机器学习:线性判别式分析(LDA)
1.概述
线性判别式分析(Linear Discriminant Analysis),简称为LDA。也称为Fisher线性判别(Fisher Linear Discriminant,FLD),是模式识别的经典算法,在1996年由Belhumeur引入模式识别和人工智能领域。
基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。
LDA与PCA都是常用的降维技术。PCA主要是从特征的协方差角度,去找到比较好的投影方式。LDA更多的是考虑了标注,即希望投影后不同类别之间数据点的距离更大,同一类别的数据点更紧凑。
但是LDA有两个假设:1.样本数据服从正态分布,2.各类得协方差相等。虽然这些在实际中不一定满足,但是LDA被证明是非常有效的降维方法,其线性模型对于噪音的鲁棒性效果比较好,不容易过拟合。
2.图解说明(图片来自网络)
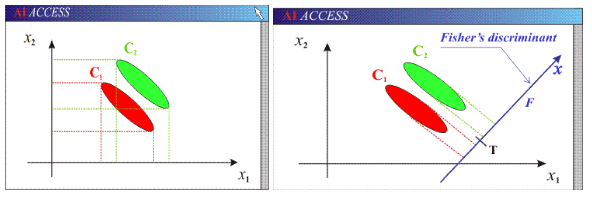
可以看到两个类别,一个绿色类别,一个红色类别。左图是两个类别的原始数据,现在要求将数据从二维降维到一维。直接投影到x1轴或者x2轴,不同类别之间会有重复,导致分类效果下降。右图映射到的直线就是用LDA方法计算得到的,可以看到,红色类别和绿色类别在映射之后之间的距离是最大的,而且每个类别内部点的离散程度是最小的(或者说聚集程度是最大的)。
3.图解LAD与PCA的区别(图片来自网络)
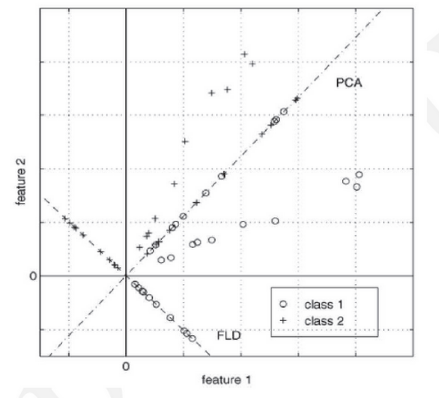
两个类别,class1的点都是圆圈,class2的点都是十字。图中有两条直线,斜率在1左右的这条直线是PCA选择的映射直线,斜率在 -1左右的这条直线是LDA选择的映射直线。其余不在这两条直线上的点是原始数据点。可以看到由于LDA考虑了“类别”这个信息(即标注),映射后,可以很好的将class1和class2的点区分开。
4.LAD与PCA的对比
(1)PCA无需样本标签,属于无监督学习降维;LDA需要样本标签,属于有监督学习降维。二者均是寻找一定的特征向量w来降维的,其中LDA抓住样本的判别特征,PCA则侧重描叙特征。概括来说,PCA选择样本点投影具有最大方差的方向,LDA选择分类性能最好的方向。
(2)PCA降维是直接和特征维度相关的,比如原始数据是d维的,那么PCA后可以任意选取1维、2维,一直到d维都行。LDA降维是直接和类别的个数C相关的,与数据本身的维度没关系,比如原始数据是d维的,一共有C个类别,那么LDA降维之后,一般就是1维,2维到C-1维进行选择。要求降维后特征向量维度大于C-1的,不能使用LDA。
(3)PCA投影的坐标系都是正交的,而LDA根据类别的标注关注分类能力,因此不保证投影到的坐标系是正交的(一般都不正交)
5.LAD的使用限制
(1)LDA至多可生成C-1维子空间
LDA降维后的维度区间在[1,C-1],与原始特征数n无关,对于二值分类,最多投影到1维。
(2)LDA不适合对非高斯分布样本进行降维。如下图所示的数据分布分类效果不好

(3)LDA在样本分类信息依赖方差而不是均值时,效果不好。
6.实验及讲解
1)生成实验数据,如下图:
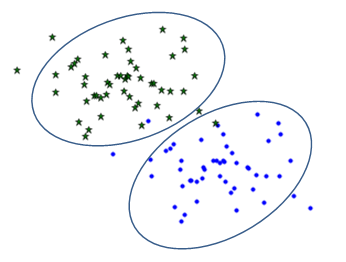
寻找一条直线,使按照椭圆圈出的分类进行投影,使得投影后模式样本在新的子空间有最大的类间距离和最小的类内距离。
2)核心函数
a)sklearn.discriminant_analysis.LinearDiscriminantAnalysis
b)主要参数(详细参数)
n_components :减少到多少维空间
c)主要属性
coef_ :权重。如果是投影到一维空间,则两个值对应的是直线的斜率和截距。
