mysql 开发进阶篇系列 17 MySQL Server(key_buffer与table_cache)
一.key_buffer
上一篇了解key_buffer设置,key_buffer_size指定了索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度。通过检查状态值Key_read_requests和Key_reads,可以知道key_buffer_size设置是否合理。比例key_reads /key_read_requests应该尽可能的低,至少是1:100,1:1000更好(理解为key_reads物理IO次数越少越好)。
-- 一共有Key_read_requests个索引请求,一共发生了Key_reads次物理IO
SHOW GLOBAL STATUS LIKE '%key_read%';
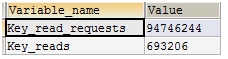
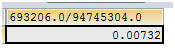
-- Key_reads/Key_read_requests ≈ 0.1%以下比较好
SELECT 693206.0/94745304.0
key_buffer_size只对MyISAM表起作用。即使你不使用MyISAM表,但是内部的临时磁盘表是MyISAM表,也要使用该值,可以使用检查状态值created_tmp_disk_tables得知详情。
SHOW GLOBAL STATUS LIKE '%created_tmp_disk_tables%';

总结建议:
对于1G内存的机器,如果不使用MyISAM表,推荐值是16M(8-64M)。
单个key_buffer的大小不能超过4G。
建议key_buffer设置为物理内存的1/4(针对MyISAM引擎),在很多情况下数据要比索引大得多。
如果机器性能优越,可以设置多个key_buffer,分别让不同的key_buffer来缓存专门的索引。
Key_reads/Key_read_requests的大小正常情况下得小于0.01。
二. table_cache (table_open_cache)
上面讲了索引缓存,这里讲表缓存 table_cache,在mysql 5.1之后叫做"table_open_cache"。这个参数表示数据库用户打开表的缓存数量(最大限制数),用于设置table高速缓存的数量。由于每个客户端连接都会至少访问一个表,因此此参数的值与max_connections有关。例如 对于200个并行运行的连接,应该让表的缓存至少有200 * N。这里N是可以执行的查询的一个连接中表的最大数量(表数量)。
表缓存机制是:当某一连接访问一个表时,MySQL会检查当前已缓存表的数量。如果该表已经在缓存中打开,则会直接访问缓存中的表已加快查询速度;如果该表未被缓存,则会将当前的表添加进缓存并进行查询。
在执行缓存操作之前,table_cache用于限制缓存表的最大数目:如果当前已经缓存的表未达到table_cache,则会将新表添加进来;若已经达到此值,MySQL将根据缓存表的最后查询时间、查询率等规则释放之前的缓存(释放机制与sqlserver一样)。
-- 表缓存限制数(默认是2000次)
SHOW VARIABLES LIKE 'table_open_cache';

-- 最大并发连接数
SHOW VARIABLES LIKE 'max_connections';

可以通过检查mysqld的状态变量open_tables和opened_tables确定table_cache参数是否过小。 open_tables表示当前打开的表缓存数,如果执行flush tables操作,则系统会关闭一些当前没有使用的表缓存,而使得些状态值减小。opened_tables表示曾经打开的表缓存数(历史的),会一直进行累加。执行flush tables值不会减少。
-- 当前打开的表缓存数
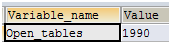
SHOW GLOBAL STATUS LIKE 'open_tables';
-- 曾经打开的表缓存数
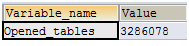
SHOW GLOBAL STATUS LIKE 'opened_tables';
2.1演示下open_tables和opened_tables值的变化(在另一台mysql上进行)
第一步:
-- 清空表缓存
FLUSH TABLES;
-- 查看值为1(代表当前连接)
SHOW GLOBAL STATUS LIKE 'open_tables';

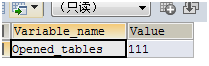
-- 历史值为111
SHOW GLOBAL STATUS LIKE 'opened_tables';
第二步:
-- 执行一个查询
SELECT COUNT(1) FROM User1
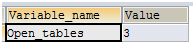
-- 再次查询当前缓存数
SHOW GLOBAL STATUS LIKE 'open_tables';
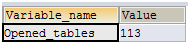
--历史值也累加到113
SHOW GLOBAL STATUS LIKE 'opened_tables';
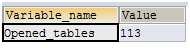
第三步:
-- 再执行一个相同查询, 会发现值没有增加,因为读的是缓存。
SELECT COUNT(1) FROM User1
SHOW GLOBAL STATUS LIKE 'open_tables';

SHOW GLOBAL STATUS LIKE 'opened_tables';
三. 修改table_cache值
下面来尝试修改table_cache值, 还是一样找到my.cnf
[root@xuegod64 etc]# vim my.cnf
[root@xuegod64 ~]# systemctl stop mysqld.service
[root@xuegod64 ~]# /bin/systemctl start mysqld.service
-- 服务停止重启后再次查看表缓存限制数。
SHOW VARIABLES LIKE 'table_open_cache';

