Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一、前言
在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个:
1. 分布式全局唯一id
2. 分片规则和策略
3. 跨分片技术问题
4. 跨分片事物问题
下面我们来看一下Mycat是如何解决分布式全局唯一id的问题的
二、Mycat全局序列号
Mycat保证id唯一的方式有如下几个:
1)本地文件方式
2)数据库方式
3)时间戳方式
4)ZKID生成器
5)ZK递增ID
推荐使用第4,5种
以上5中方式都要统一在server.xml文件中开启全局序列号的配置和在schema.xml文件中配置逻辑表的autoIncrement属性为true(2个必须步骤)
1)sequnceHandlerType进行相应全局序列号策略选项设置(server.xml),在mycat中对应的源码是MyCATSequnceProcessor.java
<property name="sequnceHandlerType">0</property>
sequnceHandlerType可取的值有以下几个:
0:本地文件方式
1:数据库方式
2:时间戳方式
3:ZKID生成器
4:ZK递增ID
2)autoIncrement属性为true(schema.xml)
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long" />
1. 本地文件方式
使用到的mycat源码:io.mycat.route.sequence.handler.IncrSequenceHandler
在server.xml文件中开启全局序列号的配置:
<property name="sequnceHandlerType">0</property>
使用到的配置文件:sequence_conf.properties
#default global sequence
GLOBAL.HISIDS=
GLOBAL.MINID=10001
GLOBAL.MAXID=20000
GLOBAL.CURID=10000 # self define sequence
COMPANY.HISIDS=
COMPANY.MINID=1001
COMPANY.MAXID=2000
COMPANY.CURID=1000 CUSTOMER.HISIDS=
CUSTOMER.MINID=1001
CUSTOMER.MAXID=2000
CUSTOMER.CURID=1000 ORDER.HISIDS=
ORDER.MINID=1001
ORDER.MAXID=2000
ORDER.CURID=1000 HOTNEWS.HISIDS=
HOTNEWS.MINID=1001
HOTNEWS.MAXID=2000
HOTNEWS.CURID=1000
拿HOTNEWS这个表的配置来说明:
HOTNEWS.HISIDS= #HOTNEWS这张表历史使用的自增id,一般不配置
HOTNEWS.MINID=1001 #HOTNEWS这张表使用的最小自增id
HOTNEWS.MAXID=2000 #HOTNEWS这张表使用的最大自增id
HOTNEWS.CURID=1000 #HOTNEWS这张表当前使用的自增id
缺点:当Mycat重新发布后,自增ID恢复到初始值。原因是因为sequnceHandlerType定义的是静态变量,不推荐使用
示例:
1.1 在mycat的schema.xml文件里面分别配置逻辑表hotnews和mysql的主从机,注意autoIncrement="true"才能使用全局唯一id
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long" />
<dataNode name="dn1" dataHost="centos1" database="db1" />
<dataNode name="dn2" dataHost="centos1" database="db2" />
<dataNode name="dn3" dataHost="centos1" database="db3" />
<dataHost name="centos1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.152.130:3306" user="root" password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.152.131:3306" user="root" password="123456" />
</writeHost>
<!-- <writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" />-->
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
1.2 在主数据库(192.168.152.130)分别创建3个数据库db1,db2,db3,然后创建hotnews表
create database db1;
use db1;
create table hotnews(
id bigint(20) not null primary key auto_increment,
title varchar(50) default null );
create database db2;
use db2;
create table hotnews(
id bigint(20) not null primary key auto_increment,
title varchar(50) default null );
create database db3;
use db3;
create table hotnews(
id bigint(20) not null primary key auto_increment,
title varchar(50) default null );
1.3 插入数据
插入数据到hotnews前我们先来看一下使用本地文件方式的配置文件sequence_conf.properties的内容
cat sequence_conf.properties |grep HOTNEWS

插入数据到hotnews
insert into hotnews(id, title) values(next value for MYCATSEQ_HOTNEWS, 'test1');
insert into hotnews(id, title) values(next value for MYCATSEQ_HOTNEWS, 'test2');
