Lucene.net(4.8.0) 学习问题记录三: 索引的创建 IndexWriter 和索引速度的优化
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移。因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3.6.0 ,PanGu分词也是对应Lucene3.6.0版本的。不过好在Lucene.net 已经有了Core 2.0版本(4.8.0 bate版),而PanGu分词,目前有人正在做,貌似已经做完,只是还没有测试~,Lucene升级的改变我都会加粗表示。
Lucene.net 4.8.0
https://github.com/apache/lucenenet
PanGu分词(可以直接使用的)
https://github.com/SilentCC/Lucene.Net.Analysis.PanGu
JIEba分词(可以直接使用的)
https://github.com/SilentCC/JIEba-netcore2.0
Lucene.net 4.8.0 和之前的Lucene.net 3.6.0 改动还是相当多的,这里对自己开发过程遇到的问题,做一个记录吧,希望可以帮到和我一样需要升级Lucene.net的人。我也是第一次接触Lucene ,也希望可以帮助初学Lucene的同学。
一,Lucene 创建索引:IndexWriter
1.IndexWriter的介绍
IndexWriter 是用来创建和维护索引的。IndexWriter的创建:在Lucene4.8.0中,创建IndexWriter对象,需要用到IndexWriterConfig 参数,IndexWriterConfig用来设置一些IndexWriter的属性:
IndexWriterConfig _indexWriterConfig = new IndexWriterConfig(Lucene.Net.Util.LuceneVersion.LUCENE_48,analyze)
IndexWriter _indexWriter = new IndexWriter(dir,_indexWriterConfig)
上面的代码创建了一个基本的IndexWriter对象,每个基本IndexWriter都必须有两个必要的属性:1.操作的索引目录 dir ;2. 分词器 analyze .这里要注意,IndexWriter的分词器和IndexSearch的分词器应该是相同的,否则将会影响搜索结果。
我们通过IndexWriterConfig 可以设置IndexWriter的属性,已达到我们希望构建索引的需求,这里举一些属性,这些属性可以影响到IndexWriter写入索引的速度:
IndexWriterConfig.setRAMBufferSizeMB(double);
IndexWriterConfig.setMaxBufferedDocs(int);
IndexWriterConfig.setMergePolicy(MergePolicy)
setRAMBufferSizeMB() 是设置,当IndexWriter添加的文档的大小超过RAMBufferSizeMB ,IndexWriter就会把在内存中的操作,写入到硬盘中。具体一点:IndexWriter在执行AddDocuments(写入文档),DeleteDocuments(删除文档),UpdateDocuments(更新文档),这些操作的时候,这些操作都会先缓冲到内存中,也就是说执行完这些函数,其实储存的索引目录下是没有任何改变的,当AddDocuments的容量超过上述的属性的时候,这些操作才会具体执行到储存索引的硬盘当中。默认的DEFAULT_RAM_BUFFER_SIZE_MB 是16MB.
setMaxBufferedDocs() 是设置,当IndexWriter添加的文档数量超过MaxBufferedDocs的时候,IndexWriter就会把内存中写入的文档,写到硬盘中,并生成一个新的索引文件segment。关于Lucene的索引结构会在下面说到。
setMergePolicy 是设置索引合并的策略,MergePolicy中有一个参数DEFAULT_MAX_CFS_SEGMENT_SIZE 表示索引中最多有多少个segment文件。
1.1 提高索引的速度
上面提到了三个IndexWriterConfig的三个属性。我们知道,IndexWriter是当缓存中的容量达到一定的限制条件之后,才开始将缓存中的操作写入到硬盘中,事实上,如果我们把限制条件定的值越大,索引的速度是越快的。显而易见,如果设置RAMBufferSizeMB和MAXBufferedDocu越大,IndexWriter 写入硬盘的次数就越少,而写索引的时间耗费大多在对硬盘的操作之上。
IndexWriter写入索引之后,在索引目录里会有很多segment文件。segment文件数量达到MergeFactor (设置合并因子)的时候,IndexWriter会将这些segment文件合并,形成一个新的segment文件,类似于压缩。而在索引目录中,如果segment文件越多,则搜索的速度会降低,segement文件越少,搜索的速度也就越快。所以当我们设置MergeFactor的值越大的时候,搜索的速度就会越快,而合并segement的速度则会降低,也即索引的速度会降低。
2. 索引文件的结构
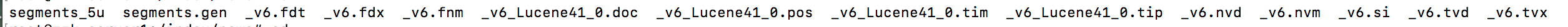
这是,一个索引目录下的索引文件。结构是这样的:
(索引)Index
---(段)Segment
---(文档)Document
--- (域)Field
--- (词)Term
上面的图片中,只有一个段,_v6.fdt ;_v6.fdx ....... 都属于_v6 segment中的内容。而segments_5u 和segments.gen 是段的元数据文件,也即它们保存了段的属性信息。
- XXX.fnm保存了此段包含了多少个域,每个域的名称及索引方式。
- XXX.fdx,XXX.fdt保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
- XXX.tvx,XXX.tvd,XXX.tvf保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
上面的是正向信息,还有反向信息就不详细说了。
3.IndexWriter的优化
在Lucene中IndexWriter.Optimize 用来优化索引,而在Lucene4.8.0中Optimize 已经更名为ForceMerge,为的是少让你使用。IndexWriter的优化实际上就是把Segment文件进行合并,你可以输入参数,ForceMerge(segments) 表示,合并到索引目录里最多有segments个段文件。而当参数越小的时候,也即合并的文件越多的时候,消耗的时间和空间就越大。很显然,合并是为了让我们的搜索速度变的更快。
在优化的过程中,需要当前索引容量两倍的空间,比如你现在的索引大小是40个G,在优化过程中,索引的大小会增加到80多个G,然后再合并直到最后只有30多个G。当你的索引更新不是特别频繁的时候,可以优化一下,如果更新特别频繁,那么调用ForceMerge就会效率很低,这个时候,我们可以设置上面提到过的MergeFactor来,让索引中segments文件少一些。
4.IndexWriter的注意事项
1.IndexWriter在操作一个索引的时候会创建一个锁定文件,Writer.lock 。如果有另一个IndexWriter要打开这个目录,将会报错。
2.IndexWriter实例是完全线程安全的,多个线程可以同时调用它的任何方法.
