ng-深度学习-课程笔记-17: 序列模型和注意力机制(Week3)
1 基础模型(Basic models)
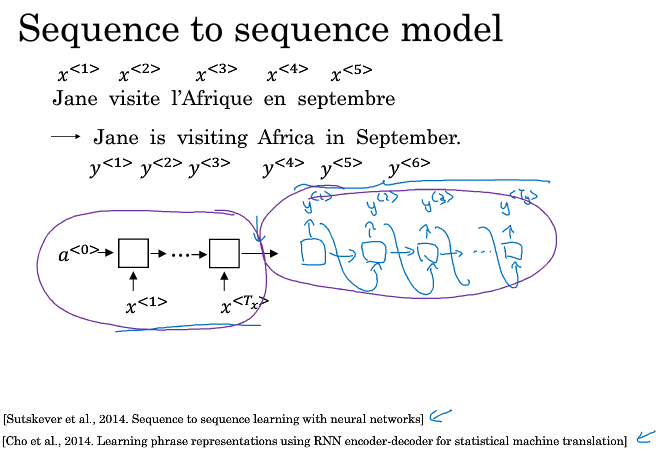
一个机器翻译的例子,比如把法语翻译成英语,如何构建一个神经网络来解决这个问题呢?
首先用RNN构建一个encoder,对法语进行编码,得到一系列特征
然后用RNN构建一个decoder,将编码后的特征信息,解码成英语,以此来生成对应的英语翻译
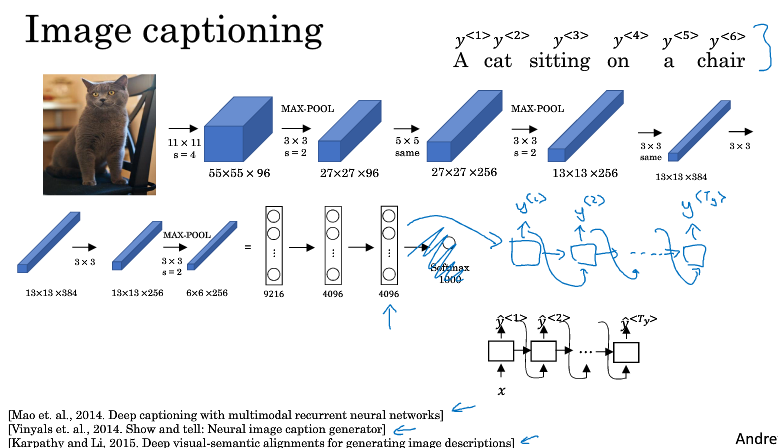
一个图像生成字幕的例子
首先用CNN构建一个encoder,对图像进行编码,得到一系列特征
然后用RNN构建一个decoder,将编码后的特征信息,解码成文本,以此来生成对图像的字幕描述
2 选择最可能的句子(Picking the most likely sentence)
机器翻译的例子可以看作一个条件语言模型,它和语言模型的区别在于,语言模型是随机地生成一个句子,而条件语言模型是希望在所有可能生成的句子中挑一个最好的,最可能的翻译。
可以看到,机器翻译例子中的decoder部分每个时间步输出的是softmax多个词的概率,那么如何选择呢?