insert into hotnews(id, title) values(next value for MYCATSEQ_HOTNEWS, 'test3');
1.4 查看hotnews表的结果
select * from hotnews;
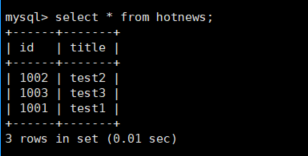
再次查看配置文件sequence_conf.properties的内容,发现内容随着插入数据的自增id做了改变

2. 数据库方式
这种方式和本地文件的方式是一样的,只是把sequence_conf.properties的内容用数据库来管理
使用到的mycat源码:io.mycat.route.sequence.handler.IncrSequenceMySQLHandler
这里还是以hotnews表为例
2.1 在server.xml文件中开启全局序列号的配置:
<property name="sequnceHandlerType">1</property>
使用到的配置文件:sequence_db_conf.properties
vim sequence_db_conf.properties
#sequence stored in datanode
GLOBAL=dn1
COMPANY=dn1
CUSTOMER=dn1
ORDERS=dn1
2.2 选择其中的一个分片,执行如下步骤,譬如我在dn1中创建,对应的数据库名为db1(为什么这里会涉及到datanode,因为后续的sequence_db_conf.properties文件会使用到),注意:是登录到数据库中创建,而不是在mycat中创建
第一步:创建SEQUENCE表,用来存储序列号
use db1;
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE MYCAT_SEQUENCE (
NAME VARCHAR (50) NOT NULL, /*全局SEQ名称*/
current_value INT NOT NULL, /*当前序列ID*/
increment INT NOT NULL DEFAULT 100, /*初始序列ID*/
PRIMARY KEY (NAME)
) ENGINE = INNODB ;
INSERT INTO MYCAT_SEQUENCE(name,current_value,increment) VALUES ('GLOBAL', 100000, 100);
第二步:创建SEQ function
-- 获取当前sequence的值(返回当前值,增量)
DROP FUNCTION IF EXISTS `mycat_seq_currval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_currval`(seq_name VARCHAR(50))
RETURNS varchar(64) CHARSET utf8
DETERMINISTIC
BEGIN DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT concat(CAST(current_value AS CHAR),",",CAST(increment AS CHAR) ) INTO retval
FROM MYCAT_SEQUENCE WHERE name = seq_name;
RETURN retval ;
END
;;
DELIMITER ; -- 获取下一个sequence值
DROP FUNCTION IF EXISTS `mycat_seq_nextval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_nextval`(seq_name VARCHAR(50)) RETURNS varchar(64)
CHARSET utf8
DETERMINISTIC
BEGIN UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ; -- 设置sequence值
DROP FUNCTION IF EXISTS `mycat_seq_setval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_setval`(seq_name VARCHAR(50), value INTEGER)
RETURNS varchar(64) CHARSET utf8
DETERMINISTIC
BEGIN UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
插入需要自增长的表的策略,这条数据是我们hotnews这个表所需要的。 name必须是大写的字符,不然就会报错
insert into MYCAT_SEQUENCE values('HOTNEWS','','');
说明:插入了一个名为HOTNEWS的sequence,当前值为101,步长为100。当插入第一条数据时id为201,后面每插入一条数据id加1
第三步:在sequence_db_conf.properties这个文件中定义hotnews这张表的序列名称,同时可以定义到哪个分片上。这里是定义在dn1上的
名字=分片1[,分片2][,.....][,分片N]
vim sequence_db_conf.properties
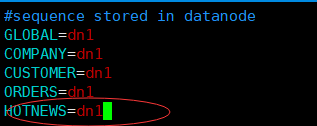
保存:
:wq
2.3 重启mycat
[root@centos1 mycat]# ./bin/mycat restart;
2.4 连接mycat进行数据测试
mysql -uroot -p123456 -P8066 -h192.168.152.128
插入数据
insert into hotnews(id, title) values(next value for MYCATSEQ_HOTNEWS, 'test11111');
insert into hotnews(id, title) values(next value for MYCATSEQ_HOTNEWS, 'test11112');
insert into hotnews(id, title) values(next value for MYCATSEQ_HOTNEWS, 'test11113');
查看结果:
select * from hotnews;
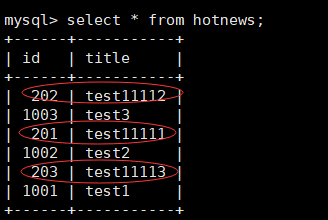
缺点:当mycat挂掉时可能出现主键冲突。不推荐使用
3. 本地时间戳方式
