Storm概念学习系列之storm的设计思想
不多说,直接上干货!
storm的设计思想
在 Storm 中也有对流(Stream)的抽象,流是一个不间断的、无界的连续 Tuple(Storm在建模事件流时,把流中的事件抽象为 Tuple 即元组)。Storm 认为每个流都有一个 Stream 源,也就是原始元组的源头,所以它将这个源头抽象为 Spout, Spout 可能连接 Twitter API 并不断发出推文( Tweet),也可能从某个队列中不断读取队列元素并装配为 Tuple 发射。
有了源头即 Spout 也就是有了流,同样的思想, Twitter 将流的中间状态转换抽象为Bolt, Bolt 可以消费任意数量的输入流,只要将流方向导向该 Bolt,同时它也可以发送新的流给其他 Bolt 使用,这样一来,只要打开特定的 Spout(管口),再将 Spout 中流出的 Tuple导向特定的 Bolt,由 Bolt 处理导入的流后再导向其他 Bolt 或者目的地。
假设 Spout 就是一个一个的水龙头,并且每个水龙头里流出的水是不同的,想获得哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(Bolt),水处理器处理后使用管道导向另一个处理器或者存入容器中。图 1 和图 2 为 Spout、 Tuple 和 Bolt 之间的关系和流程。

图 1 Spout、 Bolt 顺序处理数据流图
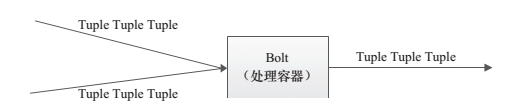
图2 Bolt 多输入数据流图
为了增大水处理效率,可以在同一个水源处接上多个水龙头并使用多个水处理器,如图 3 所示。
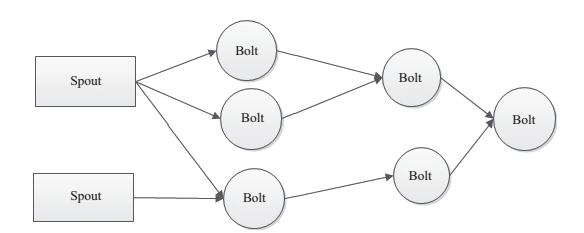
图 3 多 Spout、多 Bolt 处理流程图
对应上文的介绍,可以很容易地理解图 3,这是一张有向无环图。 Storm 将这个图抽象为 Topology(即拓扑),拓扑是 Storm 中最高层次的一个抽象概念,提交拓扑到 Storm 集群执行,一个拓扑就是一个流转换图。图中的每个节点是一个 Spout 或者 Bolt,图中的边是指Bolt 订阅了哪些流
Storm概念学习系列之storm的设计思想的更多相关文章
- Storm概念学习系列之storm的雪崩
不多说,直接上干货! Storm的雪崩问题的解决办法1: Storm概念学习系列之并行度与如何提高storm的并行度 Storm的雪崩问题的解决办法2:
- Storm概念学习系列之storm流程图
把stream当做一列火车, tuple当做车厢,spout当做始发站,bolt当做是中间站点!!! 见 Storm概念学习系列之Spout数据源 Storm概念学习系列之Topology拓扑 Sto ...
- Storm概念学习系列之storm的定时任务
不多说,直接上干货! 至于为什么,有storm的定时任务.这个很简单.但是,这个在工作中非常重要! 假设有如下的业务场景 这个spoult源源不断地发送数据,boilt呢会进行处理.然后呢,处理后的结 ...
- Storm概念学习系列之storm的可靠性
这个概念,对于理解storm很有必要. 1.worker进程死掉 worker是真实存在的.可以jps查看. 正是因为有了storm的可靠性,所以storm会重新启动一个新的worker进程. 2.s ...
- Storm概念学习系列之storm核心组件
不多说,直接上干货! Storm核心组件 了解 Storm 的核心组件对于理解 Storm 原理非常重要,下面介绍 Storm 的整体,然后介绍 Storm 的核心. Storm 集群由一个主节点和多 ...
- Storm概念学习系列之storm简介
不多说,直接上干货! storm简介 Storm 是 Twitter 开源的.分布式的.容错的实时计算系统,遵循 Eclipse Public License1.0. Storm 通过简单的 API ...
- Storm概念学习系列之storm的功能和三大应用
不多说,直接上干货! storm的功能 Storm 有许多应用领域:实时分析.在线机器学习.持续计算.分布式 RPC(远过程调用协议,一种通过网络从远程计算机程序上请求服务). ETL(Extract ...
- Storm概念学习系列之storm的特性
不多说,直接上干货! storm的特性 Storm 是一个开源的分布式实时计算系统,可以简单.可靠地处理大量的数据流. Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快 ...
- Storm概念学习系列之Storm与Hadoop的角色和组件比较
不多说,直接上干货! Storm与Hadoop的角色和组件比较 Storm 集群和 Hadoop 集群表面上看很类似.但是 Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行 ...
随机推荐
- [转]Unity3D学习笔记(四)天空、光晕和迷雾
原文地址:http://bbs.9ria.com/thread-186942-1-1.html 作者:江湖风云 六年前第一次接触<魔兽世界>的时候,被其绚丽的画面所折服,一个叫做贫瘠之地的 ...
- 【转】 Pro Android学习笔记(六五):安全和权限(2):权限和自定义权限
目录(?)[-] 进程边界 声明和使用权限 AndroidManifestxml的许可设置 自定义权限 运行安全通过两个层面进行保护.进程层面:不同应用运行在不同的进程,每个应用有独自的user ID ...
- spark提交模式
spark基本的提交语句: ./bin/spark-submit \ --class <main-class> \ --master <master-url> \ --depl ...
- hibernate 数据关联一对多
一对多,多对一 (在多的一端存放一的外键) 但是在实体类中不需要创建这个外键 // 在一的一方创建Set集合 public class User { private Integer id; priva ...
- HBase 二级索引与Coprocessor协处理器
Coprocessor简介 (1)实现目的 HBase无法轻易建立“二级索引”: 执行求和.计数.排序等操作比较困难,必须通过MapReduce/Spark实现,对于简单的统计或聚合计算时,可能会因为 ...
- 03.generator
generatorConfig.xml自动生成连接数据库的这些个公共类的方法. <?xml version="1.0" encoding="UTF-8" ...
- 在PCL中如何实现点云压缩(2)
博客转载自:http://www.pclcn.org/study/shownews.php?lang=cn&id=125 压缩配置文件: 压缩配置文件为PCL点云编码器定义了参数集.并针对压缩 ...
- mahout过滤推荐结果 Recommender.recommend(long userID, int howMany, IDRescorer rescorer)
Recommender.recommend(uid, RECOMMENDER_NUM, rescorer); Recommender.recommend(long userID, int howMan ...
- 关于C/C++中的“auto”关键字
C/C++ 98标准 C++03标准 早在C++98标准中就存在了auto关键字,那时的auto用于声明变量为自动变量,自动变量意为拥有自动的生命期.此用法是多余的,因为即使定义变量时不加" ...
- 32.我的wafBypass之道
0x01 搞起 当我们遇到一个waf时,要确定是什么类型的?先来看看主流的这些waf,狗.盾.神. 锁.宝.卫士等等...(在测试时不要只在官网测试,因为存在版本差异导致规则库并不一致) 1.云waf ...