hadoop学习day3 mapreduce笔记
1.对于要处理的文件集合会根据设定大小将文件分块,每个文件分成多块,不是把所有文件合并再根据大小分块,每个文件的最后一块都可能比设定的大小要小
块大小128m
a.txt 120m 1个块
b.txt 500m 4个块
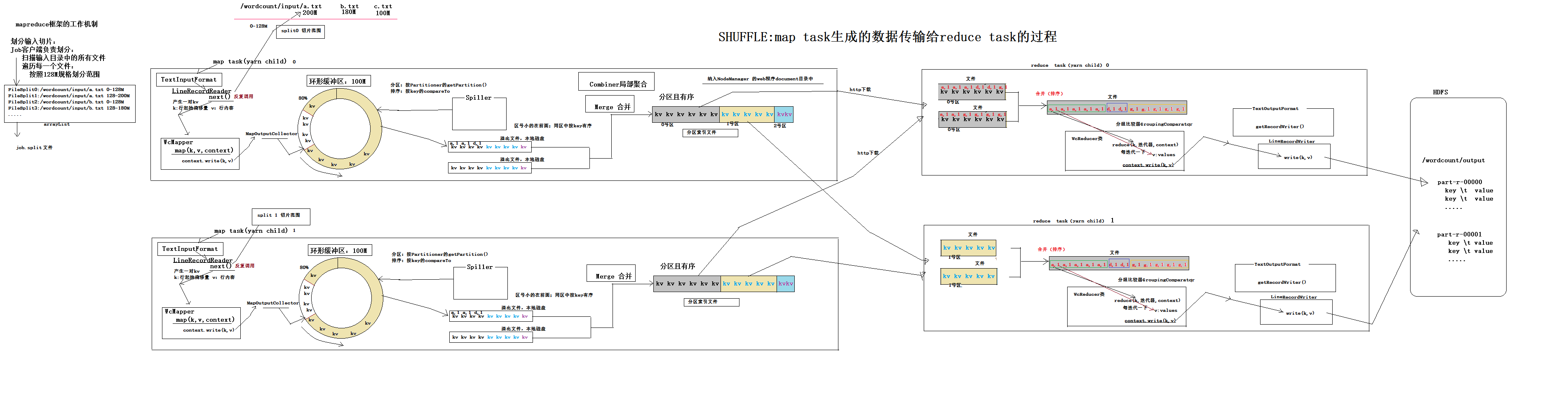
reducetask的并行度
1.reducetask并行度就是将原来的一个大任务,分成多个小任务,每一个任务负责一部分计算数据。
2.reduce任务有几个,最直观的的显示就是结果文件的个数。一个结果文件对应于一个reducetask的执行结果。底层分reducetask任务的时候,是按照分区规则分的,每一个reducetask最终对应一个分区的数据。reducetsak的个数和用户设定的有关。
3.默认的分区partition算法:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
//K key map输出的lkey, V value map输出的value int numReduceTasks job.setNumReducetask(3)
public int getPartition(K key, V value,int numReduceTasks(3)) {
//key.hashCode() & Integer.MAX_VALUE 防止溢出
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
hash%reducetask的个数,假设分区三个,余数为0 1 2
分区3个 余数为0的分为一个区 相同的单词肯定会分到一个区中----启动reducetask1任务-------part-r-00000
余数为1的分为一个区-----启动reducetask2任务-----part-r-00001
余数为2的分为一个区-----启动reducetask3任务-----part-r-00002
自定义partition
import java.util.HashMap; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; /**
* 本类是提供给MapTask用的
* MapTask通过这个类的getPartition方法,来计算它所产生的每一对kv数据该分发给哪一个reduce task
* 例子应用场景是模拟按手机号前几位确定是哪里的手机号,模拟分为六个,job.setNumReducetask()建议设为6,
* 这样结果文件就分成六个,里面就是每个地区分别对应的手机号,不多不少
* @author ThinkPad
*
*/
public class ProvincePartitioner extends Partitioner<Text, FlowBean>{
static HashMap<String,Integer> codeMap = new HashMap<>();
static{ codeMap.put("135", 0);
codeMap.put("136", 1);
codeMap.put("137", 2);
codeMap.put("138", 3);
codeMap.put("139", 4); } @Override
public int getPartition(Text key, FlowBean value, int numPartitions) { Integer code = codeMap.get(key.toString().substring(0, 3));
return code==null?5:code;
} }
自定义partition步骤:
1)继承Partitioner
2)重写getPartition
3)Driver类中:
//添加自定义分区
job.setPartitionerClass(MyPartitioner.class);
// 这个参数如果不指定,默认reducetask 1
job.setNumReduceTasks(6);
5.自定义分区的时候:
