Backpropagation 算法的推导与直观图解
摘要
本文是对 Andrew Ng 在 Coursera 上的机器学习课程中 Backpropagation Algorithm 一小节的延伸。文章分三个部分:第一部分给出一个简单的神经网络模型和 Backpropagation(以下简称 BP)算法的具体流程。第二部分以分别计算第一层和第二层中的第一个参数(parameters,在神经网络中也称之为 weights)的梯度为例来解释 BP 算法流程,并给出了具体的推导过程。第三个部分采用了更加直观的图例来解释 BP 算法的工作流程。
注:1. 为了方便讨论,省去了 Bias unit,并在第二部分的讨论中省去了 cost function 的正则化项
2. 如果熟悉 Ng 课程中使用的字符标记,则推荐的阅读顺序为:第一、第三、第二部分
第一部分 BP 算法的具体过程
图 1.1 给出了一个简单的神经网络模型(省去了 Bias unit):

图 1.1 一个简单的神经网络模型
其中字符标记含义与 Ng 课程中的一致:
\(x_1, x_2, x_3 \) 为输入值,也即 \(x^{(i)}\) 的三个特征;
\(z^{(l)}_{(j)}\) 为第 l 层的第 j 个单元的输入值。
\(a^{(l)}_{(j)}\) 为第 l 层的第 j 个单元的输出值。其中 a = g(z),g 为 sigmoid 函数。
\(\Theta_{ij}^{(l)}\) 第 l 层到 l+1 层的参数(权重)矩阵。
表 1.1 BP 算法的具体流程(Matlab 伪代码)
1 for i = m,
2 \(a^{(1)} = x ^{(i)};\)
3 使用前馈传播算法计算 \(a^{(2)}, a^{(3)};\)
4 \(\delta^{(3)} = a^{(3)} - y^{(i)};\)
5 \(\delta^{(2)} = (\Theta^{(2)})^T * \delta^{(3)} .* g\prime(z^{(2)});\) # 第 2 个运算符 ' .* ' 为点乘,即按元素操作
6 \(\Delta^{(2)} = \Delta^{(2)} + a^{(2)} * \delta^{(3)};\)
7 \(\Delta^{(1)} = \Delta^{(1)} + a^{(1)} * \delta^{(2)};\)
8 end;
第二部分 BP 算法步骤的详解与推导过程
BP 算法的目的在于为优化函数(比如梯度下降、其它的高级优化方法)提供梯度值,即使用 BP 算法计算代价函数(cost function)对每个参数的偏导值,其数学形式为:\(\frac{\partial}{\partial{\Theta^l_{ij}}}J(\Theta)\),并最终得到的值存放在矩阵 \(\Delta^{(l)}\) 中。
其中 K 个输出的 J(Θ) 为:
\[J(\Theta) = -\frac{1}{m}\sum_{i=1}^m\sum_{k=1}^K[y^{(i)}_klog(h_\Theta(x^{(i)})_k) + (1-y_k^{(i)})log(1-h_\Theta(x^{(i)})_k)]\]
接下来,以计算 \(\Theta_{11}^{(1)}, \Theta_{11}^{(2)}\) 为例来给出 BP 算法的详细步骤。对于第 i 个训练用例的第 1 个特征,其代价函数为:
\[J(\Theta) = -[y^{(i)}_klog(h_\Theta(x^{(i)})_k) + (1-y_k^{(i)})log(1-h_\Theta(x^{(i)})_k)] (式 1)\]
其中 \(h_\Theta(x) = a^{l} = g(z^{(l)})\), g 为 sigmoid 函数。
计算 \(\Theta_{11}^{(2)}\):
\[\frac{\partial J(\Theta)}{\partial \Theta_{11}^{(2)}} = \frac{\partial J(\Theta)}{\partial a_1^{3}} * \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}} * \frac{\partial z_1^{(3)}}{\partial \Theta_{11}^{(2)}} (式 2)\]
先取出式 2 中等号右边前两项,并将其记为 \(\delta_1^{(3)}\):
\[\delta_1^{(3)} = \frac{\partial J(\Theta)}{\partial a_1^{3}} * \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}} (式 3)\]
这里给出 \(\delta^{(l)}\) 的定义,即:
\[\delta^{(l)} = \frac{\partial}{\partial z^{(l)}}J(\Theta)^{(i)} (式 4)\]
对式 3 进行详细计算,即将 J(Θ)
对 \(z_1^{(3)}\) 求偏导(计算过程中简记为 z):
\[\delta_1^{(3)} = \frac{\partial J(\Theta)}{\partial a_1^{(3)}} * \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}}\]
\[=-[y * \frac{1}{g(z)}*g\prime(z) + (1-y)*\frac{1}{1 - g(z)}*(-g\prime(z))]\]
\[=-[y*(1-g(z))+(y-1)*g(z)]\]
\[=g(z)-y =a^{(3)-y}\]
其中用到了 sigmoid 函数的一个很好的性质:
\[g\prime(z)=g(z) * (1-g\prime(z)) (易证)\]
这样便得到了表 1.1 中 BP 算法的第四行过程。
接下来观察式 2 中等号右边最后一项 \(\frac{\partial z_1^{(3)}}{\partial \Theta_{11}^{(2)}}\):
其中 \(z_1^{(3)}=\Theta_{11}^{(2)}*a_1^{(2)}+\Theta_{12}^{(2)}*a_2^{(2)}+\Theta_{13}^{(2)}*a_3^{(2)}\),则易得:
\[\frac{\partial z_1^{(3)}}{\partial \Theta_{11}^{(2)}}=a_1^{(2)} (式 5)\]
再回头观察最初的式 2,代入式 3 和式 5,即可得到:
\[\frac{\partial J(\Theta)}{\partial \Theta_{11}^{(2)}} = \delta_1^{(3)} * a_1^{(2)}\]
这样便推导出了表 1.1 中 BP 算法的第六行过程。
至此,就完成了对 \(\Theta_{11}^{(2)}\) 的计算。
计算 \(\Theta_{11}^{(2)}\):
\[\frac{\partial J(\Theta)}{\partial \Theta_{11}^{(1)}} = \frac{\partial J(\Theta)}{\partial a_1^{3}} * \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}}*\frac{\partial z_1^{(3)}}{\partial a_1^{(2)}}*\frac{\partial a_1^{(2)}}{\partial z_1^{(2)}}*\frac{\partial z_1^{(2)}}{\partial \Theta_{11}^{(1)}} (式 6)\]
类似地,根据式 4 中对 \(\delta^{(l)}\) 的定义,可以把上式(即式 6)等号右边前四项记为 \(\delta_1^{(2)}\) 。即:
\[\delta_1^{(2)}=\frac{\partial J(\Theta)}{\partial a_1^{3}} * \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}}*\frac{\partial z_1^{(3)}}{\partial a_1^{(2)}}*\frac{\partial a_1^{(2)}}{\partial z_1^{(2)}} (式 7)\]
可以发现式 3 中的 \(\delta_1^{(3)}\) 是这个等式右边的前两项。