Lucene.net(4.8.0) 学习问题记录三: 索引的创建 IndexWriter 和索引速度的优化的更多相关文章
- Lucene.net(4.8.0) 学习问题记录五: JIEba分词和Lucene的结合,以及对分词器的思考
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Lucene.net(4.8.0) 学习问题记录六:Lucene 的索引系统和搜索过程分析
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Lucene.net(4.8.0) 学习问题记录二: 分词器Analyzer中的TokenStream和AttributeSource
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Lucene.net(4.8.0) 学习问题记录四: IndexWriter 索引的优化以及思考
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Lucene.net(4.8.0) 学习问题记录一:分词器Analyzer的构造和内部成员ReuseStategy
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Spring源码学习-容器BeanFactory(三) BeanDefinition的创建-解析Spring的默认标签
写在前面 上文Spring源码学习-容器BeanFactory(二) BeanDefinition的创建-解析前BeanDefinition的前置操作中Spring对XML解析后创建了对应的Docum ...
- Vue.js 2.0 学习重点记录
Vue.js兼容性 Vue.js.js 不支持 IE8 及其以下版本,因为 Vue.js.js 使用了 IE8 不能模拟的 ECMAScript 5 特性. Vue.js.js 支持所有兼容 EC ...
- bootstrap3.0学习笔记记录1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- thinkphp5.0学习笔记(三)获取信息,变量,绑定参数
1.构造函数: 控制器类必须继承了\think\Controller类,才能使用: 方法_initialize 代码: <?php namespace app\lian\controller; ...
随机推荐
- CentOS安装Nginx 报错“configure: error: the HTTP rewrite module requires the PCRE library”解决办法
错误提示: ./configure: error: the HTTP rewrite module requires the PCRE library. yum install gcc gc ...
- WebLogic部署报java.lang.ClassCastException: weblogic.xml.jaxp.RegistrySAXParserFactory cannot be cast to javax.xml.parsers.SAXParserFactory
今天在部署WebLogic项目时,报了java.lang.ClassCastException: weblogic.xml.jaxp.RegistrySAXParserFactory cannot b ...
- Python爬虫(八)_Requests的使用
Requests:让HTTP服务人类 虽然Python的标准库中urllib2模块中已经包含了平常我们使用的大多数功能,但是它的API使用起来让人感觉不太好,而Requests自称"HTTP ...
- (三)—Linux文件传输与mysql数据库安装
文件传输工具使用 为了速成,关于linux系统的学习都先放一放,用到哪个知识点就查哪个,这里想在linux下装一些服务练练手,最先想到的就是装个mysql数据库试试. 因为我用的是虚拟机下的li ...
- kafak集群安装-转
前言 最近在利用Spark streaming和Kafka构建一个实时的数据分析系统,对图书阅读数据进行分析,做实时推荐.Spark Streaming 模块是对于 Spark Core 的一个扩展, ...
- [Maven实战](7)坐标
1. 简单介绍 maven的世界中拥有数量很巨大的构件,也就是平时用的一些jar,war等文件. 在maven为这些构件引入坐标概念之前,我们无法使用不论什么一种方式来唯一标识全部这些构件. 因此,当 ...
- 【并查集】HDU 1325 Is It A Tree?
推断是否为树 森林不是树 空树也是树 成环不是树 数据: 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 1 0 0 1 2 2 3 4 5 0 0 2 5 0 0 ans: no ...
- 数据结构--二叉查找树的java实现
上代码: package com.itany.erchachazhaoshu; public class BinarySearchTree<T extends Comparable<? s ...
- 数据库管理工具神器-DataGrip,可同时管理多个主流数据库[SQL Server,MySQL,Oracle等]连接
前言 DataGrip:Jet Brains出品的一款数据库管理工具(没错,是Jet Brains出品,必属精品).DataGrip整合集成了当前主流数据库(如:SQL Server, MySQL, ...
- Python的几个常用模块
一.sys 用于提供对Python解释器相关的操作: sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version ...