最终启动几个reducetask任务?由job.setNumReducetask()设定
每个reducetask任务的数据分配是谁决定的?自定义的分区决定的。
自定义分区的个数是4个,reducetask可以是几个?1个或者大于等于4个。
注意:自定义分区的时候,分区编号从0开始,最好是连续的整数。如果不连续的话,job.setNumReducetask至少比最大的返回值+1,如果没有返回值的分区号 会返回空文件。
6.一个maptask或者reducetask只能在一个节点上运行,一个节点上可以运行多个maptask或者reducetask任务,这是yarn负责分配的
hadoop执行时加载参数
/**
* 通过代码设置参数
*/ Configuration conf = new Configuration();
conf.setInt("top.n", 3);
/**
* 通过eclipse的run configuration设置参数 或者 hadoop jar xx.jar xx.yy.JobSubmitter 3
*/
conf.setInt("top.n", Integer.parseInt(args[0]));

/**
* 通过属性配置文件获取参数
*/ Configuration conf = new Configuration();
Properties props = new Properties();
props.load(JobSubmitter.class.getClassLoader().getResourceAsStream("topn.properties"));
conf.setInt("top.n", Integer.parseInt(props.getProperty("top.n")));
topn.properties
top.n=5
/**
* 通过加载classpath下的*.xml文件解析参数
*/
Configuration conf = new Configuration();
conf.addResource("xx-oo.xml");
xx-oo.xml
<configuration>
<property>
<name>top.n</name>
<value>6</value>
</property>
</configuration>
/**
* 通过加载classpath下的*-site.xml文件解析参数
*/
Configuration conf = new Configuration();
对象的引用
public class KengTest {
public static void main(String[] args) throws FileNotFoundException, IOException {
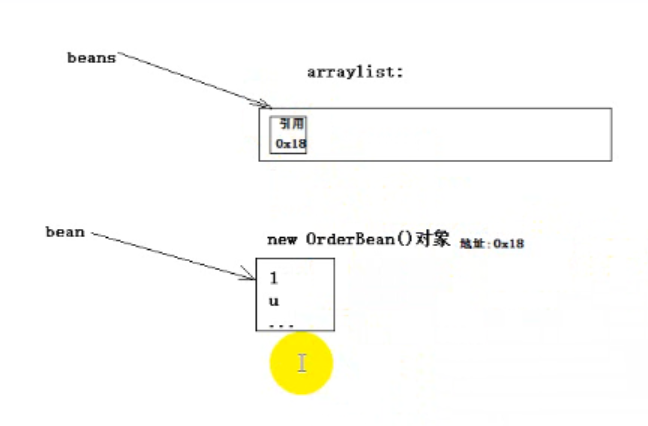
//ArrayList<OrderBean> beans = new ArrayList<>();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:/keng.dat", true));
OrderBean bean = new OrderBean();
bean.set("1", "u", "a", 1.0f, 2);
//beans.add(bean);
oos.writeObject(bean);
bean.set("2", "t", "b", 2.0f, 3);
//beans.add(bean);
oos.writeObject(bean);
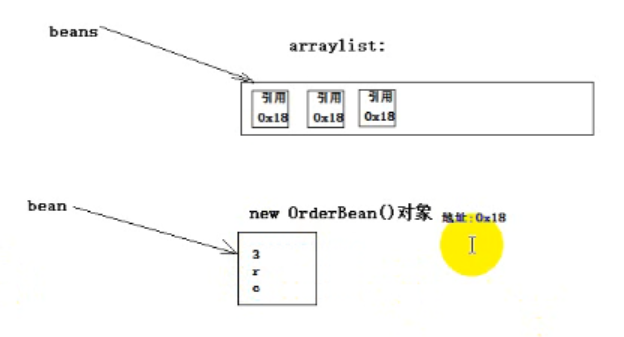
bean.set("3", "r", "c", 2.0f, 3);
//beans.add(bean);
oos.writeObject(bean);
//System.out.println(beans);
oos.close();
}
}
输出三个"3", "r", "c"
原因:引用,覆盖了前面的

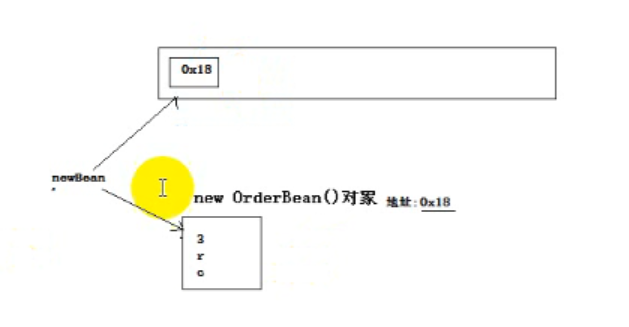
下面的代码不会出现上述问题
因为write方法有序列化过程,序列化后数据和这个对象就不关联了,数据被保存起来了
