JournalNode的作用
NameNode之间共享数据(NFS 、Quorum Journal Node(用得多))
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
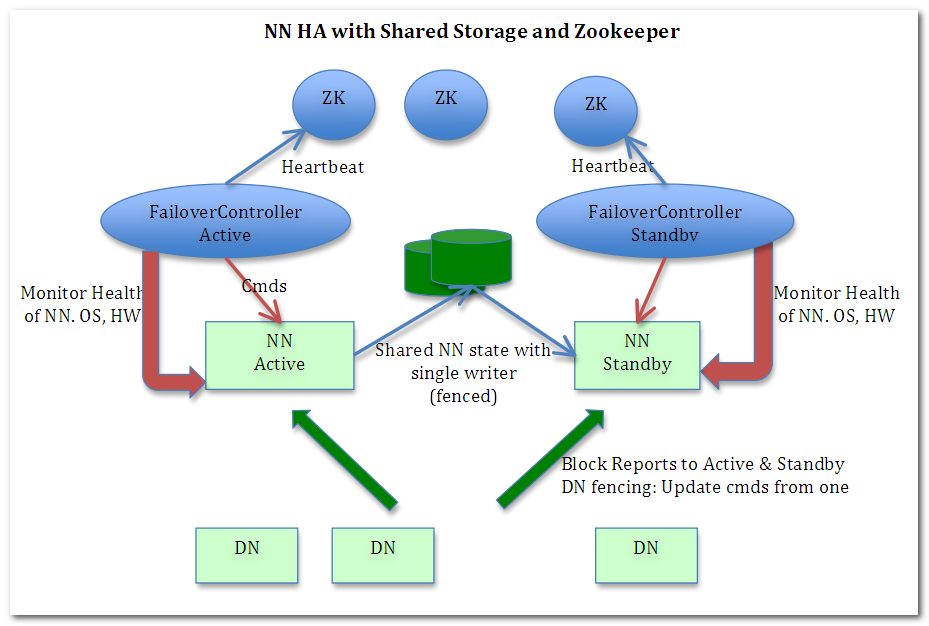
上面在Active Namenode与StandBy Namenode之间的绿色区域就是JournalNode,当然数量不一定只有1个,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.
NameNode之间共享数据(NFS 、Quorum Journal Node(用得多))
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作
hadoop2.2.0(HA)中HDFS的高可靠指的是可以同时启动2个NameNode。其中一个处于工作状态,另一个处于随时待命状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。
这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Nnetwork File System或者Quorum Journal Node。前者是通过linux共享的文件系统,属于操作系统的配置;后者是hadoop自身的东西,属于软件的配置。
我们这里讲述使用Quorum Journal Node的配置方式,方式是手工切换。
集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态。active状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务,如图2所示。
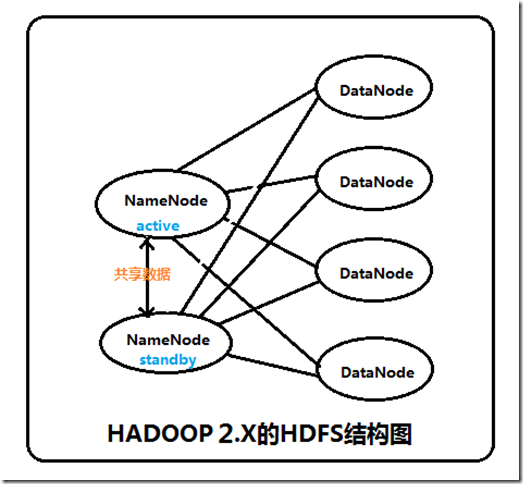
图2
架构
在一个典型的HA集群中,每个NameNode是一台独立的服务器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了,如图3所示。
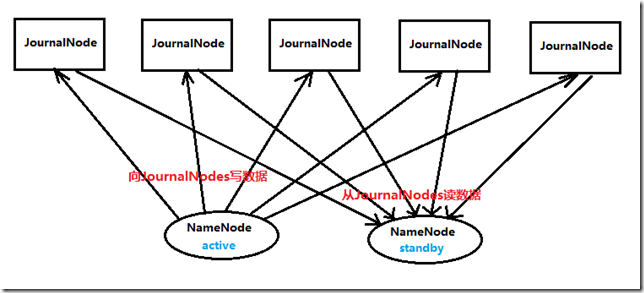
图3
为了确保快速切换,standby状态的NameNode有必要知道集群中所有数据块的位置。为了做到这点,所有的datanodes必须配置两个NameNode的地址,发送数据块位置信息和心跳给他们两个。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,JNs必须确保同一时刻只有一个NameNode可以向自己写数据。
JournalNode的作用的更多相关文章
- hadoop中的JournalNode
1.在HADOOP扮演的角色 JournalNode是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的, 在MR1中editlog是和fsimage存放在一起的然后S ...
