推荐系统之LFM
这里我想给大家介绍另外一种推荐系统,这种算法叫做潜在因子(Latent Factor)算法。这种算法是在NetFlix(没错,就是用大数据捧火《纸牌屋》的那家公司)的推荐算法竞赛中获奖的算法,最早被应用于电影推荐中。这种算法在实际应用中比现在排名第一的 @邰原朗 所介绍的算法误差(RMSE)会小不少,效率更高。我下面仅利用基础的矩阵知识来介绍下这种算法。
这种算法的思想是这样:每个用户(user)都有自己的偏好,比如A喜欢带有小清新的、吉他伴奏的、王菲等元素(latent factor),如果一首歌(item)带有这些元素,那么就将这首歌推荐给该用户,也就是用元素去连接用户和音乐。每个人对不同的元素偏好不同,而每首歌包含的元素也不一样。我们希望能找到这样两个矩阵:
一.用户-潜在因子矩阵Q,
表示不同的用户对于不用元素的偏好程度,1代表很喜欢,0代表不喜欢。比如下面这样:
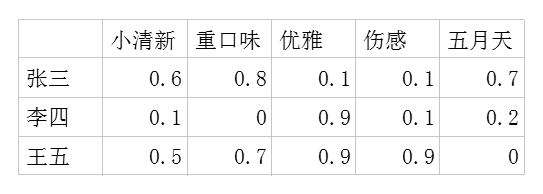
二.潜在因子-音乐矩阵P
表示每种音乐含有各种元素的成分,比如下表中,音乐A是一个偏小清新的音乐,含有小清新这个Latent Factor的成分是0.9,重口味的成分是0.1,优雅的成分是0.2……
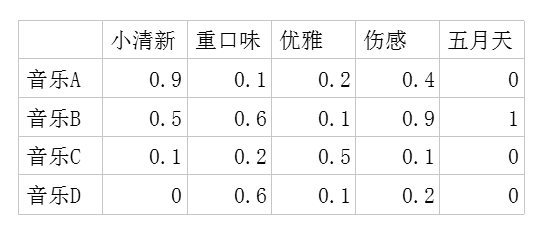
利用这两个矩阵,我们能得出张三对音乐A的喜欢程度是:张三对小清新的偏好*音乐A含有小清新的成分+对重口味的偏好*音乐A含有重口味的成分+对优雅的偏好*音乐A含有优雅的成分+……
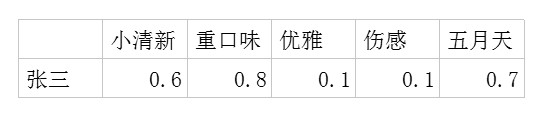
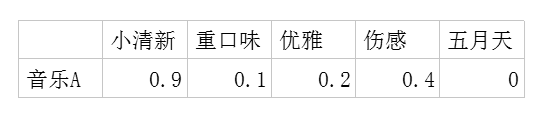
即:0.6*0.9+0.8*0.1+0.1*0.2+0.1*0.4+0.7*0=0.69
每个用户对每首歌都这样计算可以得到不同用户对不同歌曲的评分矩阵。(注,这里的破浪线表示的是估计的评分,接下来我们还会用到不带波浪线的R表示实际的评分):
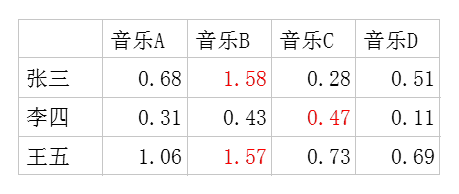
因此我们队张三推荐四首歌中得分最高的B,对李四推荐得分最高的C,王五推荐B。
如果用矩阵表示即为:
下面问题来了,这个潜在因子(latent factor)是怎么得到的呢?
