Naive Bayes Algorithm And Laplace Smoothing
朴素贝叶斯算法(Naive Bayes)适用于在Training Set中,输入X和输出Y都是离散型的情况。如果输入X为连续,输出Y为离散,我们考虑使用逻辑回归(Logistic Regression)或者GDA(Gaussian Discriminant Algorithm)。
试想,当我们拿到一个全新的输入X,求解输出Y的分类问题时,相当于,我们要求解概率p(Y|X)这里的X和Y都是向量,我们要根据p(Y|X)的结果,找出可能性最大的那个y值,进行输出。举个经典的垃圾邮件(Spam)分类例子:如果在邮件中出现了"buy","discount","now",但没有出现"sale","price",试问这份邮件是垃圾邮件吗?首先我们将这5个单词分别对应到X中(顺序分别为"buy","discount","now","sale","price"):
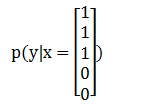
然后,我们要计算出p(y=1|x)和p(y=0|x),以决定邮件是否为垃圾邮件。在实际情况中,X的维度可能是数万,甚至更多,直接求解的可能性为0,所以需要用到Naive Bayes。我们知道贝叶斯定理:

运用到此例子上,可以写为:
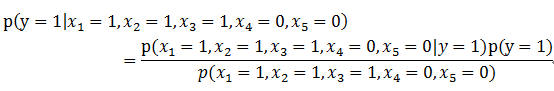
而Naive Bayes的Naive就在于,在给定y的情况下,我们认为X各个维度之间相互独立,即:
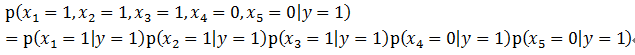 所以有:
所以有:
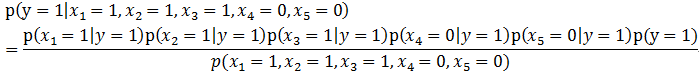
由全概率公式:

也就是说,我们预先通过建模,知道在一般情况下垃圾邮件的概率,以及垃圾邮件和非垃圾邮件中中,包含某一个词的概率,然后即可利用此公式进行计算。拓展到一般的情况:

拉普拉斯平滑,当在我们碰到没见过的xi,会导致上式的分子和分母都为0,则p(y=1|x)及p(y=0|x)的值无法得出,为了解决此问题,引入拉普拉斯平滑。下面先举例来说明:假设邮件分类中,有2个类,在指定的训练样本中,某个词语K1,观测计数分别为990,10,K1的概率为0.99,0.01,对这两个量使用拉普拉斯平滑的计算方法如下:991/1002=0.988,11/1002=0.012
通用版公式如下:
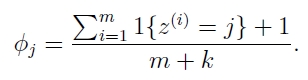
我最初的疑问是,为什么分母要加k(类别数)?因为你在k个分类概率的分子处都加了1,总共加了k个,为了保证全概率为1,所以分母也要加k。总体的思路是,异常值不要影响我们整体的概率。
Naive Bayes Algorithm And Laplace Smoothing的更多相关文章
- 6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python)
6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python) Introduction Here’s a situation yo ...
- 机器学习---用python实现朴素贝叶斯算法(Machine Learning Naive Bayes Algorithm Application)
在<机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)>一文中,我们介绍了朴素贝叶斯分类器的原理.现在,让我们来实践一下. 在 ...
- Naive Bayes Algorithm
朴素贝叶斯的核心基础理论就是贝叶斯理论和条件独立性假设,在文本数据分析中应用比较成功.朴素贝叶斯分类器实现起来非常简单,虽然其性能经常会被支持向量机等技术超越,但有时也能发挥出惊人的效果.所以,在将朴 ...
- 朴素贝叶斯法(naive Bayes algorithm)
对于给定的训练数据集,朴素贝叶斯法首先基于iid假设学习输入/输出的联合分布:然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y. 一.目标 设输入空间是n维向量的集合,输出空间为 ...
- [ML] Naive Bayes for Text Classification
TF-IDF Algorithm From http://www.ruanyifeng.com/blog/2013/03/tf-idf.html Chapter 1, 知道了"词频" ...
- [Machine Learning & Algorithm] 朴素贝叶斯算法(Naive Bayes)
生活中很多场合需要用到分类,比如新闻分类.病人分类等等. 本文介绍朴素贝叶斯分类器(Naive Bayes classifier),它是一种简单有效的常用分类算法. 一.病人分类的例子 让我从一个例子 ...
- 朴素贝叶斯方法(Naive Bayes Method)
朴素贝叶斯是一种很简单的分类方法,之所以称之为朴素,是因为它有着非常强的前提条件-其所有特征都是相互独立的,是一种典型的生成学习算法.所谓生成学习算法,是指由训练数据学习联合概率分布P(X,Y ...
- 机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)
朴素贝叶斯分类器是一组简单快速的分类算法.网上已经有很多文章介绍,比如这篇写得比较好:https://blog.csdn.net/sinat_36246371/article/details/6014 ...
- 朴素贝叶斯分类器(Naive Bayes)
1. 贝叶斯定理 如果有两个事件,事件A和事件B.已知事件A发生的概率为p(A),事件B发生的概率为P(B),事件A发生的前提下.事件B发生的概率为p(B|A),事件B发生的前提下.事件A发生的概率为 ...
随机推荐
- 使用 js 修饰器封装 axios
修饰器 修饰器是一个 JavaScript 函数(建议是纯函数),它用于修改类属性/方法或类本身.修饰器提案正处于第二阶段,我们可以使用 babel-plugin-transform-decorato ...
- Flask 中请求钩子的理解和应用?
请求钩子是通过装饰器的形式实现的,支持以下四种:1,before_first_request 在处理第一个请求前运行2,before_request:在每次请求前运行3,after_request:如 ...
- redis关闭和启动
redis关闭 到redis节点目录下执行如下命令 redis-cli -p 端口号 shutdown redis启动 ./redis-server 参数 参数:redis.conf文件全路径 需要到 ...
- P1973 [NOI2011]Noi嘉年华
传送门 首先可以把时间区间离散化 然后求出 $cnt[l][r]$ 表示完全在时间 $[l,r]$ 之内的活动数量 设 $f[i][j]$ 表示当前考虑到时间 $i$,第一个会场活动数量为 $j$ 时 ...
- spark复习笔记(7):sparkstreaming
一.介绍 1.sparkStreaming是核心模块Spark API的扩展,具有可伸缩,高吞吐量以及容错的实时数据流处理等.数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字 ...
- liunx-centos-基础命令详解(1) -主要内容来自 —https://www.cnblogs.com/caozy/p/9261224.html
关机:halt/poweroff :立刻关机reboot :立刻重启 shutdown -r now :立刻重启shutdown -h 00:00 :定时重启 now:立刻shutdown -h +n ...
- mysql查询每个部门/班级前几名
Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id . +----+-------+--------+--------------+ | I ...
- 记录一次 Linux crontab 执行django 脚本 失败 的经历和解决办法
目的是想通过定时任务来执行一次数据统计,本来可以用celery来做,但是想着这个项目整个就没用到异步的地方,所以决定用crontab来做.之前做过数据库的热备份,想来用该没啥问题,但是现实打脸啪啪响. ...
- ltp-ddt eth_parallel_processing
ETH_S_FUNC_PARALLEL_PROCESSING: source 'common.sh'; prepare_nfs_mount.sh "/mnt/nfs_mount"| ...
- docker中pull镜像,报错 pull access denied for ubantu, repository does not exist or may require 'docker login'
报错说明:拒绝获取ubantu, 仓库不存在或者需要登录docker 1.先尝试注册docker 2.在拉镜像前,先登录docker, 命令:docker login 3.然后执行 docker ...