如果是每次都选择最大的概率,然后把这个y作为到下一个时间步的x进行预测,这样的算法就叫贪心搜索
贪心算法先挑出最好的第一个词,再基于这种情况挑出最好的第二个词,以此类推,这种方法并不管用
因为我们需要的是一次性挑出所有时间步的y,使得整体的概率最大
比如,如下图所示,根据贪心算法Jane is 后面给出的预测更可能是going,但是显然第一个翻译才是更好更简洁的选择
在所有可能生成的句子有太多种单词组合,我们希望有一个近似的搜索算法,在当前给定的x,能够挑出序列y,使得条件概率最大
下节课将介绍一种束搜索的算法来解决这个问题

3 束搜索(Beam Search)
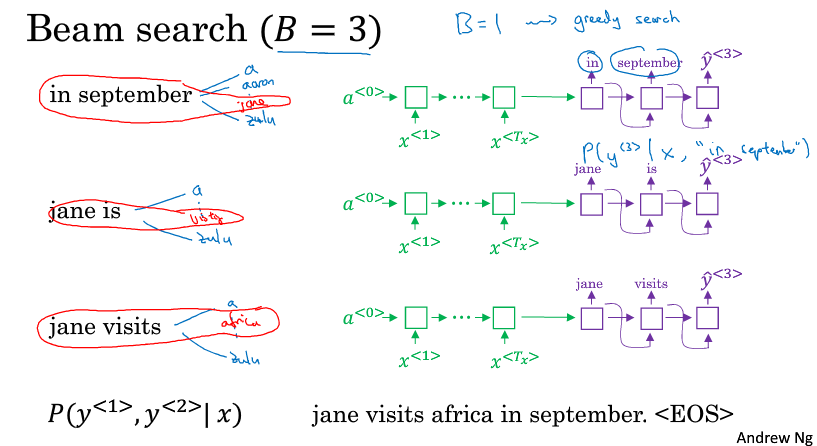
束搜索不像贪心算法那样每次只考虑最好的一个,它有个参数B称为Beam width,这里我们假设B=3,每次考虑最好的三个,B=1的时候束搜索就变成了贪心搜索。束搜索通常会得到比贪心搜索更好的结果。
第一步:确定第一个词是什么,直接根据x计算得到10000个概率,挑出概率最高的三个y1
第二步:确定第二个词是什么,三个y1分别作为输入x2去计算概率,这样可以得到3*10000个概率,从这些概率里面得到概率最高的三个y2,注意这里的概率要乘以上一步的条件概率,P(y1,y2 | x)= P(y1 | x)* P(y2 | x,y1)
因为B=3,所以我们每一步之后都复制三个网络来进行计算,每个网络的条件概率不同,比如这一步执行后每个网络的P(y1,y2 | x)都不同,在第一步执行后每个网络的P(y1 | x)都不同
第三步:确定第三个词是什么,用先验概率P(y1,y2 | x)乘上10000个输出概率得到第三个词的概率。最后会得到3*10000个概率,选择最高的3个,以此类推

4 改进束搜索(Refinements to beam search)
前面做的束搜索,其实就是在优化下面这个式子
式子是很多很多个条件概率相乘,因为每一项都是小于1的数,很多项乘起来,会得到一个很小很小的数,容易造成数值下溢
所以实践中会对每一项取log,把概率的乘积转为概率的对数和,可以得到更稳定的数值结果
然后,这样优化可能会导致模型尽量预测短句子,因为这样可以使得概率积或概率对数和尽可能大,可以除以一个总序列的长度来弥补这个问题
实际上可以有更柔和的做法,就是在总长度加一个指数α,比如0.7,如果等于1就是完全使用长度来归一化,如果等于0就是没有归一化,0.7就在完全归一化和没有归一化之间做一个折中,这个值是一个试探性的,没有理论证明,但是大家都发现效果很好,所以很多人都这么做,你可以尝试不同的值,看看哪个能得到最好的结果

还有一个细节就是,如何选择Bean width B
B越大,考虑的选择越多,可能找到的句子越好,但是算法的计算代价也越大,内存占用也越大
前面的例子中使用的B等于3,实际上这个值优点偏小,实际产品中通常把B设到10,100的话有点太大了
但是实际科研中,人们想压榨出最好的结果,通过会使用1000或者3000,这取决于特定领域和特定应用
Beam搜索和广度优先,深度优先搜索的一个区别是,它不能保证找到最优解,它只是一个近似搜索的算法
5 束搜索的误差分析(Error analysis on beam search)
当你的模型出错的时候,如何分析出,是RNN模型出问题了,还是这个BeamSearch算法出问题了呢?
B增大的时候,并不总是能提高模型的表现,就像数据增强并不总是能改善模型一样,你怎么知道如何去增大B来改善模型呢?
