sparksql的三种join实现
join 是sql语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余,更新容错等。而建立表和表之间关系的最佳方式就是Join操作。
sparksql作为大数据领域的sql实现,自然也对join操作做了不少优化,今天主要看一下在spark sql中对于join,常见的3种实现。
sparksql的3种join实现
1、Broadcast Join (小表对大表)
在数据库的常见模型中(比如星型模型或者雪花模型),表一般分为两种:事实表和维度表。
维度表一般指固定的、变动较少的表,例如联系人、物品种类等,一般数据有限。
事实表一般记录流水,比如销售清单等,通常随着时间的增长不断膨胀。
因为Join 操作是对两个表中key值相同的记录进行连接,在SparkSQL中,对两个表做join最直接的方式是先根据key分区,再在每个分区中把key值相同的记录拿出来做
连接操作。但这样就不可避免地涉及到shuffle,而shuffle在spark中比较耗时的操作,我们应该尽可能的设计Spark应用使其避免大量的shuffle。
当维度表和事实表进行join操作时,为了避免shuffle,我们可以将大小有限的维度表的全部数据分发到每个节点上,供事实表使用。executor存储维度表的全部数据,一定程度上牺牲了
空间,换取shuffle操作大量的耗时,这在SparkSQL中称作 Broadcast Join。
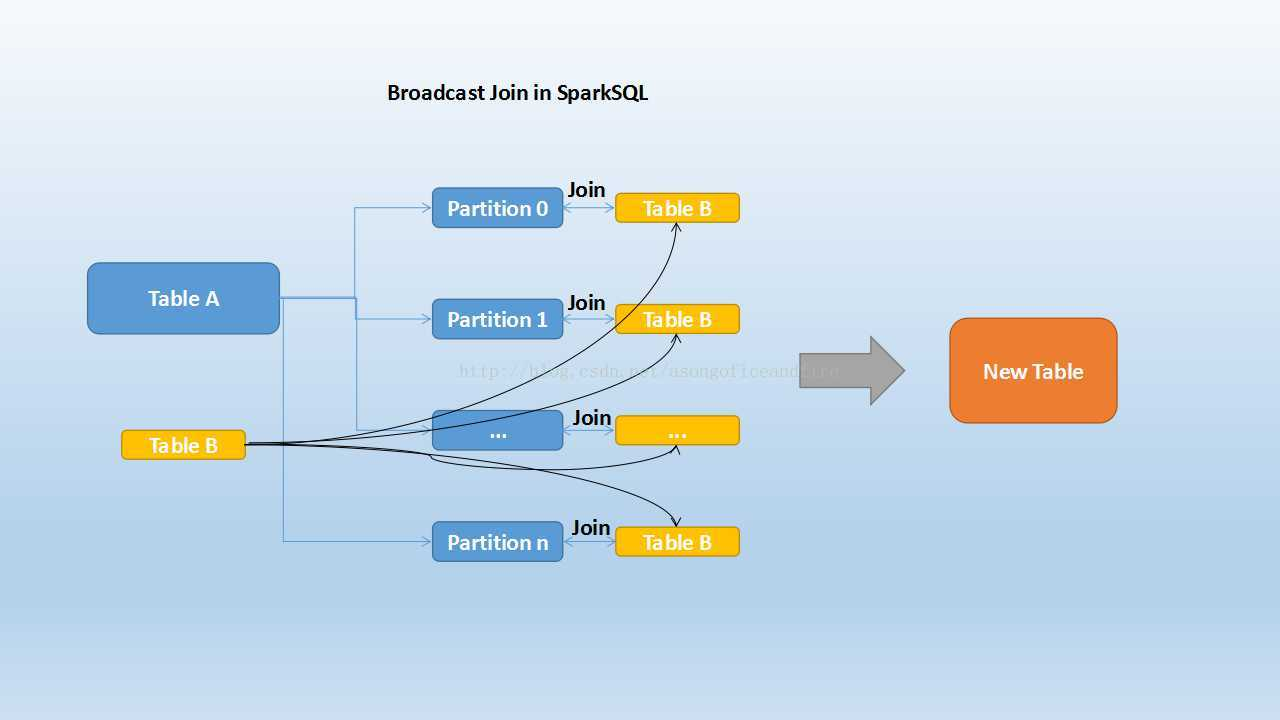
Table B 是较小的表,黑色表示将其广播到每个executor节点上,Table A 的每个partition 会通过 block manager取到Table A的数据。根据每条记录的 Join Key 取到
Table B中相对应的记录,根据 Join Type进行操作。这个过程比较简单,不做赘述。
Broadcast Join 的条件有以下几个:
(1)被广播的表需要小于 spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M(或者加了 broadcast join的 hint)
(2)基表不能被广播,比如 left outer join时,只能广播右表。
看起来广播是一个比较理想的方案,但它有没有缺点呢?也很明显。这个方案只能用于广播较小的表,否则数据的冗余传输就远大于shuffle的开销;
另外,广播时需要将被广播的表collect 到driver端,然后由driver端将数据分发到其他executor,当频繁有广播出现时,对driver的内存也是一个考验。
2、Shuffle Hash Join
当一侧的表比较小时,我们选择将其广播出去以避免shuffle,提高性能。但因为被广播的表首先被collect到driver端,然后被冗余分发到每个executor上,所以当表比较大时,
采用 broadcast join 会对driver端和executor端造成较大的压力。
但由于Spark 是一个分布式的计算引擎,可以通过分区的形式将大批量的数据划分成n份较小的数据集进行并行计算。这种思想应用到Join上便是 Shuffle Hash Join 了。
利用key相同必然分区相同的这个原理,Spark SQL将较大表的 join 分而治之,先将表划分成 n 个分区,再对两个表中相对应分区的数据分别进行 Hash Join,这样即在
一定程度上减少了driver广播一侧表的压力,也减少了executor端取整张被广播表的内存消耗。
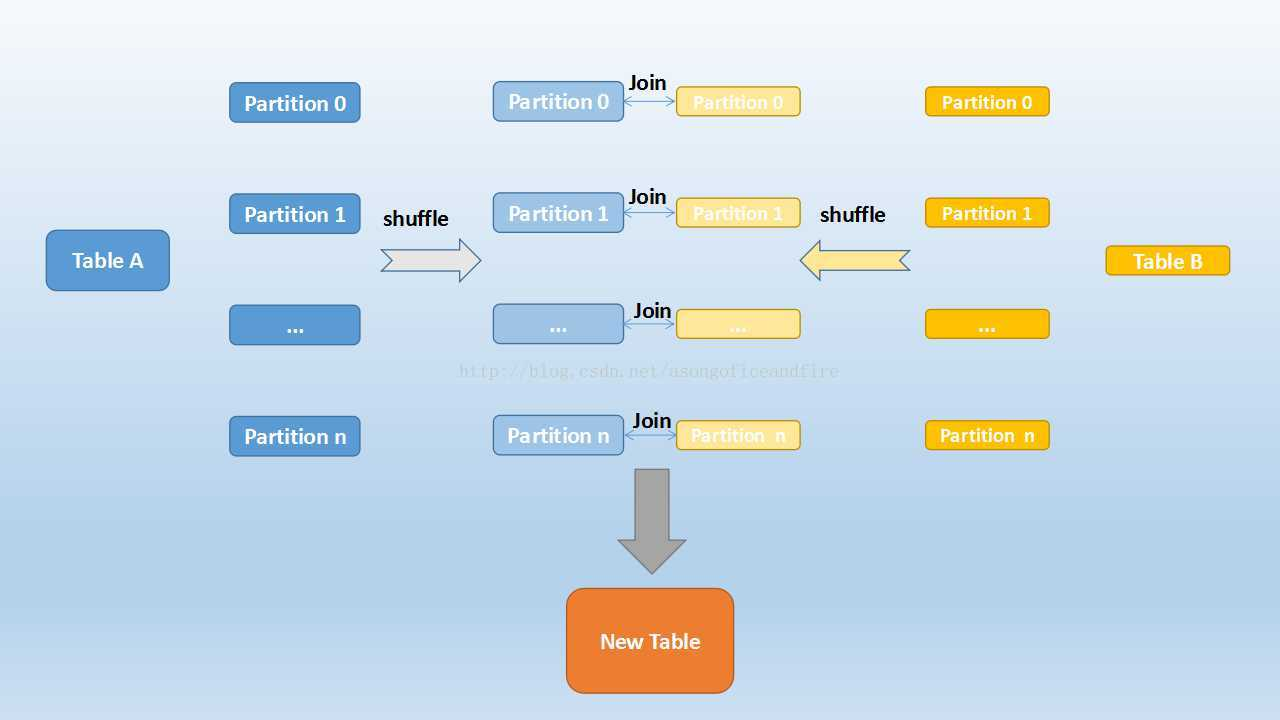
Shuffle Hash Join 分为两步:
1、对两张表分别按照 join keys进行重分区,即shuffle,目的就是为了让有相同 join keys值的记录分到对应的分区中。
2、对对应分区中的数据进行 join,此处先将小表分区构造为一张hash 表,然后根据大表分区中记录的join keys值拿出来进行匹配。
Shuffle Hash Join 的条件有以下几个:
1、分区的平均大小不超过 spark.sql.autoBroadcastJoinThreshold 所配置的值,默认是 10M。
