[转载] Hadoop MapReduce
转载自http://blog.csdn.net/yfkiss/article/details/6387613和http://blog.csdn.net/yfkiss/article/details/6387461
Hadoop MapReduce是一个用于处理海量数据的分布式计算框架。这个框架解决了诸如数据分布式存储、作业调度、容错、机器间通信等复杂问题,可以使没有并行处理或者分布式计算经验的工程师,也能很轻松地写出结构简单的、应用于成百上千台机器处理大规模数据的并行分布式程序。
Hadoop MapReduce基于“分而治之”的思想,将计算任务抽象成map和reduce两个计算过程,可以简单理解为“分散运算—归并结果”的过程。一个MapReduce程序首先会把输入数据分割成不相关的若干键/值对(key1/value1)集合,这些键/值对会由多个map任务来并行地处理。MapReduce会对map的输出(一些中间键/值对key2/value2集合)按照key2进行排序,排序是用memcmp的方式对key在内存中字节数组比较后进行升序排序,并将属于同一个key2的所有value2组合在一起作为reduce任务的输入,由reduce任务计算出最终结果并输出key3/value3。作为一个优化,同一个计算节点上的key2/value2会通过combine在本地归并。基本流程如下:

Hadoop和单机程序计算流程对比:

常计算任务的输入和输出都是存放在文件里的,并且这些文件被存放在Hadoop分布式文件系统HDFS(Hadoop Distributed File System)中,系统会尽量调度计算任务到数据所在的节点上运行,而不是尽量将数据移动到计算节点上,减少大量数据在网络中传输,尽量节省带宽消耗。
应用程序开发人员一般情况下需要关心的是图中灰色的部分,单机程序需要处理数据读取和写入、数据处理;Hadoop程序需要实现map和reduce,而数据读取和写入、map和reduce之间的数据传输、容错处理等由Hadoop MapReduce和HDFS自动完成。
MapReduce是一种编程模型,始于:Dean, Jeffrey & Ghemawat, Sanjay (2004). "MapReduce: Simplified Data Processing on Large Clusters"。主要应用于大规模数据集的并行运算。其将并行计算简化为Map和reduce过程,极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。程序员只需要指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,然后指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表。其流程概念图如下:
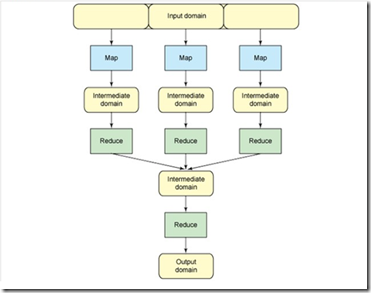
一个典型的Map-Reduce过程如下:
Input->Map->Patition->Reduce->Output
Input Phase
输入的数据需要以一定的格式传递给Mapper的,格式有多种,数据一般分布在多台机器。
Map Phase
对输入的数据进行处理,输出的是key、value的集合。
Partition Phase
把Mapper任务输出的中间结果按key的范围划分成R份(R是预先定义的Reduce任务的个数),默认的划分算法是"(key.hashCode() & Integer.MAX_VALUE) % numPartitions",这样保证了某一范围的key一定是由某个Reducer来处理。
Reduce Phase
Reducer获取Mapper输出的中间结果,作为输入对某一key范围区间进行处理。
Output Phase
Reducer的输出格式和Mapper的输入格式是相对应的,当然Reducer的输出还可以作为另一个Mapper的输入继续进行处理。
MapReduce的优点:
主要有两个方面:
1. 通过MapReduce这个分布式处理框架,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,比如,自动并行化、负载均衡和灾备管理等,这样将极大地简化程序员的开发工作;
2. MapReduce的伸缩性非常好,也就是说,每增加一台服务器,其就能将差不多的计算能力接入到集群中,而过去的大多数分布式处理框架,在伸缩性方面都与MapReduce相差甚远。而 MapReduce最大的不足则在于,其不适应实时应用的需求
[转载] Hadoop MapReduce的更多相关文章
- Hadoop MapReduce例子-新版API多表连接Join之模仿订单配货
文章为作者原创,未经许可,禁止转载. -Sun Yat-sen University 冯兴伟 一. 项目简介: 电子商务的发展以及电商平台的多样化,类似于京东和天猫这种拥有过亿用户的在线购 ...