public static class OrderTopnMapper extends Mapper<LongWritable, Text, Text, OrderBean>{
OrderBean orderBean = new OrderBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, OrderBean>.Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
orderBean.set(fields[0], fields[1], fields[2], Float.parseFloat(fields[3]), Integer.parseInt(fields[4]));
k.set(fields[0]);
// 从这里交给maptask的kv对象,会被maptask序列化后存储,所以不用担心覆盖的问题
context.write(k, orderBean);
}
}
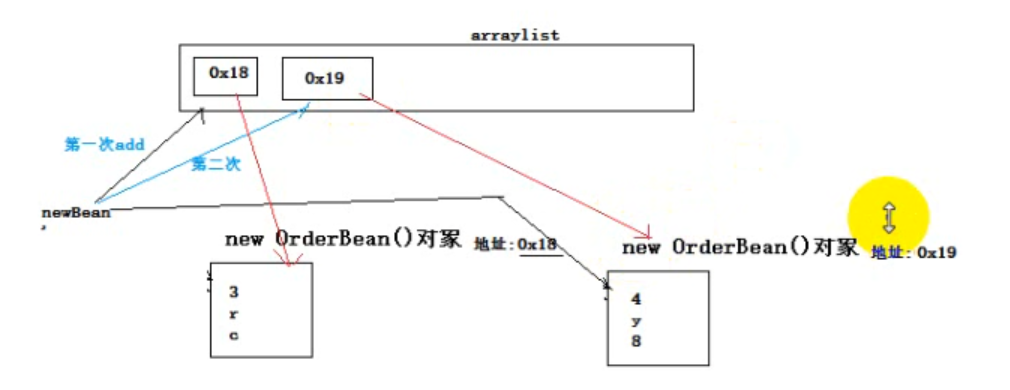
reduce task提供的values迭代器,每次迭代返回给我们的都是同一个对象,只是set了不同的值
在使用迭代器时,构造一个新的对象,来存储本次迭代出来的值
public static class OrderTopnReducer extends Reducer<Text, OrderBean, OrderBean, NullWritable>{
@Override
protected void reduce(Text key, Iterable<OrderBean> values,
Reducer<Text, OrderBean, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
// 获取topn的参数
int topn = context.getConfiguration().getInt("order.top.n",3);
ArrayList<OrderBean> beanList = new ArrayList<>();
// reduce task提供的values迭代器,每次迭代返回给我们的都是同一个对象,只是set了不同的值
for (OrderBean orderBean : values) {
// 构造一个新的对象,来存储本次迭代出来的值
OrderBean newBean = new OrderBean();
newBean.set(orderBean.getOrderId(), orderBean.getUserId(), orderBean.getPdtName(),
orderBean.getPrice(), orderBean.getNumber());
beanList.add(newBean);
}
// 对beanList中的orderBean对象排序(按总金额大小倒序排序,如果总金额相同,则比商品名称)
Collections.sort(beanList);
for (int i=0;i<topn;i++) {
context.write(beanList.get(i), NullWritable.get());
}
}
}
每次的对象都是新的,和之前不一样
mapreduce编程模型--及hadoop中的具体实现框架
源码 Mapper.class
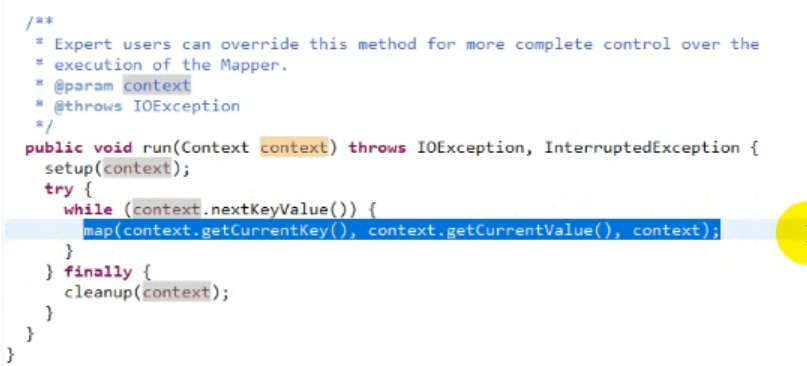
Mapper调用run()
启动时只执行一遍setup
后面循环遍历key value 执行map()
最后执行cleanup()
hadoop学习day3 mapreduce笔记的更多相关文章
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- 【尚学堂·Hadoop学习】MapReduce案例1--天气
案例描述 找出每个月气温最高的2天 数据集 -- :: 34c -- :: 38c -- :: 36c -- :: 32c -- :: 37c -- :: 23c -- :: 41c -- :: 27 ...