于是 \(\delta^{(l)}\) 的意义就体现出来了:它是用来保存上一次计算的部分结果。在计算 \(\delta^{(l-1)}\) 时,可以使用这个部分结果继续向下逐层求偏导。这样在神经网络特别复杂、有大量计算时就可以节省大量重复的运算,从而有效地提高神经网络的学习速度。
继续观察式 7,其等号右边第三项易算得(已知 \(z_1^{(3)}=\Theta_{11}^{(2)}*a_1^{(2)}+\Theta_{12}^{(2)}*a_2^{(2)}+\Theta_{13}^{(2)}*a_3^{(2)}\)):
\[\frac{\partial z_1^{(3)}}{\partial a_1^{(2)}} = \Theta_{11}^{(2)} (式 8)\]
式 7 等号右边最后一项为:
\[\frac{\partial a_1^{(2)}}{\partial z_1^{(2)}}=g\prime(z_1^{(2)}) (式 9) \]
将 \(\delta_1^{(3)}\)、式 8、式 9 代入式 7,即可得到:
\[\delta_1^{(2)}=\delta_1^{(3)}*\Theta_{11}^{(2)}*g\prime(z_1^{(2)}) (式 10)\]
这样便推导出了表 1.1 中 BP 算法第五行过程。
接下来继续计算式 6 中等号右边最后一项,已知 \(z_1^{(2)}=\Theta_{11}^{(1)}*a_1^{(1)}+\Theta_{12}^{(1)}*a_2^{(1)}+\Theta_{13}^{(1)}*a_3^{(1)}\),易得:
\[\frac{\partial z_1^{(2)}}{\partial \Theta_{11}^{(1)}}=a_1^{(1)} (式 11)\]
将式 10、式 11 代入最开始的式 6 即可得:
\[\frac{\partial J(\Theta)}{\partial \Theta_{11}^{(1)}} =\delta_1^{(2)} * a_1^{(1)}\]
如此,即可得到表 1.1 中 BP 算法的第七行过程。
至此,就完成了对 \(\Theta_{11}^{(1)}\) 的计算。
第三部分 BP 算法的直观图解
神经网络学习算法图概览
给定一个函数 f(x),它的首要求导对象是什么?就是它的输入值,是自变量 x。那 f(g(x)) 呢?即把g(x) 当作一个整体作为它的输入值,它的自变量。那么 g(x) 这个整体就是它的首要求导对象。因此,一个函数的求导对象是它的输入值,是它的自变量。弄清楚这一点,才能在求多元函数偏导的链式法则中游刃有余。
图 3.1 自下而上,每一个框是上面一个框的输入值,也即上面一个框中函数的自变量。这张图明确了神经网络中各数据之间的关系——谁是谁的输入值,图中表现得非常清楚。上段提到一个函数的求导对象是它的输入值,那么通过图 3.1 就能非常方便地使用链式法则,也能清楚地观察到 BP 算法的流程(后面一个小节会给出一个更具体的 BP 流程图)。
