selenium+python的网站爬虫
爬取网站听起来就是程序员的标配,之前一直没有时间学一下,最近有空学习一下顺便记录一下
爬取网站实际上就是利用计算机模拟人的操作来对网站的前端进行访问,而各大浏览器也给计算机提供了访问的接口,也就是浏览器驱动,计算机通过编写好的库访问浏览器驱动,就可以直接访问网页,但与人去访问不同的事,没有图形化的界面给计算机去进行点击的操作,选中输入框,输入文字,点击提交,这一系列操作的前提都是得先选中输入框,因此先了解计算机如何选中输入框的,以及如何定位到位置
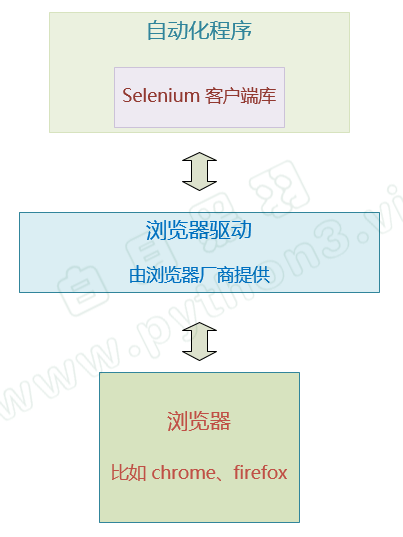
虽然呈现给用户的界面是图形化界面,但本质还是使用HTML、CSS和js来构建的,点击实际上也是触发了前端元素的事件,因此直接选择前端元素,和鼠标操作的目的是一样的
选择元素的两种方式:(1)使用元素的id、名称、类别进行直接选择,通过find_elements(By.ID,"ID")执行操作,与之相同的还有find_elements(By.CLASS_NAME,"class"),find_elements(By.TAG_NAME,"tagname")
#导入selenium
from selenium import webdriver
#导入对对应浏览器驱动的包,这里我使用的是微软的edge,不同的浏览器,驱动不同
from selenium.webdriver.edge.service import Service
#导入选择
from selenium.webdriver.common.by import By
#通过webdriver加载对应浏览器的驱动,这样需要加载全限定名,r表示后面的字符串不使用\转义,另一种方法是将路径加入到环境变量中,可以省去这一步
wb=webwebdriver.Edge(service=Service(r"D:\softwore in compile\Edge-driver\msedgedriver.exe"))
#让浏览器驱动加载一个页面,这个页面实际上就是一个html,如果这个html里还嵌套了一个html是无法访问的
wb.get("https://www.baidu.com/")
#选择了一个元素,并将之赋值给element
element=wb.find_elements(By.ID,"kw") #此时可以对element做操作,由于使用的是wb.find_elements,因此返回的是一个元素数组,
element[0].send_key("黑色")#此时向输入框输入了黑色两个字,但没有点击 element=wb.find_element(By.ID,"su")
element.click()#这里定位到了”百度一下“的元素,并执行了点击操作
(2)通过CSS选择器
类似于By.id方法,使用了By.CSS_SELECTOR,"参数”,不需要在前面规定参数到底是id还是Tag名称还是类,使用id作为参数时在以"#id"传参,使用类名时以 ”.类名“ 作为传参
在选择的元素内,依旧可以执行选择元素的操作,但是如果选择的元素是一个iframe或者是另一个html,就无法执行选择操作了,因为元素选择这个操作是使用加载了网页的webDriver来实现的,而最开始的webDriver加载的网页已经确定了,也就是已经绑定了一个html,这个时候要加载内部的iframe或者html,是属于另一个页面,需要执行wd.switch_to.frame(frame_reference)
其中, frame_reference 可以是 frame 元素的属性 name 或者 ID 。也可以填写frame 所对应的 WebElement 对象。
比如这里,就可以填写 iframe元素的id ‘frame1’ 或者 name属性值 ‘innerFrame’
selenium+python的网站爬虫的更多相关文章
- python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 2.请求资源列表页面,定位获得左侧目录每一章的跳转url(难点) 3.请求每个跳转url,定位右侧下载 ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用(转)
阅读目录 一.Selenium介绍 二.爬虫为什么要用selenium? 三.PhantomJS介绍 四.PhantomJS安装 五.操作实战 六.在此推荐虫师博客的学习资料 selenium + p ...