- Hadoop High Availability
Hadoop High Availability HA(High Available), 高可用,是保证业务连续性的有效解决方案, 通常通过设置备用节点的方式实现; 一般分为执行业务的称为活动节点(A ...
- 关于hdfs的一些认知
先从网上copy一些优势点 1.高容错性数据自动保存多个副本.它通过增加副本的形式,提高容错性.某一个副本丢失以后,它可以自动恢复,这是由 HDFS 内部机制实现的,我们不必关心. 2.适合批处理它是 ...
- hdfs、zookeepeer之HA模式
HA简介 1.所谓HA,即高可用(high available) 2.消除单点故障,避免集群瘫痪,hdfs中namenode保存了整个集群的元数据,如果namenode所在机器宕机,则整个集群瘫痪,H ...
- Hadoop常见重要命令行操作及命令作用
关于Hadoop [root@master ~]# hadoop --help Usage: hadoop [--config confdir] COMMANDwhere COMMAND is one ...
- if __name__== "__main__" 的意思(作用)python代码复用
if __name__== "__main__" 的意思(作用)python代码复用 转自:大步's Blog http://www.dabu.info/if-__-name__ ...
- (转载)linux下各个文件夹的作用
linux下的文件结构,看看每个文件夹都是干吗用的/bin 二进制可执行命令 /dev 设备特殊文件 /etc 系统管理和配置文件 /etc/rc.d 启动的配置文件和脚本 /home 用户主目录的基 ...
- github中的watch、star、fork的作用
[转自:http://www.jianshu.com/p/6c366b53ea41] 在每个 github 项目的右上角,都有三个按钮,分别是 watch.star.fork,但是有些刚开始使用 gi ...
- web.xml中welcome-file-list的作用
今天尝试使用struts2+ urlrewrite+sitemesh部署项目,结果发现welcome-file-list中定义的欢迎页不起作用: <welcome-file-list> & ...
随机推荐
- phpstrom设置php环境
phpstorm设置自动同步服务器 Tools->Deployment->Confinguration 点+号,添加服务器,类型SFTP,输入name 点击ok,项目与服务器连接成功! 设 ...
- VS 2012 在 windows 8 中无法使用 Deubgger.Lunch() 对服务进行调试
找到了外文资料: Debugger.Launch() not displaying JIT debugger selection popup on Windows 8/8.1 If execu ...
- Genymotion安卓模拟器和VirtualBox虚拟机安装、配置、测试(win7_64bit)
1.概述 VirtualBox是一个优秀的虚拟机软件,它可以在电脑上提供另一个操作系统的运行环境,使多个系统同时运行.VirtualBox支持的操作系统包括Windows.Mac OS X.Linux ...
- host 'xx' is not allowed to connect to this MySql server
update mysql.user set host = '%' where user = 'root'; FLUSH PRIVILEGES; select * from mysql.user;
- java构造方法-this关键字的用法
public class constructor { public static void main(String[] args) { // TODO Auto-generated method st ...
- 分享个Cognos8.4安装介质的百度云网盘链接
https://pan.baidu.com/share/link?shareid=3750687613&uk=3441846946#list/path=%2F
- GPU性能:光栅化、图层混合、离屏渲染
So, shouldRasterize will not affect the green/red you see using Instruments. In order to have everyt ...
- ubuntu ibus 输入法总在左下角不跟随光标的处理
sudo apt-get install ibus-gtk ibus-gtk3 ibus-qt4 参考文章
- F、CSL 的神奇序列 【规律】 (“新智认知”杯上海高校程序设计竞赛暨第十七届上海大学程序设计春季联赛)
题目传送门:https://ac.nowcoder.com/acm/contest/551/F 题目描述 CSL 有一个神奇的无穷实数序列,他的每一项满足如下关系: 对于任意的正整数 n ,有 n∑k ...
- [USACO06NOV]玉米田$Corn \ \ Fields$ (状压$DP$)
#\(\mathcal{\color{red}{Description}}\) \(Link\) 农场主\(John\)新买了一块长方形的新牧场,这块牧场被划分成\(M\)行\(N\)列\((1 ≤ ...