转载:量化投资中常用python代码分析(一)
pandas的IO
量化投资逃不过数据处理,数据处理逃不过数据的读取和存储。一般,最常用的交易数据存储格式是csv,但是csv有一个很大的缺点,就是无论如何,存储起来都是一个文本的格式,例如日期‘2018-01-01’,在csv里面是字符串格式存储,每次read_csv的时候,我们如果希望日期以datatime格式存储的时候,都要用pd.to_datetime()函数来转换一下,显得很麻烦。而且,csv文件万一一不小心被excel打开之后,说不定某些格式会被excel“善意的改变”,譬如字符串‘000006’被excel打开之后,然后万一选择了保存,那么再次读取的时候,将会自动变成数值,前面的五个0都消失了,很显然,原来的股票代码被改变了,会造成很多不方便。
此外,如果我们的pandas中的某些地方存储的不是可以被文本化的内容的时候,csv的局限性就更大了。pandas官方提供了一个很好的存储格式,hdfs。所以笔者建议,凡是pandas格式的数据,想存储下来,就用hdfs格式。
例如下面这样的一个数据:
size_data.to_hdf('filename.h5', key='data')当我们想读取的时候,只要
size_data = pd.read_hdf('filename.h5', key='data')就可以了,size_data就可以再次使用了。
面板数据的截面分析
所谓的面板数据就是截面数据加上时间序列数据。股票的数据很显然就是一个面板数据。在量化投资中,我们经常会使用截面数据处理和时间序列数据的处理。
所谓的截面数据处理,就是站在某一个交易日,或者某一个时间点,来考察全市场这么多股票的情况。而,通常,我们希望对时间序列上每一个时间节点都进行一次截面处理。
例如,我们现在有这样的一个dataframe:
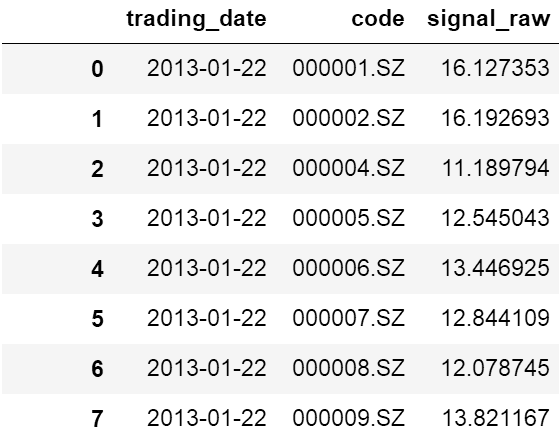
。。。。。。
显然,这个数据就是一个典型的面板数据。我们现在希望对第三列signal_raw做截面上的处理。这个时候,就可以使用groupby。
- signal.sort_values(['trading_date', 'code'], inplace=True)
- signal['siganl_win'] = signal.groupby('trading_date').apply(your_function).values
我们来分析一下上面的代码。第一行的作用是先根据trading_date排序,然后根据code排序。
代码中的your_function就是我们希望作用在截面数据上的函数。
我们来好好分析一下:
- def xf(df):
- print df
- signal.groupby('trading_date').apply(xf)
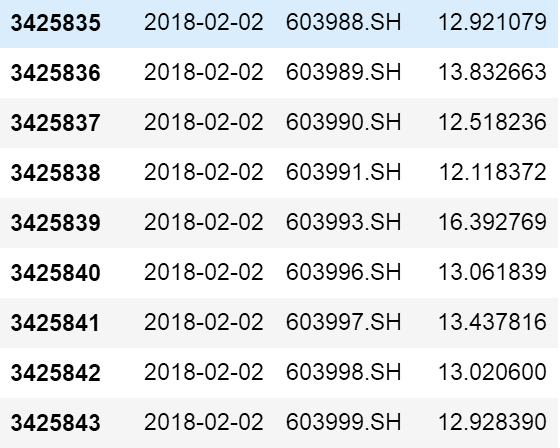
我们运行一下看看,究竟groupby之后每一个部分是什么。
很显然,groupby把dataframe按照日期分成好多小的dataframe。所以我们的处理函数只要能够返回一个等长的series,注意,我们的函数要返回一个series,要不然整个函数就不是这样写的。大家可以尝试返回一个等长的list,就会发现上面的代码不能成功运行。这样的原因是因为如果返回一个series,pandas最后整个groupby语句返回的是一个multi index 的series,index第一层是日期,第二层是返回的series的index。如果返回的是list,那么返回的是一个类似于字典结构的结果,key是日期,values是返回的list。
之所以最后要用values是将multi index去掉,只留下数值。而之所以前面要sort_values是为了顺序匹配,大家可以仔细想想。
面板数据的时间序列分析
很简单,只要sort的时候,顺序换一下,先code,后日期。然后groupby的时候按照code就可以了。
groupby apply的彩蛋
groupby后面apply的函数运行过程中,第一个被groupby拆分的子dataframe会被apply后面的函数运行两次。大家如果看仔细的话,会发现,第一个子dataframe和第二个dataframe其实是一样的。pandas官方说,之所以这样是第一个子dataframe传入的目的是为了寻找一个能够优化运行速度的方法,提高后面的运行效率。所以,如果日期只有一种,而再groupby后,返回的逻辑和有多种日期是不一样的,大家可以自行研究一下,还是很有趣的。
转载:量化投资中常用python代码分析(一)的更多相关文章
- Python代码分析工具
Python代码分析工具:PyChecker.Pylint - CSDN博客 https://blog.csdn.net/permike/article/details/51026156
- Python代码分析工具之dis模块
转自:http://hi.baidu.com/tinyweb/item/923d012e8146d00872863ec0 ,格式调整过. 代码分析不是一个新的话题,代码分析重要性的判断比较主观,不同 ...