对照文首给出的图 1.1 神经网络的模型图,应该很容易理解图 3.1 的含义,它大致地展现了神经网络的学习(训练)流程。前馈传播算法自下而上地向上计算,最终可以得到 \(a^{(3)}\),进一步可以计算得到 J(Θ)。而 BP 算法自顶向下,层层求偏导,最终得到了每个参数的梯度值。下面一个小节将仔细介绍本文的主题,即 BP 算法的流程图解。
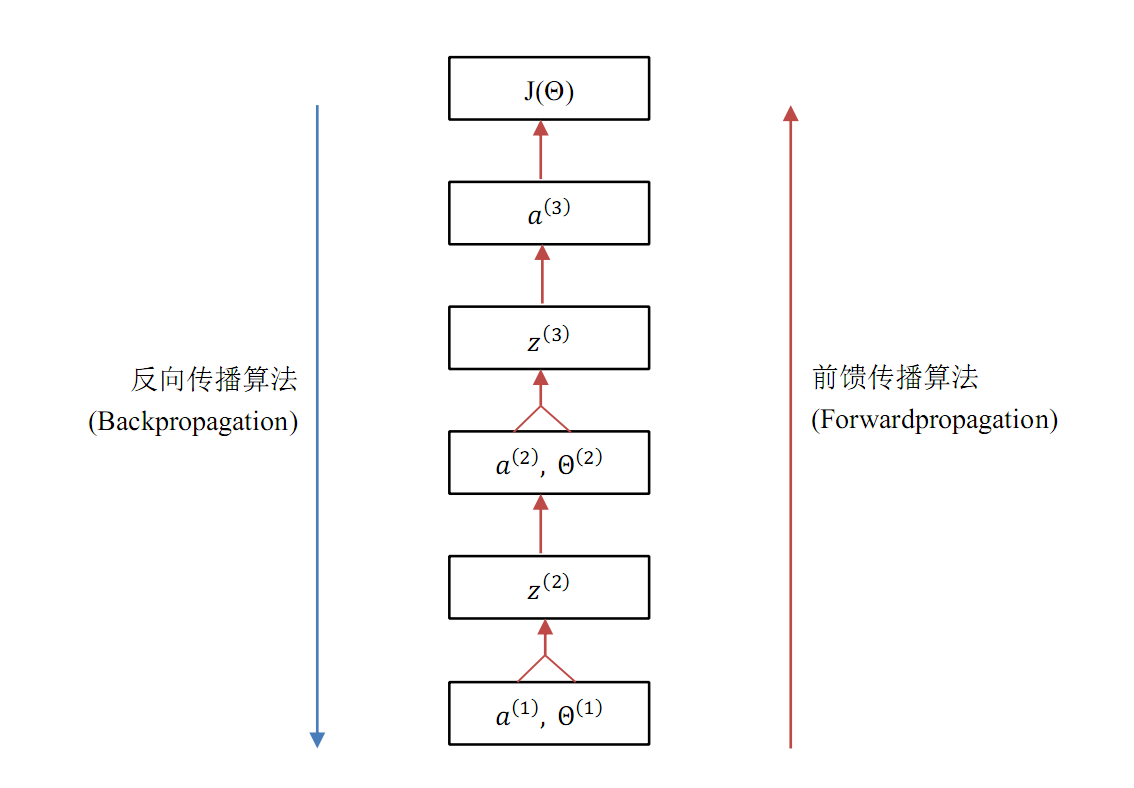
图 3.1 神经网络学习算法概览
BP 算法的直观图解
图 3.2 给出了 BP 算法的计算流程,并附上了具体的计算步骤。BP 算法的流程在这张图中清晰可见:自顶向下(对应神经网络模型为自输出层向输入层)层层求偏导。因为神经网络的复杂性,人们总是深陷于求多元函数偏导的泥潭中无法自拔:到底该对哪个变量求导?图 3.2 理顺了神经网络中各数据点之间的关系,谁是谁的输入值,谁是谁的函数一清二楚,然后就可以畅快地使用链式法则了。
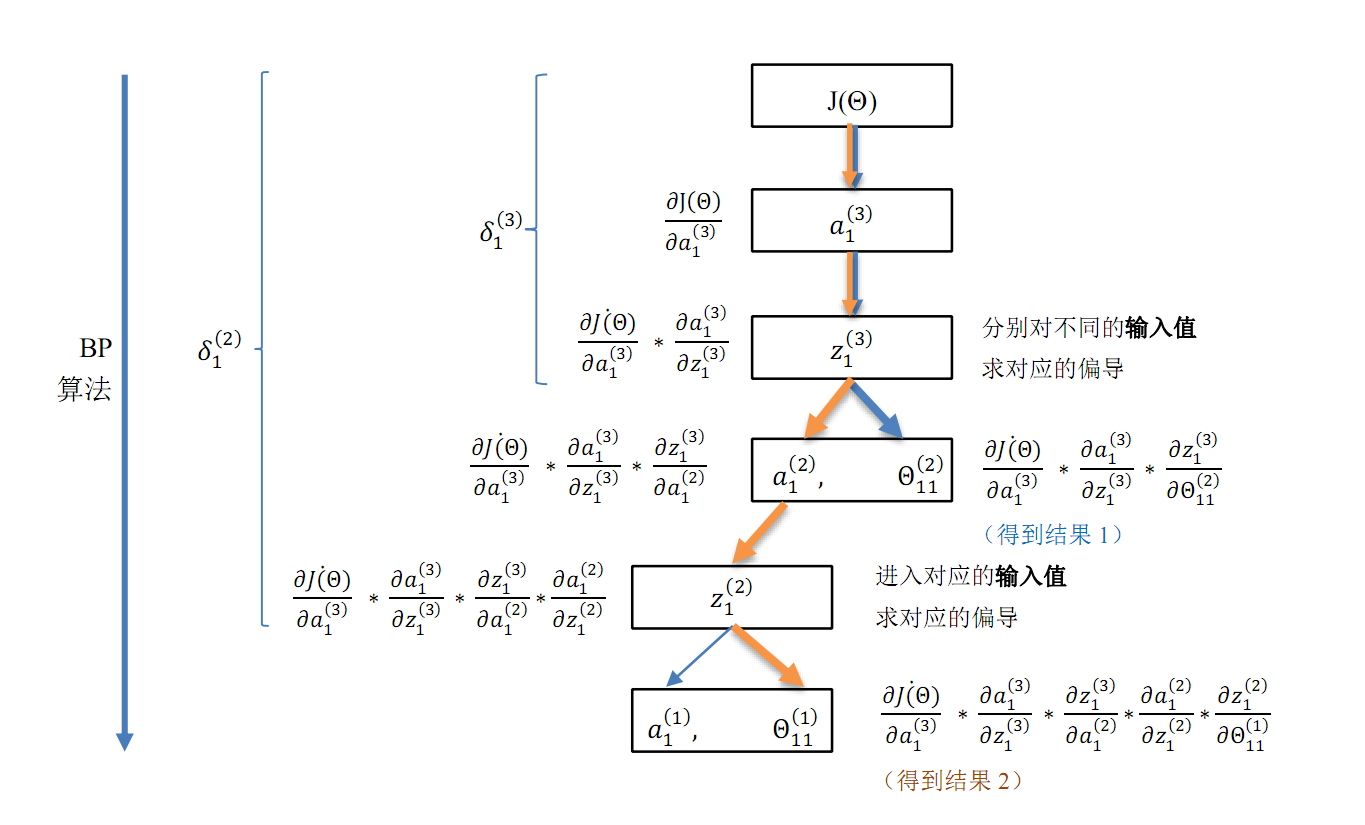
图3.2 BP 算法流程
所以 BP 算法即反向传播算法,就是自顶向下求代价函数(J(Θ))对各个参数(\(\Theta_{ij}^{(l)}\))偏导的过程,对应到神经网络模型中即自输出层向输入层层层求偏导。在图 3.2 中,当反向传播到 \(a_1^{(2)}\) 结点时,遇到分叉路口:选择对 \(\Theta_{11}^{(2)}\) 求偏导,即可得到第二层的参数梯度。而若选择对 \(a_1^{(2)}\) 这条路径继续向下求偏导,就可以继续向下(即输出层)传播,继续向下求偏导,最终可得到第一层的参数梯度,于是就实现了 BP 算法的目的。在选择分叉路口之前,使用 \(\delta^{(l)}\) 来保存到达分岔路口时的部分结果(本文的第二部分对 \(\delta^{(l)}\) 做出了精确定义)。那么如果选择继续向下求偏导,则还可以使用这个部分结果继续向下逐层求偏导。从而避免了大量的重复计算,有效地提升了神经网络算法的学习速度。
因此可以观察到 BP 算法两个突出特点:
1) 自输出层向输入层(即反向传播),逐层求偏导,在这个过程中逐渐得到各个层的参数梯度。
2) 在反向传播过程中,使用 \(\delta^{(l)}\) 保存了部分结果,避免了大量的重复运算,因而该算法性能优异。
1. 转载时请在文首注明来源,谢谢。
2. 如果觉得本篇文章对你有帮助,还可以请我喝杯茶。: )

Backpropagation 算法的推导与直观图解的更多相关文章
- 神经网络与深度学习(3):Backpropagation算法
本文总结自<Neural Networks and Deep Learning>第2章的部分内容. Backpropagation算法 Backpropagation核心解决的问题: ∂C ...
