Hark的数据结构与算法练习之堆排序
前言
堆排序我是看了好半天别人的博客才有了理解,然后又费了九牛二虎之力才把代码写出来,我发现我的基础真的很差劲啊……不过自己选的路一定要坚持走下去。
我试着把我的理解描述出来,如有不妥之处希望大家可以指点出来
算法说明
堆排序,是基于堆的排序。 堆也就是二叉树的一种(完全二叉树),首先要确定堆的定义,才可以学会堆算法的逻辑;
OK,我们知道堆的定义前得先确定啥是完全二叉树。
二叉树就是树状结构是这样的,如图:
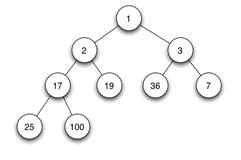
通常二叉树都会存放在数组中,那么将上图的完全二叉树放在数组中就是int[] arrayData = {1,2,3,17,19,36,7,25,100}
然后还有一个前置知识要知道,就是如何计算左子孩子的索引和右子孩子的索引。
还是以上图来举例子,3,36,7这三个数中, 3就是父节点,36 和 7就是子节点。 然后左子节点和右子节点的计算公式是i*2+1 和 i*2+2 。 替换到我举的例子中就是,数字3在数组中的索引是2,那么根据公式所述,左子节点的数组索引是2*2+1=5,右子节点的数组索引是2*2+2=6。 大家可以对一下数字36和数字7的数组索引和我们计算出来的是否一致。
还有,父节点的索引公式是 (i-1)/2。 大家可以代入一下上面的数组求一下值
OK,下面我们可以看一下堆的定义了。
堆的定义是这样的:

如图,堆分两种,一种是“小顶堆”,另一种是“大顶堆“。
小顶堆:就是顶点是最小值,并且父节点小于等于左子节点和右子节点(子节点公式上边有说)
大顶堆:就是顶点是最大值,并且父节点大于等于左子节点呼右子节点(子节点公式上边有说)
OK,现在说一下堆排序的逻辑。 堆排序是有两步:
第一步:建立堆。 我们需要把无序数组调整成堆结构(也就是让无序数组满足上图的条件)
大概过程,如图:
如图如所,我们要建立的是小顶堆,所以父节点一定是大小子节点的。
那么从97这个数字开始,是才有子节点的。 如果按公式来算,就是索引第(i/2)-1个数字是第一个有子节点的数字。
比较完数字97,把小的数字与97对换,然后再比较数字65与65子节点大小,然后再比较数字38与38子节点大小,最终比较最顶节点与子节点。
OK,有一个槽点要注意,请大家看第四图和第五图,当比较顶节点和子节点时,13与49换了位置,这时发现换位置后的49与49子节点是不满足堆的关联,所以49与27也要做一下互换的。 大家有个印象就行,具体逻辑还是请看下边的代码(17行至20行)
第二步:进行堆排序。
因为堆其实就是一个数组,所以如果我们的堆是完全从小到大,或者从大到小存储数据,那么数组同样也就是升序,或者降序了。
以下代码第24行至31行是进行堆排序。
我们可以看到我们之前代码建立好的堆是小顶堆,也就是最小值是在顶点。
第26行到28行,做的就是把第一个节点与最后一个节点数字互换,这时,最小值就在最后边了。
然后执行第30行的代码,因为上边把节点数字做了互换,这时堆就变成了无序数组,那么需要重新建立堆啦,需要把第一个节点至(最后一个节点-1)进行重建堆。
重建堆后,最小的数字又会放到第一他节点啦
接着执行第26行到28行,把第一个节点与(最后一个节点-1)数字互换,这时,最小值就在(最后一个节点-1)了。
然后执行第30行代码,继续重新建立堆。。。。如此类推,数字将会进行降序。
代码
使用JAVA
/*
* 堆排序
*/
public class HeadSort {
public static void main(String[] args) {
int[] arrayData = { 5, 9, 6, 7, 4, 1, 2, 3, 8 };
HeadSortMethod(arrayData);
for (int integer : arrayData) {
System.out.print(integer);
System.out.print(" ");
}
} public static void HeadSortMethod(int[] arrayData) {
// 第一步,将无序数组,建成一个堆。
//System.out.println("开始建堆");
for (int i = arrayData.length / 2 - 1; i >= 0; i--) {