使用到的mycat源码:io.mycat.route.sequence.handler.IncrSequenceTimeHandler
3.1 在server.xml文件中开启全局序列号的配置:
<property name="sequnceHandlerType">2</property>
使用到的配置文件:
sequence_time_conf.properties
WORKID=01(范围01-31)
DATAACENTERID=01(范围01-31)
示例:
首先清空hotnews这张表的数据,方便查看测试结果
delete from hotnews;
插入测试数据
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test11111');
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test11112');
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test11113');
查看结果:
select * from hotnews;
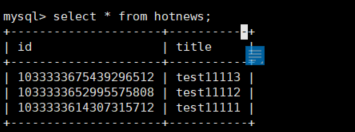
优点:不存在id重复的现象。
缺点:主键太长。时间可能被重置。没有特殊要求的场景可以使用
4. 自增长主键
方式1:不同自增长初始值+相同步长
方式2:参考“数据库方式”
5. 分布式ZK ID生成(推荐使用)
使用到的mycat源码:
io.mycat.route.sequence.handler.IncrSequenceZKHandler
io.mycat.route.sequence.handler.DistributedSequenceHandler
环境准备:先在虚拟机192.168.152.130里面装好zookeeper,具体参考我的文章 搭建dubbo+zookeeper+dubboadmin分布式服务框架(windows平台下)
5.1 在server.xml文件中开启全局序列号的配置:
vim server.xml
<property name="sequnceHandlerType">3</property>
5.2 修改如下配置文件:
1)myid.properties
vim myid.properties
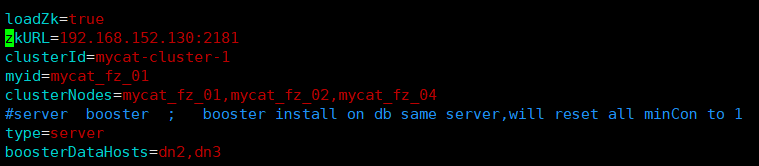
配置文件说明:
loadZK=true|false //是否使用zk序列生成器
zkURL=xxx.xxx.xxx.xxx:2182,xxx.xxx.xxx.xxx:2182,xxx.xxx.xxx.xxx:2182
clusterId=集群名称
2)sequence_distributed_conf.properties
vim sequence_distributed_conf.properties
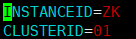
配置文件说明:
INSTANCEID=ZK //改成“ZK”(默认是01)
CLUSTERID=01 //集群编号
5.3 重启mycat
[root@centos1 mycat]# ./bin/mycat restart;
5.4 连接mycat进行数据测试
mysql -uroot -p123456 -P8066 -h192.168.152.128
插入数据
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test00000001');
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test00000002');
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test00000003');
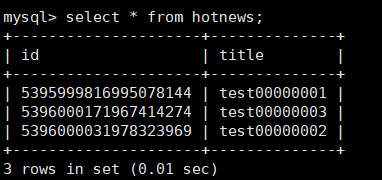
查看结果:
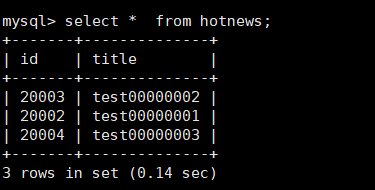
select * from hotnews;
6. ZK递增方式(推荐使用)
使用到的mycat源码:io.mycat.route.sequence.handler.IncrSequenceZKHandler
6.1 在server.xml文件中开启全局序列号的配置:
vim server.xml
<property name="sequnceHandlerType">4</property>
使用到的配置文件:
1) myid.properties 参考“5. 分布式ZK ID生成器”中的介绍。
2) sequence_conf.properties
HOTNEWS.HISIDS= #HOTNEWS这张表历史使用的自增id,一般不配置
HOTNEWS.MINID=1001 #zk使用的区间内最小值
HOTNEWS.MAXID=2000 #zk使用的区间内最大值
HOTNEWS.CURID=1000 #zk使用的区间内当前值
说明:
以hotnews为例,然后根据sequence_conf.properties里面的hotnews的配置取MAXID和MINID的偏移量(这里是1000)作为id的增量值,当插入数据时把这1000个值用完了在继续取MAXID和MINID的偏移量
6.2 重启mycat
[root@centos1 mycat]# ./bin/mycat restart;
6.3 连接mycat进行数据测试
mysql -uroot -p123456 -P8066 -h192.168.152.128
插入数据
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test00000001');
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test00000002');
insert into hotnews(id, title) values(next value for MYCATSEQ_GLOBAL, 'test00000003');
查看结果:
select * from hotnews;
Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案的更多相关文章
- MySQL纯透明的分库分表技术还没有
MySQL纯透明的分库分表技术还没有 种树人./oneproxy --proxy-address=:3307 --admin-username=admin --admin-password=D033 ...