假设y*是真实期望的结果,而$ \hat{y} $ 是预测的结果
如果真实期望的结果的概率大于预测结果的概率,说明Beam搜索出了问题,它预测出来的结果并不是最大的概率
如果真实期望的结果的概率小于预测结果的概率,说明应该在RNN上面花时间,因为y*明明是一个更好的结果,RNN却赋予它更小的概率
如果使用了长度归一化的优化公式,要使用长度归一化之后的结果,而不是单纯的概率P
可以对验证集中的每条数据做这样的分析,统计出错的比例,来决定对RNN进行改善,还是对束搜索进行改善
当确定是束搜索出问题之后,再花精力去提高B的值来提升表现
当确定是RNN的问题后,再进一步决定是要增加数据,还是增加正则项,还是尝试不同的网络结构,或者其它方案

6 注意力模型的直观理解(attention model intuition)
对于一个长序列,人工翻译并不会通过读整个句子,再记忆里面的东西,然后从零开始机械式地翻译一个英语句子
人工翻译首先会做的可能是先读一部分,翻译出一部分,再看下一部分,再翻译出下一部分,一点一点地翻译,因为要记住这么长一段话是非常困难的
在之前的encoder-decoder结构中的机器翻译里,对短句子的表现效果是挺好的,但是对于长句子表现则会比较差,大致是一个先上升后下降的趋势,因为在神经网络中要记忆非常长的句子是很困难的。
要解决这个问题就需要使用注意力机制,它使得模型在翻译长句子的时候也能保持良好的表现
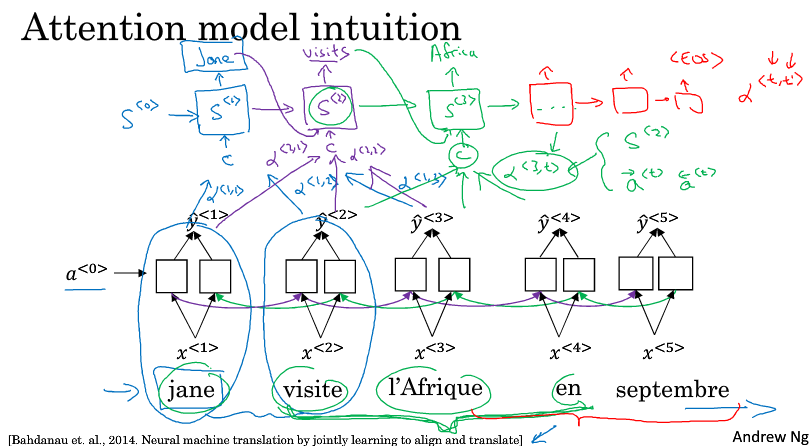
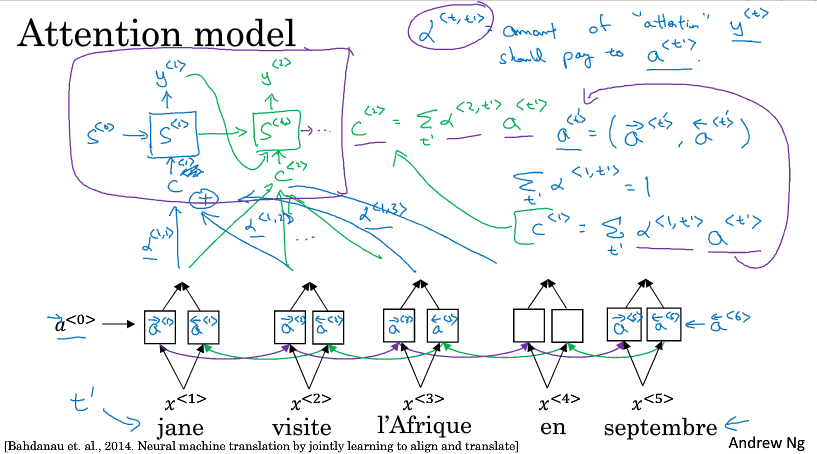
为了简单讲解,下面以一个短句为例,比如翻译如下的法语,当我们翻译出一个Jane的时候我们希望看原句的第一个单词或者第一个单词附近的词,而不会去看末尾的词,所以注意力模型会计算一个权重
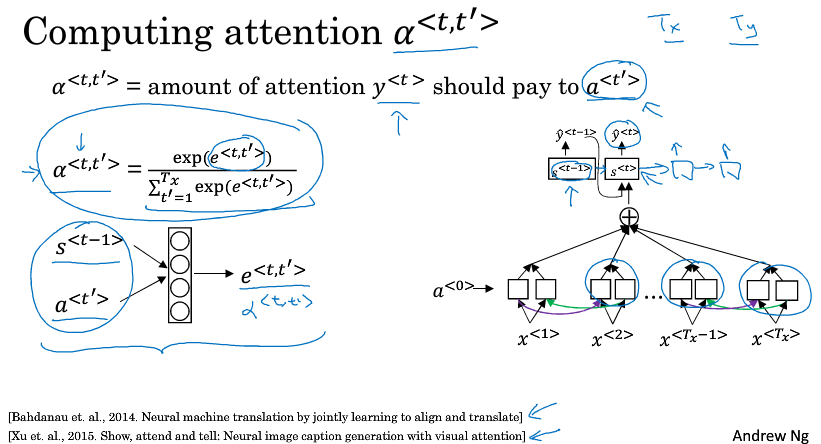
$ \alpha ^{<1,1>} $ 表示翻译出第一个词时,用第一个词的权重是多少
$ \alpha ^{<1,2>} $ 表示翻译出第一个词时,应该花多少注意力在第二个词上
以此类推,不同权重计算后的特征加起来作为上下文C,输入到生成翻译的RNN里
7 注意力模型(attention model)
ng-深度学习-课程笔记-17: 序列模型和注意力机制(Week3)的更多相关文章
- 吴恩达《深度学习》-第五门课 序列模型(Sequence Models)-第三周 序列模型和注意力机制(Sequence models & Attention mechanism)-课程笔记
第三周 序列模型和注意力机制(Sequence models & Attention mechanism) 3.1 序列结构的各种序列(Various sequence to sequence ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(六)Error
深度学习课程笔记(六)Error Variance and Bias: 本文主要是讲解方差和偏差: error 主要来自于这两个方面.有可能是: 高方差,低偏差: 高偏差,低方差: 高方差,高偏差: ...
- 深度学习课程笔记(五)Ensemble
深度学习课程笔记(五)Ensemble 2017.10.06 材料来自: 首先提到的是 Bagging 的方法: 我们可以利用这里的 Bagging 的方法,结合多个强分类器,来提升总的结果.例如: ...