四.table_cache总结
open_tables是当前表缓存数,类似于sql server的逻辑查询而非物理查询。 该open_tables的值对设置table_cache值有重要的参考价值。
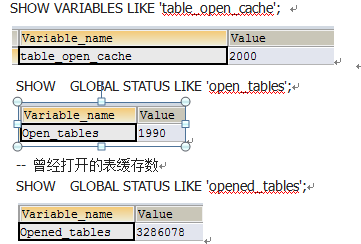
如果Open_tables的值已经接近table_cache的值,且Opened_tables还在不断变大,则说明mysql正在将缓存的表释放以容纳新的表,此时可能需要加大table_cache的值。下面这台mysql服务器正是这种情况,1990接近最大限制2000,且历史值还在不断变大。 如下图:
比较适合的值建议:
Open_tables / Opened_tables >= 0.85
当前mysql的值:SELECT 1990.0/3286078.0=0.00061
Open_tables / table_cache <= 0.95
当前mysql的值:1990.0/2000.0=0.99500
mysql 开发进阶篇系列 17 MySQL Server(key_buffer与table_cache)的更多相关文章
- mysql 开发进阶篇系列 20 MySQL Server(innodb_lock_wait_timeout,innodb_support_xa,innodb _log_*)
1. innodb_lock_wait_timeout mysql 可以自动监测行锁导致的死锁并进行相应的处理,但是对于表锁导致的死锁不能自动监测,所以该参数主要用于,出现类似情况的时候等待指定的时间 ...
- mysql 开发进阶篇系列 16 MySQL Server(myisam key_buffer)
一.概述 mysql 提供了很多参数来进行服务器的设置,当服务第一次启动的时候,所有启动参数值都是系统默认的.这些参数在很多生产环境下并不能满足实际的应用需求.在这个系列中涉及到了liunx 服务器, ...
- mysql 开发进阶篇系列 41 mysql日志之慢查询日志
一.概述 慢查询日志记录了所有的超过sql语句( 超时参数long_query_time单位 秒),获得表锁定的时间不算作执行时间.慢日志默认写入到参数datadir(数据目录)指定的路径下.默认文件 ...
- mysql 开发进阶篇系列 38 mysql日志之错误日志log-error
一.mysql日志概述 在mysql中,有4种不同的日志,分别是错误日志,二进制日志(binlog日志),查询日志,慢查询日志.这此日志记录着数据库在不同方面的踪迹(区别sql server里只有er ...
- mysql 开发进阶篇系列 19 MySQL Server(innodb_flush_log_at_trx_commit与sync_binlog)
一. innodb_flush_log_at_trx_commit 这个参数名称有个log,一看就是与日志有关.是指:用来控制缓冲区(log buffer)中的数据写入到日志文件(log file), ...
- mysql 开发进阶篇系列 18 MySQL Server(innodb_buffer_pool_size)
从这篇开始,讲innodb存储引擎中,对于几个重要的服务器参数配置.这些参数以innodb_xx 开头. 1. innodb_buffer_pool_size的设置 这个参数定义了innodb存储引擎 ...
- mysql 开发进阶篇系列 39 mysql日志之二进制日志(binlog)
一.概述 二进制日志(binlog)记录了所有的DDL(数据定义语言)语句和DML(数据操纵语言)语句,但是不包括数据查询语句, 语句以"事件"的形式保存,它描述了数据的更改过程, ...
- mysql 开发进阶篇系列 40 mysql日志之二进制日志下以及查询日志
一.binlog 二进制其它选项 在二进制日志记录了数据的变化过程,对于数据的完整性和安全性起着非常重要作用.在mysql中还提供了一些其它参数选项,来进行更小粒度的管理. 1.1 binlog-do ...
- mysql 开发进阶篇系列 47 物理备份与恢复(xtrabackup 的完全备份恢复,恢复后重启失败总结)
一. 完全备份恢复说明 xtrabackup二进制文件有一个xtrabackup --copy-back选项,它将备份复制到服务器的datadir目录下.下面是通过 --target-dir 指定完全 ...
随机推荐
- vs2015 行数统计
ctrol+shift+f 正則查找 b*[^:b#/]+.$
- Python从入门到超神之文件处理
一.文件处理流程(python默认是utf-8编码) 打开文件函数:open(文件路径,encoding=‘utf-8’)注意:open会检索系统的编码,所以需要调整一致否则报错 例如:fi=open ...
- python之支付
一,alipay方式 1,国内的alipay支付:我在网上找了好多的教程,大多数都是属于国内内支付的,所以在这里我就不详细介绍了, 操作:https://www.cnblogs.com/xuanan/ ...
- ffmpeg源码编译安装(Compile ffmpeg with source) Part 1 : 通用部分
本页内容包含了在Unix/Linux中用源码包编译的通用的结构 可能不仅仅适用于ffmpeg 为啥使用源码包编译 编译源码可以扩展功能, 实现相对于自己平台的最优化, 还可以自定义的修改 概述 大部分 ...
- RabbitMq相关
RabbitMq 通过通过IP,Port等参数创建connection对象,然后实际上通信用的是channel,channel的建立基于connection RPC 调用: RPCClient通过ch ...
- Windows与系统信息相关的DOS命令
首先,以管理员身份打开CMD命令框, 输入 start msinfo32:回车之后,出现一个弹窗,上面有大部分的系统信息:系统版本,电脑名称,BIOS,CPU,内存等: wmic bios:显示BIO ...
- (1)selenium-java环境搭建
已经学过了用python模拟浏览器操作,现在开始尝试使用java搭建环境,开头第一步就遇到了很多的问题 1.准备jdk安装,不再描述,自行百度 2.安装eclipse 3.接下来就是新建项目了,new ...
- Appium日志乱码终结指北
缘起 最近Android,IOS自动化多开群控都搞好了,但是Appium中的log 显示中文乱码问题像个苍蝇一样,看着感觉特别难受,挥之不去,抚之不平.论坛搜索了一下,很多帖子都反映过这个问题,但是都 ...
- 论文word排版相关插件
其中包括破解版的MathType.EndNote X7以及Aurora 链接:http://pan.baidu.com/s/1boRZTmf 密码:a6ai
- [转] KVM VirtIO paravirtualized drivers: why they matter
http://www.ilsistemista.net/index.php/virtualization/42-kvm-virtio-paravirtualized-drivers-why-they- ...