// 第一个有孩子节点的节点,索引是arrayData.length/2-1 。 这个就不证明了(暂时还不会),大家测试一下就知道结果了
HeadAjust(arrayData, i, arrayData.length);
}
//System.out.println("开始排序");
// 第二步,进行排序
// 对堆进行递归,来建立排好序的堆。
int temp;
for (int i = arrayData.length-1; i > 0; i--) {
temp = arrayData[0];
arrayData[0] = arrayData[i];
arrayData[i] = temp; HeadAjust(arrayData, 0, i - 1);
}
} /*
* 对于指定数组的序列,进行堆化调整 也就是将无序数组调整成堆。
*/
public static void HeadAjust(int[] arrayData, int beginIndex, int endIndex) {
int minNum = arrayData[beginIndex]; // i=beginIndex*2+1代表是左子节点
// i=i*2+1代表下一个左子节点
for (int i = beginIndex * 2 + 1; i <= endIndex; i = i * 2 + 1) {
//System.out.println(i);
// 先比较左子节点和右子节点, i存储小值的索引
if (i < endIndex && arrayData[i] > arrayData[i + 1]) {
i++;
} if (arrayData[i] > minNum) {
break;
} arrayData[beginIndex] = arrayData[i];
beginIndex = i;
} arrayData[beginIndex] = minNum;
}
}
执行结果:
9 8 7 6 5 4 3 2 1
时间复杂度:O(nlog2n) 参考这里http://blog.csdn.net/liliuteng/article/details/8496050, 说实在的,这个证明过程我还是看不太懂……数学基础不太好,过后需要再学习一下数学了。
空间复杂度:O(1)
学习资料
http://blog.csdn.net/clam_clam/article/details/6799763 本次总结大部分图是从这里来的…实在是懒着画了,抱歉抱歉
http://www.cnblogs.com/mengdd/archive/2012/11/30/2796845.html
http://blog.csdn.net/morewindows/article/details/6709644/
Hark的数据结构与算法练习之堆排序的更多相关文章
- Hark的数据结构与算法练习之锦标赛排序
算法说明 锦标赛排序是选择排序的一种. 实际上堆排序是锦标赛排序的优化版本,它们时间复杂度都是O(nlog2n),不同之处是堆排序的空间复杂度(O(1))远远低于锦标赛的空间复杂度(O(2n-1)) ...
- Hark的数据结构与算法练习之若领图排序ProxymapSort
算法说明 若领图排序是分布排序的一种. 个人理解,若领图排序算是桶排序+计数排序的变异版,桶排序计数排序理解了,那么若领图排序理解起来就会比较容易.区别其实就是存储中间值的方式做了调整…… 话说,这个 ...
- Hark的数据结构与算法练习之珠排序
---恢复内容开始--- 算法说明 珠排序是分布排序的一种. 说实在的,这个排序看起来特别的巧妙,同时也特别好理解,不过不太容易写成代码,哈哈. 这里其实分析的特别好了,我就不画蛇添足啦. 大家看一 ...
- Hark的数据结构与算法练习之鸽巢排序
算法说明 鸽巢排序是分布排序的一种,我理解其实鸽巢就是计数排序的简化版,不同之处就是鸽巢是不稳定的,计数排序是稳定的. 逻辑很简单,就是先找出待排数组的最大值maxNum,然后实例一个maxNum+1 ...
- Hark的数据结构与算法练习之圈排序
算法说明 圈排序是选择排序的一种.其实感觉和快排有一点点像,但根本不同之处就是丫的移动的是当前数字,而不像快排一样移动的是其它数字.根据比较移动到不需要移动时,就代表一圈结束.最终要进行n-1圈的比较 ...