- selenium+python爬虫环境搭建
前言: 准备使用selenium爬取网站数据,先搭建selenium+python爬虫环境搭建 系统环境: 64位win10系统,同时装python2.7和python3.6两个版本,IDE为pych ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用
最近按公司要求,爬取相关网站时,发现没有找到js包的地址,我就采用selenium来爬取信息,相关实战链接:python爬虫实战(一)--------中国作物种质信息网 一.Selenium介绍 Se ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- selenium+python+eclipse 实现 “问卷星”网站,登录与检查登录示例!
1.使用selenium+python+eclipse实现的登录"问卷星",问卷星访问地址:https://www.sojump.com/ 2.实现步骤:1)进入链接---首页-- ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- 初探爬虫 ——《python 3 网络爬虫开发实践》读书笔记
零.背景 之前在 node.js 下写过一些爬虫,去做自己的私人网站和工具,但一直没有稍微深入的了解,借着此次公司的新项目,体系的学习下. 本文内容主要侧重介绍爬虫的概念.玩法.策略.不同工具的列举和 ...
随机推荐
- 2.1.新建项目及项目目录和预览uni项目
目录结构 一个uni-app工程,默认包含如下目录及文件 static目录 使用注意 编译到任意平台时,static 目录下除不满足条件编译的文件,会直接复制到最终的打包目录,不会打包编译.非 sta ...
- 使用 DirectSound 录制麦克风音频
使用 DirectSound 录制麦克风音频 本文所有代码均可在以下仓库找到 https://gitcode.net/PeaZomboss/learnaudios 目录是demo/dscapture ...
- 如何使用 ArrayPool
如果不停的 new 数组,可能会造成 GC 的压力,因此在 aspnetcore 中推荐使用 ArrayPool 来重用数组,本文将介绍如何使用 ArrayPool. 使用 ArrayPool Arr ...
- Spring Boot自动配置原理懂后轻松写一个自己的starter
目前很多Spring项目的开发都会直接用到Spring Boot.因为Spring原生开发需要加太多的配置,而使用Spring Boot开发很容易上手,只需遵循Spring Boot开发的约定就行了, ...
- 深度学习-LSTM
目录 前言 神经网络的历史和背景 循环神经网络的出现及其作用 LSTM在处理序列数据中的应用 LSTM的基本原理 LSTM的结构和原理 遗忘门.输入门.输出门的作用 LSTM的训练方法 代码 LSTM ...
- JZOJ 1495. 宝石
题目大意 用边长为 \(k\) 的正方形在平面内覆盖,求它能覆盖的最大点权和 思路 \(60\) 分:其实很容易想到按它们的横坐标先后排序,然后单调队列维护.复杂度 \(O(n k \log k)\) ...
- VueJs 监听 window.resize 方法---窗口变化
mounted() { let _this = this; window.onresize = ()=>{ return (()=>{ this.vscreen.height=docume ...
- 中后端做Excel导出功能返回数据流前端如何做处理
exportFile(params).then(res => { // 直接返回来就是blob数据 if (res) { const xlsx = 'application/vnd.ms-exc ...
- 在Unity中对森林植被进行优化
https://www.163.com/dy/article/DP6665QP0526E124.html
- centos7配置vue环境
1.安装nodejs #下载源码 wget https://npm.taobao.org/mirrors/node/v14.15.4/node-v14.15.4-linux-x64.tar.xz #解 ...