推荐一个不错 ...
- label勾选问题,checkbox
<input id="overck_21" data-role="none" name="check" class="reg ...