- Hark的数据结构与算法练习之梳排序
算法说明梳排序是交换排序的一种,它其实也是改自冒泡排序,不同之处是冒泡排序的比较步长恒定为1,而梳排序的比较步长是变化的. 步长需要循环以数组长度除以1.3,到最后大于等于1即可. 光说可能比较抽象, ...
- Hark的数据结构与算法练习之地精(侏儒)排序
算法说明 地精排序是交换排序的一种,它是冒泡排序的一种改良,我感觉和鸡尾酒排序挺像的. 不同之处是鸡尾酒排序是从小到大,然后再从大到小切换着排序的.而地精排序是上来先从小到大排序,碰到交换到再从大到小 ...
- Hark的数据结构与算法练习之Bogo排序
算法说明 Bogo排序是交换排序的一种,它是一种随机排序,也是一种没有使用意义的排序,同样也是一种我觉得很好玩的排序. 举个形象的例子,你手头有一副乱序的扑克牌,然后往天上不停的扔,那么有一定机率会变 ...
- Hark的数据结构与算法练习之臭皮匠排序
算法说明 个人感觉是没有意义的算法,只是用来作为学术研究.或者说开拓一下思维. 从wikipedia copy来的一句解释的话:Stooge排序是一种低效的递归排序算法,甚至慢于冒泡排序.在<算 ...
随机推荐
- Serenity框架官方文档翻译(1-2开始、安装和界面)
1.开始 最好的和最快速地上手Serenity的方法是使用SERENE,它是一个示例应用程序模板. 您有2个选项来安装SERENE 模板到您的Visual Studio: 从Visual Studio ...
- cdrecord光盘烧录工具
我们是透过 cdrecord 这个命令来进行文字介面的烧录行为,这个命令常见的选项有底下数个: [root@www ~]# cdrecord -scanbus dev=ATA <==查询烧录机位 ...
- 初识suse-Linux相关!
Linux这种系统很奇怪,差不多每种不同的版本,它所使用的安装等一些重要命令皆有所变化.假若,你要熟练掌握一种OS,那么如果安装软件/应用,那是入门的第一步. 安装命令中: RedHat.CentOS ...
- 新的开始---cocos2d
今天是一个新的开始,cocos2d的环境搭配好了,并且打包案桌apk的环境也搭配好了,安卓的这个搭配环境还是出了一点问题,前面弄了两个晚上(11-12.30)没弄出来,中间好几天都没有去弄,今天光棍节 ...
- [codeforces 235]A. LCM Challenge
[codeforces 235]A. LCM Challenge 试题描述 Some days ago, I learned the concept of LCM (least common mult ...
- Android音频播放实例
MediaPlayer: 此类适合播放较大文件,此类文件应该存储在SD卡上,而不是在资源文件里,还有此类每次只能播放一个音频文件. 1.从资源文件中播放 MediaPlayer player = ne ...
- Leetcode 之Construct Binary Tree(52)
根据先序和中序构造二叉树.根据中序和后序构造二叉树,基础题,采用递归的方式解决,两题的方法类似.需要注意的是迭代器的用法. //先序和中序 TreeNode *buildTree(vector< ...
- MVC 修饰标签
MVC中的修饰标签有很多用途.它以修饰标签形式应用在控制器或控制器中的动作上. 最先想到的就是AcceptVerbs标签,在创建的时候,如果导航到创建视图,但不创建,则: public ActionR ...
- cas单点登录用户名为中文的解决办法
当用户名为中文时,登录后返回的用户名乱码.解决这个问题只需要在客户端的CAS Validation Filter中添加下配置就行了. <init-param> <param-name ...
- ExecutorService 和 NSOperationQueue
ExecutorService,简化了Android中的并发处理,NSOperationQueue简化了iOS中的并发处理.它们都管理线程池,作用十分相近,下面简单说明一下. 1.ExecutorSe ...