- Hadoop学习(3)-mapreduce快速入门加yarn的安装
mapreduce是一个运算框架,让多台机器进行并行进行运算, 他把所有的计算都分为两个阶段,一个是map阶段,一个是reduce阶段 map阶段:读取hdfs中的文件,分给多个机器上的maptask ...
- Hadoop学习(4)-mapreduce的一些注意事项
关于mapreduce的一些注意细节 如果把mapreduce程序打包放到了liux下去运行, 命令java –cp xxx.jar 主类名 如果报错了,说明是缺少相关的依赖jar包 用命令had ...
- hadoop学习day2开发笔记
1.将hdfs客户端开发所需的jar导入工程(jar包可在hadoop安装包中找到common/hdfs) 2.写代码 要对hdfs中的文件进行操作,代码中首先需要获得一个hdfs的客户端对象 Con ...
- Hadoop 学习之MapReduce
MapReduce充分利用了分而治之,主要就是将一个数据量比较大的作业拆分为多个小作业的框架,而用户需要做的就是决定拆成多少份,以及定义作业本身,用户所要做的操作少了又少,真是Very Good! 一 ...
- Hadoop学习笔记—4.初识MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
随机推荐
- appium+pytest+allure+jenkins 如何实现多台手机连接
使用appium可以实现app自动化测试,我们之前是连接一台手机去运行,如何同时连接多台手机呢?很多人可能想到的是多线程(threading).今天分享一种比多线程更简单的方法,虽然不是多台手机同时运 ...
- Android orm 框架xUtils简介
数据库操作建议用ORM框架,简单高效.这里推荐xUtils,里面包含DBUtils.github地址:https://github.com/wyouflf/xUtils 获得数据库实例建议用单例模式. ...
- JS获取当前时间到30天之后的日期区间
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- css单位长度
CSS长度单位 单位 含义 em 相对于父元素的字体大小 ex 相对于小写字母”x”的高度 gd 一般用在东亚字体排版上,这个与英文并无关系 rem 相对于根元素字体大小 vw 相对于视窗的宽度:视窗 ...
- Web 端屏幕适配方案
基础知识 像素相关 1.像素 :像素是屏幕显示最小的单位. 2.设备像素 :设备像素又称物理像素(physical pixel),设备能控制显示的最小单位,我们可以把这些像素看作成显示器上一个个的点. ...
- 利用DotNetZip服务端压缩文件并下载
public void DownFile() { string filePath = Server.MapPath("/Files/txt/bb.txt" ...
- Kafka术语解释
前一篇文章介绍了如何使用kafka收发消息,但是对于kafka的核心概念并没有详细介绍,这里将会对包括kafka基本架构以及消费者.生产者API涉及的术语进行说明.了解这些术语有助于更深入理解kafk ...
- java并发编程之volatile
Java语言规范第三版中对volatile的定义如下:Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排他锁单独获得这个变量. 了解volatile关键字之 ...
- hydra nodejs 微服务框架简单试用
hydra 是一个以来redis 的nodejs 微服务框架 安装 需要redis,使用docker 进行运行 redis docker run -d -p 6379:6379 redis 安装yo ...
- 【转】vim环境设置和自动对齐
原文网址:http://blog.chinaunix.net/uid-23525659-id-4340245.html 注:如果是用vim编写代码,建议开启vim的文件类型自动检测功能,这样编写代码换 ...