- 深度学习课程笔记(二)Classification: Probility Generative Model
深度学习课程笔记(二)Classification: Probility Generative Model 2017.10.05 相关材料来自:http://speech.ee.ntu.edu.tw ...
- 深度学习课程笔记(一)CNN 卷积神经网络
深度学习课程笔记(一)CNN 解析篇 相关资料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html 首先提到 Why CNN for I ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
随机推荐
- Nginx(一)-- 初体验
1.概念 Nginx ("engine x") 是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 服务器. Nginx提供基本http服务,可以作 ...
- Redis(六)-- SpringMVC整合Redis
一.pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www ...
- 说说GPIO.H(NUC131)
/**************************************************************************//** * @file GPIO.h * @ve ...
- js array.filter实例(数组去重)
语法: 循环对数组中的元素调用callback函数, 如果返回true 保留,如果返回false 过滤掉, 返回新数组,老数组不变 var new_array = source_array.filt ...
- Swift 高级运算符
本文转载至 http://my.oschina.net/sunqichao/blog?disp=2&catalog=0&sort=time&p=2 除了基本操作符中所讲的运算符 ...
- Python-Numpy的tile函数用法
1.函数的定义与说明 函数格式tile(A,reps) A和reps都是array_like A的类型众多,几乎所有类型都可以:array, list, tuple, dict, matrix以及基本 ...
- MQTT协议笔记之订阅
前言 记忆不太好的时候,只能翻看以前的文章/笔记重新温习一遍,但找不到MQTT协议有关订阅部分的描述,好不容易从Evernote中找到贴出来,这样整个MQTT协议笔记,就比较齐全了. SUBSCRIB ...
- linux 学习的一些书单,对了解android 也有大用
要推荐的书,我在<那两年炼就的Android内功修养>这篇文章中有提到,这里再列一下出来: 语言类: <深度探索C++对象模型>,对应的英文版是<Inside C+++ ...
- font-size对展示的影响
实例: <head> <style type="text/css"> span{display: inline-bloc ...
- awk中的冒泡排序
算法中经典的排序方式,今也用awk来实现下,代码如下: BEGIN { count=} {arrary[count]=$ count++ } END{ ;i>-;i--) { ;j<i;j ...