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
<sharding-jdbc 分库分表的 4种分片策略> 中我们介绍了 sharding-jdbc 4种分片策略的使用场景,可以满足基础的分片功能开发,这篇我们来看看分库分表后,应该如何为 ...
- 分库分表的情况下生成全局唯一的ID
分库分表情况下 跨库的问题怎么解决? 分布式事务怎么解决? 查询结果集集合合并的问题? 全局唯一的id怎么解决? 一般要求:1.保证生成的ID全局唯一,不可重复 2.生成的后一个Id必须大于前一个Id ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- Mysql中的分库分表
mysql中的分库分表分库:减少并发问题分表:降低了分布式事务分表 1.垂直分表 把其中的不常用的基础信息提取出来,放到一个表中通过id进行关联.降低表的大小来控制性能,但是这种方式没有解决高数据量带 ...
- Mycat安装并实现mysql读写分离,分库分表
Mycat安装并实现mysql读写分离,分库分表 一.安装Mycat 1.1 创建文件夹 1.2 下载 二.mycat具体配置 2.1 server.xml 2.2 schema.xml 2.3 se ...
- Docker安装Mycat并实现mysql读写分离,分库分表
Docker安装Mycat并实现mysql读写分离,分库分表 一.拉取mycat镜像 二.准备挂载的配置文件 2.1 创建文件夹并添加配置文件 2.1.1 server.xml 2.1.2 serve ...
- DB 分库分表(2):全局主键生成策略
DB 分库分表(2):全局主键生成策略 本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案.关于分库分表(sharding)的拆分策略和实施细则,请 ...
- (4.24)【mysql、sql server】分布式全局唯一ID生成方案
参考:分布式全局唯一ID生成方案:https://blog.csdn.net/linzhiqiang0316/article/details/80425437 分表生成唯一ID方案 sql serve ...
随机推荐
- BZOJ.2639.矩形计算(二维莫队)
题目链接 二维莫队,按x,y坐标一起分块.(x,y)的所属的块为 x/sq(n)*sq(m) + y/sq(m) 排序时按照(左下点所在块,右上点的标号)排序 排序后 先得出一个询问的答案,然后利用上 ...
- Cocos Creator代码编辑环境配置
1,可以使用较为适合js的webstorm,亦可以采用VS: 2,若需要webstorm,在下载之后,在文件,设置内外部编辑器选用webstorm.exe,即可: 3,Visual Studio Co ...
- C# try catch finally简单介绍和应用
今天看代码书的时候,有用到try--catch--finally,然后就查了下具体的注意事项和应用. 简单来说就是: try { //有可能出错误的代码或者代码片段 } catch{ // ...
- 一道面试题 包含了new的细节 和运算符的优先级 还有属性访问机制
function Foo() { getName = function () { alert(1); } return this; } Foo.getName = function () { aler ...
- Iowait的成因、对系统影响及对策--systemtap
http://blog.csdn.net/yunlianglinfeng/article/details/51698607
- IOS 数据存储之 FMDB 详解
FMDB是用于进行数据存储的第三方的框架,它与SQLite与Core Data相比较,存在很多优势. FMDB是面向对象的,它以OC的方式封装了SQLite的C语言API,使用起来更加的方便,不需要过 ...
- 微软BI 之SSAS 系列 - 多维数据集维度用法之一 引用维度 Referenced Dimension
在 CUBE 设计过程中有一个非常重要的点就是定义维度与度量值组关系,维度的创建一般在前,而度量值组一般来源于一个事实表.当维度和度量值组在 CUBE 中定义完成之后,下一个最重要的动作就是定义两者之 ...
- toml
其目标是成为一个小规模的易于使用的语义化配置文件格式.TOML被设计为可以无二义性的转换为一个哈希表(Hash table). # 这是一个TOML文件 title = "TOML Exam ...
- top命令详析及排查问题使用演示
1. top基本使用 top命令运行图 第一行:基本信息 第二行:任务信息 第三行:CPU使用情况 第四行:物理内存使用情况 buff/cache: buffers 和 cache 都是内存中存放的数 ...
- gcc/g++ disable warnings in particular include files
当在编译一个大项目的时候,你想打开所有的Warning,但是打开后发现一堆公共库文件都出现了warning报错.此时如果你想忽略公共库头文件中的warning报错,只需要在编译的时候,将公共库头文件的 ...