由于面对海量的让用户自己给音乐分类并告诉我们自己的偏好系数显然是不现实的,事实上我们能获得的数据只有用户行为数据。我们沿用 @邰原朗的量化标准:单曲循环=5, 分享=4, 收藏=3, 主动播放=2 , 听完=1, 跳过=-2 , 拉黑=-5,在分析时能获得的实际评分矩阵R,也就是输入矩阵大概是这个样子: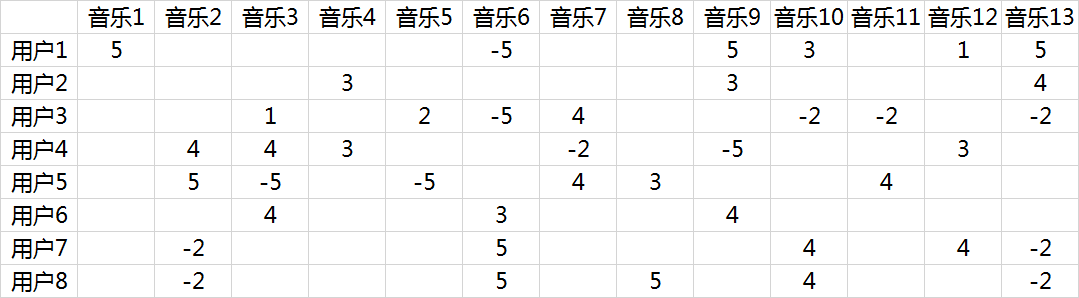
事实上这是个非常非常稀疏的矩阵,因为大部分用户只听过全部音乐中很少一部分。如何利用这个矩阵去找潜在因子呢?这里主要应用到的是矩阵的UV分解。也就是将上面的评分矩阵分解为两个低维度的矩阵,用Q和P两个矩阵的乘积去估计实际的评分矩阵,而且我们希望估计的评分矩阵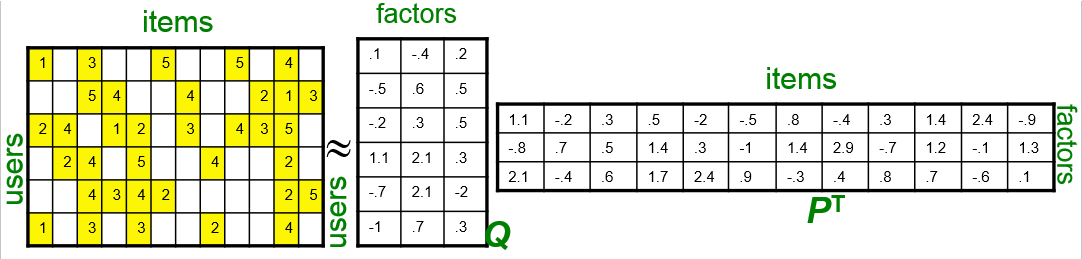
和实际的评分矩阵不要相差太多,也就是求解下面的目标函数:
这里涉及到最优化理论,在实际应用中,往往还要在后面加上2范数的罚项,然后利用梯度下降法就可以求得这P,Q两个矩阵的估计值。这里我们就不展开说了。例如我们上面给出的那个例子可以分解成为这样两个矩阵: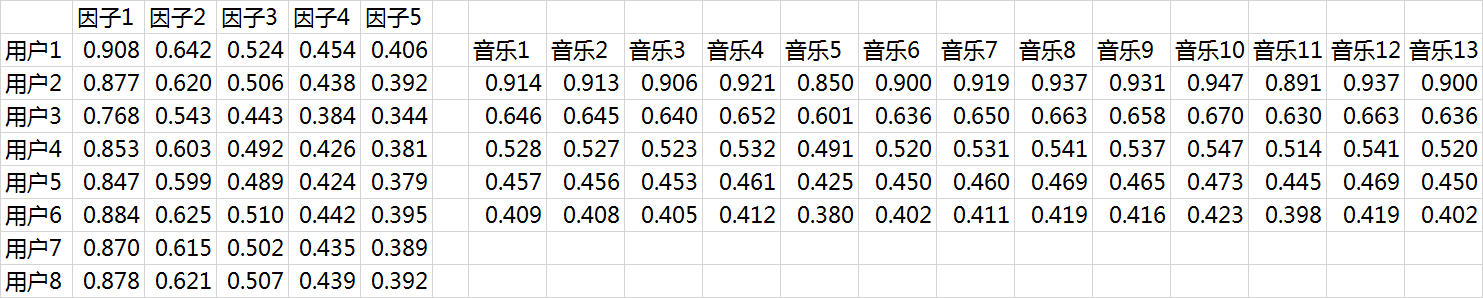 这两个矩阵相乘就可以得到估计的得分矩阵:
这两个矩阵相乘就可以得到估计的得分矩阵: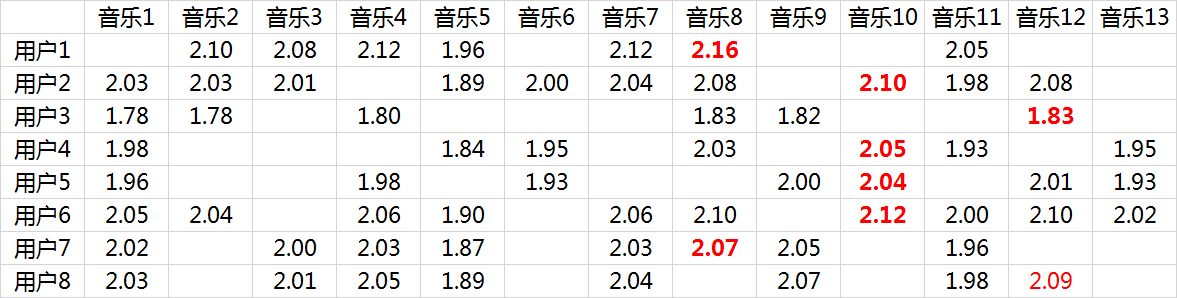 将用户已经听过的音乐剔除后,选择分数最高音乐的推荐给用户即可(红体字)。
将用户已经听过的音乐剔除后,选择分数最高音乐的推荐给用户即可(红体字)。
在这个例子里面用户7和用户8有强的相似性: 从推荐的结果来看,正好推荐的是对方评分较高的音乐:
从推荐的结果来看,正好推荐的是对方评分较高的音乐:
推荐系统之LFM的更多相关文章
- 推荐系统之LFM(二)
对于一个用户来说,他们可能有不同的兴趣.就以作者举的豆瓣书单的例子来说,用户A会关注数学,历史,计算机方面的书,用户B喜欢机器学习,编程语言,离散数学方面的书, 用户C喜欢大师Knuth, Jiawe ...
