python实现折半查找算法&&归并排序算法
今天依旧是学算法,前几天在搞bbs项目,界面也很丑,评论功能好像也有BUG。现在不搞了,得学下算法和数据结构,笔试过不了,连面试的机会都没有……
今天学了折半查找算法,折半查找是蛮简单的,但是归并排序我就挺懵比,看教材C语言写的归并排序看不懂,后来参考了别人的博客,终于搞懂了。
折半查找
先看下课本对于 折半查找的讲解。注意了,折半查找是对于有序序列而言的。每次折半,则查找区间大约缩小一半。low,high分别为查找区间的第一个下标与最后一个下标。出现low>high时,说明目标关键字在整个有序序列中不存在,查找失败。

看我用python编程实现:
def BinSearch(array, key, low, high):
mid = int((low+high)/2)
if key == array[mid]: # 若找到
return array[mid]
if low > high:
return False if key < array[mid]:
return BinSearch(array, key, low, mid-1) #递归
if key > array[mid]:
return BinSearch(array, key, mid+1, high) if __name__ == "__main__":
array = [4, 13, 27, 38, 49, 49, 55, 65, 76, 97]
ret = BinSearch(array, 76, 0, len(array)-1) # 通过折半查找,找到65
print(ret)
输出: 在列表中查找76.
76
时间复杂度:O(logn)
归并排序算法
先阐述一下排序思路:
首先归并排序使用了二分法,归根到底的思想还是分而治之。归并排序是指把无序的待排序序列分解成若干个有序子序列,并把有序子序列合并为整体有序序列的过程。长度为1的序列是有序的。因此当分解得到的子序列长度大于1时,应继续分解,直到长度为1.
(下图是分解过程,图自http://www.cnblogs.com/piperck/p/6030122.html)

合并的过程如下:

很好,你现在可以和别人说,老子会归并排序了。但是让你写代码出来,相信你是不会的……
来来来,看我用python写的归并排序算法:
def merge_sort(array): # 递归分解
mid = int((len(array)+1)/2)
if len(array) == 1: # 递归结束的条件,分解到列表只有一个数据时结束
return array
list_left = merge_sort(array[:mid])
list_right = merge_sort(array[mid:])
print(">>>list_left:", list_left)
print(">>>list_right:", list_right)
return merge(list_left, list_right) # 进行归并 def merge(list_left, list_right): # 进行归并
final = []
while list_left and list_right:
if list_left[0] <= list_right[0]: # 如果将"<="改为"<",则归并排序不稳定
final.append(list_left.pop(0))
else:
final.append(list_right.pop(0)) return final+list_left+list_right # 返回排序好的列表 if __name__=="__main__":
array = [49, 38, 65, 97, 76]
print(merge_sort(array))
输出:
>>>list_left: [49]
>>>list_right: [38]
>>>list_left: [38, 49]
>>>list_right: [65]
>>>list_left: [97]
>>>list_right: [76]
>>>list_left: [38, 49, 65]
>>>list_right: [76, 97]
[38, 49, 65, 76, 97]
时间度杂度: 平均情况=最好情况=最坏情况=O(nlogn)
空间复杂度: O(n)
稳定性: 稳定
对序列{ 6, 5, 3, 1, 8, 7, 2, 4 }进行归并排序的实例如下:
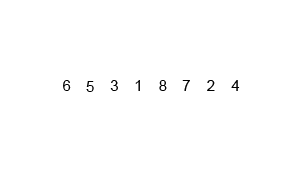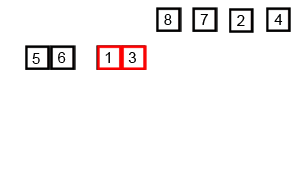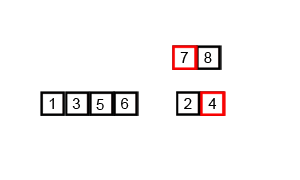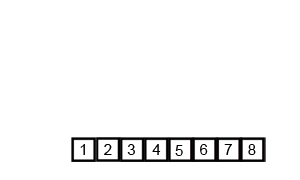
使用归并排序为一列数字进行排序的宏观过程:

python实现折半查找算法&&归并排序算法的更多相关文章
- Sqrt(X),求平方根,折半查找
算法分析:利用折半查找,降低算法复杂度.前面求x得y次幂,也是将y/2,都是为了降低复杂度. //折半查找的思想 public class Sqrt { public int sqrt(int x) ...
- 常用查找数据结构及算法(Python实现)
目录 一.基本概念 二.无序表查找 三.有序表查找 3.1 二分查找(Binary Search) 3.2 插值查找 3.3 斐波那契查找 四.线性索引查找 4.1 稠密索引 4.2 分块索引 4.3 ...
- 算法与数据结构(九) 查找表的顺序查找、折半查找、插值查找以及Fibonacci查找
今天这篇博客就聊聊几种常见的查找算法,当然本篇博客只是涉及了部分查找算法,接下来的几篇博客中都将会介绍关于查找的相关内容.本篇博客主要介绍查找表的顺序查找.折半查找.插值查找以及Fibonacci查找 ...
- 算法笔记_026:折半查找(Java)
目录 1 问题描述 2 解决方案 2.1 递归法 2.2 迭代法 1 问题描述 首先,了解一下何为折半查找?此处,借用<算法设计与分析基础>第三版上一段文字介绍: 2 解决方案 2.1 递 ...
- C语言查找算法之顺序查找、二分查找(折半查找)
C语言查找算法之顺序查找.二分查找(折半查找),最近考试要用到,网上也有很多例子,我觉得还是自己写的看得懂一些. 顺序查找 /*顺序查找 顺序查找是在一个已知无(或有序)序队列中找出与给定关键字相同的 ...
- 算法与数据结构基础 - 折半查找(Binary Search)
Binary Search基础 应用于已排序的数据查找其中特定值,是折半查找最常的应用场景.相比线性查找(Linear Search),其时间复杂度减少到O(lgn).算法基本框架如下: //704. ...
- Java实现三种常用的查找算法(顺序查查找,折半查找,二叉排序树查找)
public class Search { public class BiTreeNode{ int m_nValue; BiTreeNode m_pLeft; BiTreeNode m_pRight ...
- 算法学习记录-查找——折半查找(Binary Search)
以前有个游戏,一方写一个数字,另一方猜这个数字.比如0-100内一个数字,看谁猜中用的次数少. 这个里面用折半思想猜会大大减少次数. 步骤:(加入数字为9) 1.因为数字的范围是0-100,所以第一次 ...
- 查找与排序算法(Searching adn Sorting)
1,查找算法 常用的查找算法包括顺序查找,二分查找和哈希查找. 1.1 顺序查找(Sequential search) 顺序查找: 依次遍历列表中每一个元素,查看是否为目标元素.python实现代码如 ...
随机推荐
- swift pod第三方OC库使用use_frameworks!导致#import提示无法找到头文件
以MBProgressHUD为例子 swift中Podfile文件一般都会加上use_frameworks! 这样就可以直接通过import MBProgressHUD来访问MBProgressHUD ...
- CentOS7下配置网络yum源(附带下载地址)
一.查看外网是否通畅 配置网络yum源(需要保证外网开通,我这里是使用网易163提供开源镜像站) 二.下载repo文件 cd /etc/yum.repos.dwget http://mirrors.1 ...
- Swift 入门之简单语法(六)
KVC 字典转模型构造函数 /// `重写`构造函数 /// /// - parameter dict: 字典 /// /// - returns: Person 对象 init(dict: [Str ...
- AutoMapper总结
AutoMapper是一个对象和对象间的映射器.对象与对象的映射是通过转变一种类型的输入对象为一种不同类型的输出对象工作的.让AutoMapper有意思的地方在于它提供了一些将类型A映射到类型B这种无 ...
- 一、Openstack_Ocata环境部署准备
OpenStack Ocata环境搭建准备 1.workstation下配置3个虚拟交换机 点击编辑-->虚拟网络编辑器 名称 IP地址 作用 VMnet1 10.1.1.0 Openstack ...
- php中的数组遍历的几种方式
[(重点)数组循环遍历的四种方式] 1.使用for循环遍历数组 conut($arr);用于统计数组元素的个数. for循环只能用于遍历,纯索引数组!!!! 如果存在关联数 ...
- Qt之添加图标
导读: 在使用Qt Creator编写完应用程序后,设置release版的应用程序图标着实困扰了不少的人.一个漂亮的图标是一个软件的脸,没有一个漂亮的图标,那么这个程序是不完整的.那么我们来看看如何设 ...
- Python-快速排序
算法思想:快速排序运用了分而治之的思想,即在所选数组中选择一个基准(任选一个都可以),以改基准为基础,将小于该基准的元素都移动基准的左边,大于该基准的数据都移动到右边,然后对左右两边进行递归处理.同样 ...
- Spring Task每次都会调用两次的问题
最近一个Spring Mvc的项目中需要定时执行一个任务,所以使用了spring 自带的Task功能.本地调试的时候一切都正常,可是部署到服务器上后,每次任务都会被调用两次.在网上搜索了相关的问题,排 ...
- git代码回滚
有时候我们用git提交代码后发生了错误,代码冲突了啊等等,我们需要将代码回到以前的某个版本 git代码回退有两种办法 一.git reset(推荐): 它是将最新的commit删除,用以前的某个版本的 ...