2、基表不能被广播,比如 left outer join 时,只能广播右表。
3、一侧的表要明显小于另外一侧,小的一侧将被广播(明显小于的定义为3倍小)
我们可以看到,在一定大小的表中,SparkSQL从时空结合的角度来看,将两个表进行重新分区,并且对小表中的分区进行hash化,从而完成join。
在保持一定复杂度的基础上,尽量减少driver和executor的内存压力,提升了计算时的稳定性。
Sort Merge Join (大表对大表)
上面介绍的两种实现对于一定大小的表表适用,但当两个表都非常大时,显然无论用哪种都会对计算内存造成很大压力。这是因为join 时两者采取的都是 hash join,
是将一侧的数据完全加载到内存中,使用 hash code取 join keys值相等的记录进行连接。
当两个表都非常大时,SparkSQL 采用了一种全新的方案来对标进行 join,即 Sort Merge Join 。这种实现方式不用将一侧数据全部加载后再进行 hash join,但需要在
join 前将数据排序。

可以看到,首先将两张表按照 join keys 进行了重新shuffle,保证 join keys值相同的记录会被分在相应的分区。分区后对每个分区内的数据进行排序,排序后
再对相应的分区内的记录进行连接。
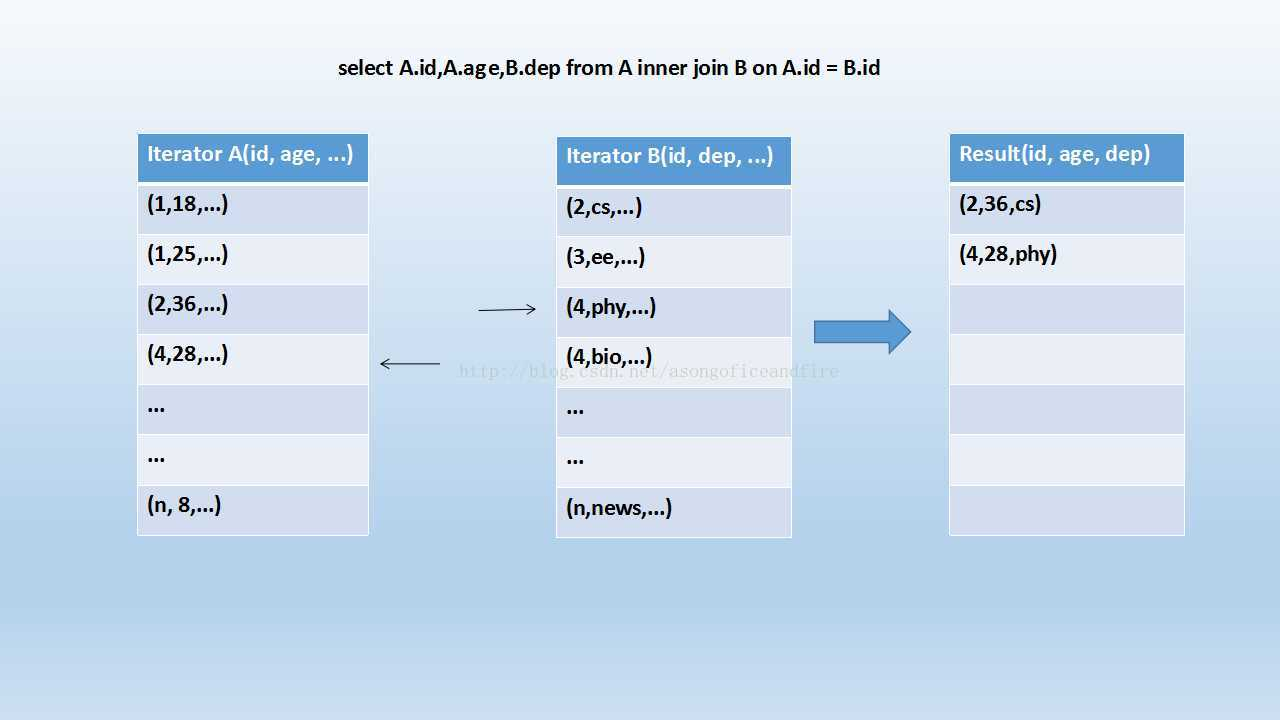
因为两个序列都是有序的,从头遍历,碰到 key 相同的就输出,如果不同,左边小就继续取左边,反之取右边。
可以看出,无论分区有多大,Sort Merge Join 都不用把某一侧的数据全部加载到内存中,而是即用即丢,从而大大提升了大数量下 sql join 的稳定性。
sparksql的三种join实现的更多相关文章
- MapReduce三种join实例分析
本文引自吴超博客 实现原理 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之间join操作最为常见的模式,其具体的实现原理如下: Map端的主要工作:为来自不同 ...
