Naive Bayes Algorithm And Laplace Smoothing
朴素贝叶斯算法(Naive Bayes)适用于在Training Set中,输入X和输出Y都是离散型的情况。如果输入X为连续,输出Y为离散,我们考虑使用逻辑回归(Logistic Regression)或者GDA(Gaussian Discriminant Algorithm)。
试想,当我们拿到一个全新的输入X,求解输出Y的分类问题时,相当于,我们要求解概率p(Y|X)这里的X和Y都是向量,我们要根据p(Y|X)的结果,找出可能性最大的那个y值,进行输出。举个经典的垃圾邮件(Spam)分类例子:如果在邮件中出现了"buy","discount","now",但没有出现"sale","price",试问这份邮件是垃圾邮件吗?首先我们将这5个单词分别对应到X中(顺序分别为"buy","discount","now","sale","price"):
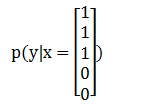
然后,我们要计算出p(y=1|x)和p(y=0|x),以决定邮件是否为垃圾邮件。在实际情况中,X的维度可能是数万,甚至更多,直接求解的可能性为0,所以需要用到Naive Bayes。我们知道贝叶斯定理:

运用到此例子上,可以写为:
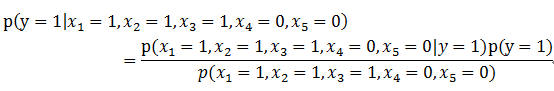
而Naive Bayes的Naive就在于,在给定y的情况下,我们认为X各个维度之间相互独立,即:
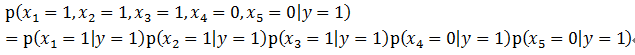 所以有:
所以有:
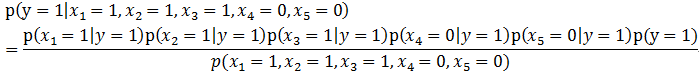
由全概率公式:

也就是说,我们预先通过建模,知道在一般情况下垃圾邮件的概率,以及垃圾邮件和非垃圾邮件中中,包含某一个词的概率,然后即可利用此公式进行计算。拓展到一般的情况:

拉普拉斯平滑,当在我们碰到没见过的xi,会导致上式的分子和分母都为0,则p(y=1|x)及p(y=0|x)的值无法得出,为了解决此问题,引入拉普拉斯平滑。下面先举例来说明:假设邮件分类中,有2个类,在指定的训练样本中,某个词语K1,观测计数分别为990,10,K1的概率为0.99,0.01,对这两个量使用拉普拉斯平滑的计算方法如下:991/1002=0.988,11/1002=0.012
通用版公式如下:
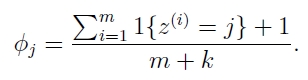
我最初的疑问是,为什么分母要加k(类别数)?因为你在k个分类概率的分子处都加了1,总共加了k个,为了保证全概率为1,所以分母也要加k。总体的思路是,异常值不要影响我们整体的概率。
Naive Bayes Algorithm And Laplace Smoothing的更多相关文章
- 6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python)
6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python) Introduction Here’s a situation yo ...
- 机器学习---用python实现朴素贝叶斯算法(Machine Learning Naive Bayes Algorithm Application)
在<机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)>一文中,我们介绍了朴素贝叶斯分类器的原理.现在,让我们来实践一下. 在 ...
- Naive Bayes Algorithm
朴素贝叶斯的核心基础理论就是贝叶斯理论和条件独立性假设,在文本数据分析中应用比较成功.朴素贝叶斯分类器实现起来非常简单,虽然其性能经常会被支持向量机等技术超越,但有时也能发挥出惊人的效果.所以,在将朴 ...
- 朴素贝叶斯法(naive Bayes algorithm)
对于给定的训练数据集,朴素贝叶斯法首先基于iid假设学习输入/输出的联合分布:然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y. 一.目标 设输入空间是n维向量的集合,输出空间为 ...
- [ML] Naive Bayes for Text Classification
TF-IDF Algorithm From http://www.ruanyifeng.com/blog/2013/03/tf-idf.html Chapter 1, 知道了"词频" ...
- [Machine Learning & Algorithm] 朴素贝叶斯算法(Naive Bayes)
生活中很多场合需要用到分类,比如新闻分类.病人分类等等. 本文介绍朴素贝叶斯分类器(Naive Bayes classifier),它是一种简单有效的常用分类算法. 一.病人分类的例子 让我从一个例子 ...
- 朴素贝叶斯方法(Naive Bayes Method)
朴素贝叶斯是一种很简单的分类方法,之所以称之为朴素,是因为它有着非常强的前提条件-其所有特征都是相互独立的,是一种典型的生成学习算法.所谓生成学习算法,是指由训练数据学习联合概率分布P(X,Y ...
- 机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)
朴素贝叶斯分类器是一组简单快速的分类算法.网上已经有很多文章介绍,比如这篇写得比较好:https://blog.csdn.net/sinat_36246371/article/details/6014 ...
- 朴素贝叶斯分类器(Naive Bayes)
1. 贝叶斯定理 如果有两个事件,事件A和事件B.已知事件A发生的概率为p(A),事件B发生的概率为P(B),事件A发生的前提下.事件B发生的概率为p(B|A),事件B发生的前提下.事件A发生的概率为 ...
随机推荐
- jupyter notebook使用时路径问题和kernel error,安装opencv
修改路径: 在C:\Users\Administrator\ .jupyter 目录下面只有一个“migrated”文件. 打开命令窗口(运行->cmd),进入python的Script目录下输 ...
- poj2019 二维RMQ裸题
Cornfields Time Limit: 1000MS Memory Limit: 30000K Total Submissions:8623 Accepted: 4100 Descrip ...
- usleep和sleep
usleep 和 sleep 都是用于将进程挂起, 所不同的是前者在微秒级别, 后者在秒级别.
- Asp.net中GridView使用详解(很全,很经典)
http://blog.csdn.net/hello_world_wusu/article/details/4052844 Asp.net中GridView使用详解 效果图参考:http://hi.b ...
- mssql 取数据指定条数(例:100-200条的数据)
方法1:临时表 * into #aa from table order by time-- 将top m笔插入 临时表 select * from #aa order by time desc --d ...
- Jsp 自定义tag标签
1转自:https://blog.csdn.net/yusimiao/article/details/46835617 Jsp自定义tag标签 自定义tag标签的好处 程序员可以自定一些特定功能的标记 ...
- GitHub 搭建博客,出现 hexo g -d 报错
想搭建一个个人博客,但是在将博客推送到Github上的时候在git bash 下运行hexo g -d命令出现错误: 错误如下: fatal: HttpRequestException encoun ...
- Spring Boot 全局排除 spring-boot-starter-logging 依赖
https://blog.csdn.net/u013314786/article/details/90412733 项目里使用了log4j2做日志处理,要排除掉Spring Boot 很多jar里边默 ...
- IC设计:CMOS器件及其电路
作为一个微电子专业的IC learner,这个学期也有一门课:<微电子器件>,今天我就来聊聊基本的器件:CMOS器件及其电路.在后面会聊聊锁存器和触发器. ·MOS晶体管结构与工作原理简述 ...
- How to Add Memory, vCPU, Hard Disk to Linux KVM Virtual Machine
ref: https://www.thegeekstuff.com/2015/02/add-memory-cpu-disk-to-kvm-vm/ In our previous article of ...