classes_ :分类
3)详细代码
from sklearn.datasets.samples_generator import make_blobs
import numpy as np
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from itertools import cycle ##产生随机数据的中心
centers = [[2.5, 2],[1.8, 3] ]
##产生的数据个数
n_samples=100
##生产数据
X, labels = make_blobs(n_samples=n_samples, centers= centers, cluster_std=0.3,
random_state =0) clf = LinearDiscriminantAnalysis()
clf.fit(X,labels) ##直线的斜率和截距
#print(clf.coef_) #-7.16451571 10.65392594] ##选取两个数进行预测
#print(clf.predict([[1.8, 3.2]])) #1
#print(clf.predict([[2.7, 1.7]]))#0 ##读取直线的斜率和截距
k1 = clf.coef_[0,0]
b1 = clf.coef_[0,1] ##绘图
plt.figure(1)
plt.clf() '''
说明:
1)为了方便计算及说明,函数式1、2都采用了近似值
y的斜率为-7.165,所以y1的斜率为0.14
2)由于近似值或者绘图精度的问题,当y1斜率为0.14时与y不垂直,
效果图中的绿色直线是下面函数绘制的:y1=0.37*x+1.7,即斜率为0.37
'''
#画LDA直线
x=np.linspace(0,4,50) ##在0-15直接画100个连续点
#y=k1*x+b1
y=-7.165*x+10.7 ##函数式1
plt.plot(x,y,color="red",linewidth=2)
#画与LDA直线垂直的直线
y1=0.14*x+2.2 ##函数式2
#y1=0.37*x+1.7 ##这个函数仅仅是为了绘制效果图用
plt.plot(x,y1,color="g",linewidth=2) colors = cycle('mykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(len(clf.classes_)), colors):
##根据lables中的值是否等于k,重新组成一个True、False的数组
my_members = labels == k
##X[my_members, 0] 取出my_members对应位置为True的值的横坐标
plt.plot(X[my_members, 0], X[my_members, 1],'o',c = col ,markersize=4) plt.axis([0, 4, 0, 5])
plt.show()
4)结果图
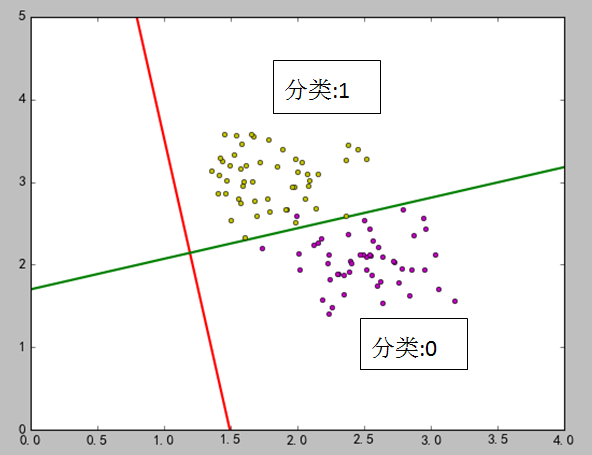
在上图中,红线是LDA之后求出来的,绿线是通过数学的两直线相交的关系求出来的。在代码中,选取了两个点:[1.8, 3.2],[2.7, 1.7],如果直接用训练出的模型进行预测,点[1.8, 3.2] 属于类型1,点[2.7, 1.7]属于类型0.如果通过线与点的关系,使用绿线进行判断,0.14×1.8+2.2=2.45 <3.2,所以点[1.8, 3.2]在绿线上面,因此属于分类1。0.14×2.7+2.2=2.578>1.7,所以点[2.7, 1.7]在绿线下面,因此属于分类0.