- 061 hive中的三种join与数据倾斜
一:hive中的三种join 1.map join 应用场景:小表join大表 一:设置mapjoin的方式: )如果有一张表是小表,小表将自动执行map join. 默认是true. <pro ...
- Hive的三种Join方式
Hive的三种Join方式 hive Hive中就是把Map,Reduce的Join拿过来,通过SQL来表示. 参考链接:https://cwiki.apache.org/confluence/dis ...
- SQL Server中的三种Join方式
1.测试数据准备 参考:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek 这篇博客中的实验数据准备.这两篇博客使用了相同的实验数据. 2.SQ ...
- SparkSQL的3种Join实现
引言 Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余.更新容错等.而建立表和表之间关系的最佳方式就是Join操作. 对于Spark来说有3中Jo ...
- 数据库常见的三种join方式
数据库常见的join方式有三种:inner join, left outter join, right outter join(还有一种full join,因不常用,本文不讨论).这三种连接方式都是将 ...
- 数据库(学习整理)----7--Oracle多表查询,三种join连接
聚合函数:(都会忽略null数据) 常用的有5种:将字段中所有的数据聚合在一条中 .sum(字段名) :求总和 .avg(字段名) :求平均值 .max(字段名) :求最大值 .min(字段名) :求 ...
- 三种Join方法
NESTED LOOP JOIN (NLJOIN) 对于被连接的数据子集较小的情况,nested loop连接是个较好的选择.nested loop就是扫描一个表,每读到一条记录,就根据索引去另一个 ...
- Oracle中的三种Join 方式
基本概念 Nested loop join: Outer table中的每一行与inner table中的相应记录join,类似一个嵌套的循环. Sort merge join: 将两个表排序,然后再 ...
随机推荐
- Linux服务器相关性能的命令
Linux服务器相关性能的命令 一.查看服务器性能信息的相关命令 1.cpu信息查看 cpu分为物理cpu和逻辑cpu 物理cpu:实际物理服务器插槽上cpu的个数,可以通过physical id不重 ...
- Docker的学习体验
由于兴致使然,便想学习一点Docker技术.于是,写了这篇学习Docker的体会.笔拙,见谅. 第一件事--把网线插上 相信很多人都被官网的<Sample application>的 do ...
- Lesson 11 Not guilty
Lesson 11 Not guilty guilty ['gɪlti] adj. 有罪的:内疚的 be guilty of - He is guilty of murder. be innocent ...
- MYSQL一个设备上的主从复制实现-windows
只记录一次在一个设备上实现mysql主从复制的过程,很详细,建议收藏,用到的时候照着步骤做就可以,会记录所有需要注意到的细节和一些容易遇到的坑以及解决办法! 如果需要在同一台电脑(服务器)上实现mys ...
- 流畅的python-2
一.python数据结构 ----------------> () [] {} List 列表[] 可变的 lst = [1,2,3,4] #改 lst[(元素下标 ...
- VUE-router-跳转
跳转的 // 字符串 this.$router.push('/home/first') // 对象 this.$router.push({ path: '/home/first' }) // 命名的路 ...
- fastjson 1.2.24 反序列化导致任意命令执行漏洞
漏洞检测 区分 Fastjson 和 Jackson {"name":"S","age":21} 和 {"name":& ...
- 论文笔记:(2017NIPS)DeepSets
目录 摘要 一.引言 二.置换不变性和等变性 2.1 问题定义 2.2 结构 2.3 相关结果 三.Deep Sets 3.1 架构 3.2 其他相关工作 四.应用和实验结果 4.1 设置输入标量响应 ...
- SQL根据两个日期生成年、月、日
1 DECLARE @beginTime DATETIME, @endTime DATETIME 2 SET @beginTime ='2019-03-01' 3 SET @endTime ='201 ...
- Vulhub-Mysql 身份认证绕过漏洞(CVE-2012-2122)
前言 当连接MariaDB/MySQL时,输入的密码会与期望的正确密码比较,由于不正确的处理,会导致即便是memcmp()返回一个非零值,也会使MySQL认为两个密码是相同的.也就是说只要知道用户名, ...