- 推荐系统 LFM 算法的简单理解,感觉比大部分网上抄来抄去的文章好理解
本文主要是基于<推荐系统实践>这本书的读书笔记,还没有实践这些算法. LFM算法是属于隐含语义模型的算法,不同于基于邻域的推荐算法. 隐含语义模型有:LFM,LDA,Topic Model ...
- 推荐系统之隐语义模型(LFM)
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型.那这种模型跟ItemCF或UserCF的不同在于: 对于UserCF,我们可以先计算和目标用户兴趣 ...
- 推荐系统第5周--- 基于内容的推荐,隐语义模型LFM
基于内容的推荐
- 推荐系统之隐语义模型LFM
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型.那这种模型跟ItemCF或UserCF的不同在于: 对于UserCF,我们可以先计算和目标用户兴趣 ...
- 推荐系统--隐语义模型LFM
主要介绍 隐语义模型 LFM(latent factor model). 隐语义模型最早在文本挖掘领域被提出,用于找到文本的隐含语义,相关名词有 LSI.pLSA.LDA 等.在推荐领域,隐语义模型也 ...
- 隐语义模型LFM(latent factor model)
对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品.总结一下,这个基于兴趣分类的方法大概需要解决3个问题. 如何给物品进行分类? 如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度? ...
- 【转载】使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- 使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
随机推荐
- jQuery在HTML文档加载完毕后自动执行某个事件;
原来onchange=“fucntionname(parms)”: <select name="country" id="selCountries_{$sn}&qu ...
- 旋转转盘选择Menu--第三方开源--CircleMenu
CircleMenu在github上的项目主页是:https://github.com/zhangphil/Android-CircleMenu CircleMenu用法简单,JAVA代码: pack ...
- cxGrid使用汇总(一)
1. 去掉cxGrid中台头的Box 解决:在tableview1的ptionsview的groupbybox=false; 2.统计功能 解决:(1) tableview 1. tableview1 ...
- 02-线性结构3 Pop Sequence
Given a stack which can keep M numbers at most. Push N numbers in the order of 1, 2, 3, ..., N and p ...
- IEnumerable 接口 实现foreach 遍历 实例
额 为啥写着东西? 有次面试去,因为用到的时候特别少 所以没记住, 这个单词 怎么写! 经典的面试题: 能用foreach遍历访问的对象的要求? 答: 该类实现IEnumetable 接口 声明 ...
- IL中的栈和闪电的Owin推荐
最近几天有幸得到闪电大哥的指点,了解了EMIT和IL中的一些指令.虽然有高射炮打蚊子的说法,但是我相信“二八定律”,80%的功能可以用20%的技术解决,20%的功能只能用80%的技术解决.大哥的博客: ...
- 002-python基础-hello-world
python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行. 如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需 ...
- [转]Openwrt的Inittab
转来一篇关于启动的文章,特意收藏.http://see.sl088.com/wiki/Inittab 文件位于/etc/inittab编辑方法vi /etc/inittab初始内容::sysinit: ...
- SoundCloud 的开发功能
SoundCloud开发功能:https://developers.soundcloud.com/docs 来自为知笔记(Wiz)
- React Native分析(index.ios.js)
定义创建组件MyComponent(index.ios.js): 'use strict' var React = require('react-native'); var { AppRegistry ...