- 使用MRUnit,Mockito和PowerMock进行Hadoop MapReduce作业的单元测试
0.preliminary 环境搭建 Setup development environment Download the latest version of MRUnit jar from Apac ...
- hadoop mapreduce 计算平均气温的代码,绝对原创
1901 46 1902 21 1903 48 1904 33 1905 43 1906 47 1907 31 1908 28 1909 26 1910 35 1911 30 1912 16 1913 ...
- 下一代Apache Hadoop MapReduce框架的架构
背景 随着集群规模和负载增加,MapReduce JobTracker在内存消耗,线程模型和扩展性/可靠性/性能方面暴露出了缺点,为此需要对它进行大整修. 需求 当我们对Hadoop MapReduc ...
- 使用hadoop mapreduce分析mongodb数据
使用hadoop mapreduce分析mongodb数据 (现在很多互联网爬虫将数据存入mongdb中,所以研究了一下,写此文档) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明 ...
- Hadoop MapReduce编程入门案例
Hadoop入门例程简介 一个.有些指令 (1)Hadoop新与旧API差异 新API倾向于使用虚拟课堂(象类),而不是接口.由于这更easy扩展. 比如,能够无需改动类的实现而在虚类中加入一个方法( ...
- hadoop MapReduce运营商案例关于用户基站停留数据统计
注 如果需要文件和代码的话可评论区留言邮箱,我给你发源代码 本文来自博客园,作者:Arway,转载请注明原文链接:https://www.cnblogs.com/cenjw/p/hadoop-mapR ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
随机推荐
- ReactiveCocoa_v2.5 源码解析之架构总览
ReactiveCocoa 是一个 iOS 中的函数式响应式编程框架,它受 Functional Reactive Programming 的启发,是 Justin Spahr-Summers 和 J ...
- 使用 Newtonsoft.Json 操作 JSON 字符串
一.把实体类转化为 JSON 字符串 1. 为实体类赋值 SenderFromMQSearch senderFromMQSearch = new SenderFromMQSearch(); sende ...
- win10 uwp 兴趣线
本文讲的是如何去做一个时间轴样子的东西但我们放的不一定是时间,可能是我们的时间.我把它放在我的CSDN阅读,我的界面做出来很差,但是应该读者能做出很漂亮的. 行间距 我们在ViewModel写一个Ob ...
- win10 uwp 活动磁贴
本文翻译:https://mobileprogrammerblog.wordpress.com/2015/12/23/live-tiles-and-notifications-in-universal ...
- LINUX 笔记-scp命令
从本地服务器复制到远程服务器: (1) 复制文件: 命令格式: scp local_file remote_username@remote_ip:remote_folder (2) 复制目录: 命令格 ...
- [mysql使用(3)] 使用mysql的时候遇到的一些错误
1.Err1055,出现这个问题往往是在执行sql语句时候,在最后一行会出现这个问题. [Err] 1055 - Expression #1 of ORDER BY clause is not in ...
- java 调用webservice接口
webservice的 发布一般都是使用WSDL(web service descriptive language)文件的样式来发布的,在WSDL文件里面,包含这个webservice暴露在外面可供使 ...
- 点击下拉,其余不动的jquery事件(转)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- tomcat默认日志路径更改
在项目访问量不断增加时,tomcat下logs也迅速增大,有时甚至因为填满了所在分区而出现无空间写入日志而导致程序出问题. 这时要更改logs的默认目录,指向更大的磁盘.修改主要有两步: 1. 修改t ...
- Longest Common Substring(最长公共子序列)
Longest Common Substring Time Limit: 8000/4000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Ot ...