对应投影是一维的情况,个人感觉如果能求出绿线的方程,无论是从预测计算还是理解,都比较方便。但是由于样本点分布的不确定性,绿线的斜率好求,但是截距难找,所以LDA算法并没有给出相关的属性内容。
机器学习:线性判别式分析(LDA)的更多相关文章
- 【LDA】线性判别式分析
1. LDA是什么 线性判别式分析(Linear Discriminant Analysis),简称为LDA.也称为Fisher线性判别(Fisher Linear Discriminant,FLD) ...
- 吴裕雄 python 机器学习——线性判断分析LinearDiscriminantAnalysis
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- PCA主成分分析 ICA独立成分分析 LDA线性判别分析 SVD性质
机器学习(8) -- 降维 核心思想:将数据沿方差最大方向投影,数据更易于区分 简而言之:PCA算法其表现形式是降维,同时也是一种特征融合算法. 对于正交属性空间(对2维空间即为直角坐标系)中的样本点 ...
- 机器学习入门-线性判别分析(LDA)1.LabelEncoder(进行标签的数字映射) 2.LinearDiscriminantAnalysis (sklearn的LDA模块)
1.from sklearn.processing import LabelEncoder 进行标签的代码编译 首先需要通过model.fit 进行预编译,然后使用transform进行实际编译 2. ...
- 吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 机器学习笔记簿 降维篇 LDA 01
机器学习中包含了两种相对应的学习类型:无监督学习和监督学习.无监督学习指的是让机器只从数据出发,挖掘数据本身的特性,对数据进行处理,PCA就属于无监督学习,因为它只根据数据自身来构造投影矩阵.而监督学 ...
- 线性判别分析(LDA), 主成分分析(PCA)及其推导【转】
前言: 如果学习分类算法,最好从线性的入手,线性分类器最简单的就是LDA,它可以看做是简化版的SVM,如果想理解SVM这种分类器,那理解LDA就是很有必要的了. 谈到LDA,就不得不谈谈PCA,PCA ...
- 机器学习中的数学-线性判别分析(LDA), 主成分分析(PCA)
转:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html 版权声明: 本文由L ...
- 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
随机推荐
- java8 Lambda表达式的新手上车指南(1)
背景 java9的一再推迟发布,似乎让我们恍然想起离发布java8已经过去了三年之久,java8应该算的上java语言在历代版本中变化最大的一个版本了,最大的新特性应该算得上是增加了lambda表达式 ...
- 一文读懂 HTTP/2 特性
HTTP/2 是 HTTP 协议自 1999 年 HTTP 1.1 发布后的首个更新,主要基于 SPDY 协议.由互联网工程任务组(IETF)的 Hypertext Transfer Protocol ...
- 安装php提示 configure: error: Cannot find OpenSSL's libraries 解决方案
一次在安装php7其中提示错误信息 configure: error: Cannot find OpenSSL's libraries 出现这种有2中情况,一种是没有安装 openssl,另一种是安装 ...
- bzoj1087 [SCOI2005]互不侵犯
Description 在N×N的棋盘里面放K个国王,使他们互不攻击,共有多少种摆放方案.国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共8个格子. Input 只有一行,包 ...
- 忘记了root密码,如何进入系统?
Issue 问题 忘记了root密码不能进入系统 如何进入系统? 环境 红帽企业版Linux所有版本 解决方法 可以进入单用户模式或者援救模式来改变root密码,如何进入单用户模式取决引导加载程序. ...
- centos下搭建redis集群
必备的工具: redis-3.0.0.tar redis-3.0.0.gem (ruby和redis接口) 分析: 首先,集群数需要基数,这里搭建一个简单的redis集群(6个redis实 ...
- 转:CentOS---网络配置详解
一.配置文件详解在RHEL或者CentOS等Redhat系的Linux系统里,跟网络有关的主要设置文件如下: /etc/host.conf 配置域名服务客户端的控制文件/etc/hos ...
- Java学习笔记——排序算法之快速排序
会当凌绝顶,一览众山小. --望岳 如果说有哪个排序算法不能不会,那就是快速排序(Quick Sort)了 快速排序简单而高效,是最适合学习的进阶排序算法. 直接上代码: public class Q ...
- 怎么在vue中使用less
最近使用vue2.0重构项目, 使用vue-cli脚手架构建, 采用webpack模板, 要在项目中使用less进行样式的编写 首先, 打开终端, 在当前项目目录下安装less npm install ...
- 【AngularJS中的自定义服务service VS factory VS provider】---它们的区别,你知道么?
在介绍AngularJS自定义服务之前,我们先来了解一下AngularJS~ 学过HTML的人都知道,HTML是一门很好的伪静态文本展示设计的声明式语言,但是,要构建WEB应用的话它就显得乏力了. 而 ...