- 60行python代码分析2018互联网大事件
2018年是改革开放四十周年,也是互联网发展的重要一年.经历了区块链,人工智能潮的互联网行业逐渐迎来了冬天.这一年里有无数的事件发生着,正好学了python数据处理相关,那么就用python对18年的 ...
- 梅尔频谱(mel-spectrogram)提取,griffin_lim声码器【python代码分析】
在语音分析,合成,转换中,第一步往往是提取语音特征参数.利用机器学习方法进行上述语音任务,常用到梅尔频谱.本文介绍从音频文件提取梅尔频谱,和从梅尔频谱变成音频波形. 从音频波形提取Mel频谱: 对音频 ...
- discuz内置常用CSS代码分析
CSS多IE下兼容HACK写法 所有 IE浏览器适用:.ie_all .foo { ... } IE6 专用:.ie6 .foo { ... } IE7 专用:.ie7 .foo { ... } IE ...
- 如何使用 Pylint 来规范 Python 代码风格
如何使用 Pylint 来规范 Python 代码风格 转载自https://www.ibm.com/developerworks/cn/linux/l-cn-pylint/ Pylint 是什么 ...
- python代码检查工具pylint 让你的python更规范
1.pylint是什么? Pylint 是一个 Python 代码分析工具,它分析 Python 代码中的错误,查找不符合代码风格标准(Pylint 默认使用的代码风格是 PEP 8,具体信息,请参阅 ...
- SonarQube-5.6.3 代码分析平台搭建使用
python代码分析 官网主页: http://docs.sonarqube.org/display/PLUG/Python+Plugin Windows下安装使用: 快速使用: 1.下载jdk ht ...
- 利用这10个工具,你可以写出更好的Python代码
我每天都使用这些实用程序来使我的Python代码可显示. 它们是免费且易于使用的. 编写漂亮的Python比看起来难. 作为发布工作流程的一部分,我使用以下工具使代码可显示并消除可避免的错误. 很多人 ...
随机推荐
- Api 文档管理系统 RAP2 环境搭建
Api 文档管理系统 RAP2 环境搭建 发表于 2018-03-27 | 分类于 Api | 评论数: 4| 阅读次数: 4704 本文字数: 4.8k | 阅读时长 ≍ 9 分钟 RA ...
- 使用 Helm 包管理工具简化 Kubernetes 应用部署
当在 Kubernetes 中已经部署很多应用时,后续需要对每个应用的 yaml 文件进行维护操作,这个过程会变的很繁琐,我们可以使用 Helm 来简化这些工作.Helm 是 Kubernetes 的 ...
- salesforce lightning零基础学习(十二) 自定义Lookup组件的实现
本篇参考:http://sfdcmonkey.com/2017/01/07/custom-lookup-lightning-component/,在参考的demo中进行了简单的改动和优化. 我们在ht ...
- SpringBoot2.0应用(五):SpringBoot2.0整合MyBatis
如何整合MyBatis 1.pom依赖 <dependency> <groupId>org.mybatis.spring.boot</groupId> <ar ...
- ES6躬行记(4)——模板字面量
模板字面量(Template Literal)是一种能够嵌入表达式的格式化字符串,有别于普通字符串,它使用反引号(`)包裹字符序列,而不是双引号或单引号.模板字面量包含特定形式的占位符(${expre ...
- Mybatis(六) Spring整合mybatis
心莫浮躁~踏踏实实走,一步一个脚印,就算不学习,玩,能干嘛呢?人生就是那样,要找点有意思,打发时间的事情来做,而钻研技术,动脑动手的过程,还是比其他工作更有意思些~ so,努力啥的都是强迫自己做自以为 ...
- IIS配置文件上传大小限制
2018-08-28 IIS配置文件上传大小限制 问题:上传文件过大导致上传不了,直接在webconfig里做以下配置会导致程序出错,这个需要在IIS里配置 <system.web> &l ...
- Maven私服 Nexus使用一例
一.背景 本次搭建Nexus的私服是为了解决两件事 1.公司网络限制,部分项目组同事无法直接访问互联网,不能直接下载一些依赖的jar文件; 2.一些独立的jar无法通过Maven添加依赖的方式引入到项 ...
- MySql常用 join 详解
虽然这类资料比较多....我觉得还是有必要记下来,新手可以看看吧...老司机可以一眼飘过那... 常用SQL JOINS方式 1.SELECT select_list FROM TABLEA A LE ...
- 提取Chrome插件为crx文件
在Chrome浏览器输入 chrome://extensions/,点开右上角开发者模式 记录上图中的ID:gidgenkbbabolejbgbpnhbimgjbffefm 在资源管理器中找到Chro ...