- Python算法:推导、递归和规约
Python算法:推导.递归和规约 注:本节中我给定下面三个重要词汇的中文翻译分别是:Induction(推导).Recursion(递归)和Reduction(规约) 本节主要介绍算法设计的三个核心 ...
- BP算法的推导
反向传播算法的推导 如图为2-layers CNN,输入单元下标为i,数量d:隐层单元下表j,数量\(n_H\):输出层下表k,单元数量c 1.目标 调整权系数\(w_{ji}\),\(w_{kj}\ ...
- backpropagation算法示例
backpropagation算法示例 下面举个例子,假设在某个mini-batch的有样本X和标签Y,其中\(X\in R^{m\times 2}, Y\in R^{m\times 1}\),现在有 ...
- EM算法简易推导
EM算法推导 网上和书上有关于EM算法的推导,都比较复杂,不便于记忆,这里给出一个更加简短的推导,用于备忘. 在不包含隐变量的情况下,我们求最大似然的时候只需要进行求导使导函数等于0,求出参数即可.但 ...
- EM算法-完整推导
前篇已经对EM过程,举了扔硬币和高斯分布等案例来直观认识了, 目标是参数估计, 分为 E-step 和 M-step, 不断循环, 直到收敛则求出了近似的估计参数, 不多说了, 本篇不说栗子, 直接来 ...
- BP算法基本原理推导----《机器学习》笔记
前言 多层网络的训练需要一种强大的学习算法,其中BP(errorBackPropagation)算法就是成功的代表,它是迄今最成功的神经网络学习算法. 今天就来探讨下BP算法的原理以及公式推导吧. 神 ...
- 【机器学习】EM算法详细推导和讲解
今天不太想学习,炒个冷饭,讲讲机器学习十大算法里有名的EM算法,文章里面有些个人理解,如有错漏,还请读者不吝赐教. 众所周知,极大似然估计是一种应用很广泛的参数估计方法.例如我手头有一些东北人的身高的 ...
- EM算法以及推导
EM算法 Jensen不等式 其实Jensen不等式正是我们熟知的convex函数和concave函数性质,对于convex函数,有 \[ \lambda f(x) + (1-\lambda)f(y) ...
随机推荐
- CentOS7安装docker 启动不了解决篇
[root@test ~]# yum update [root@test ~]# yum install docker [root@test ~]# service docker start Redi ...
- EL表达式拼接字符串
EL表达式拼接字符串<c:set var="types" value="${','}${resMap['vo'].lineType }${','}" &g ...
- select onchagnge 弹出自己的文本值
select onchagnge 弹出自己的文本值onchange='alert($("option:selected",this).text())'
- 验证表格多行某一input是否为空
function checkTableKeyWordVal(tableId){ var result = true; $("#"+tableId+" tbody tr&q ...
- jquery hide和show使用
$("#qitarenyuanDiv").hide("fast");$("#qitarenyuanDiv").show("fast ...
- 实现自己的.NET Core配置Provider之EF
<10分钟就能学会.NET Core配置>里详细介绍了.NET Core配置的用法,另外我还开源了自定义的配置Provider:EF配置Provider和Yaml配置Provider.本文 ...
- Tp框架获取客户端IP地址
/** * 获取客户端IP地址 * @param integer $type 返回类型 0 返回IP地址 1 返回IPV4地址数字 * @return mixed */ function get_cl ...
- HBuilder使用方法
/*注:本教程针对HBuilder5.0.0,制作日期2014-12-31*/创建HTML结构: h 8 (敲h激活代码块列表,按8选择第8个项目,即HTML代码块,或者敲h t Enter)中途换行 ...
- 【转】Header Only Library的介绍
什么是Header Only Library Header Only Library把一个库的内容完全写在头文件中,不带任何cpp文件. 这是一个巧合,决不是C++的原始设计. 第一次这么做估计是ST ...
- Vijos 1034 家族 并查集
描述 若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系. 规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚.如果x,y是亲戚 ...