《从HBase offheap到Netty的内存管理》
JVM中的堆外内存(off-heap memory)与堆内内存(on-heap memory)
1. 堆内内存(on-heap memory)
1.1 什么是堆内内存
Java 虚拟机在执行Java程序的过程中会把它在主存中管理的内存部分划分成多个区域,每个区域存放不同类型的数据。下图所示为java虚拟机运行的时候,主要的内存分区:
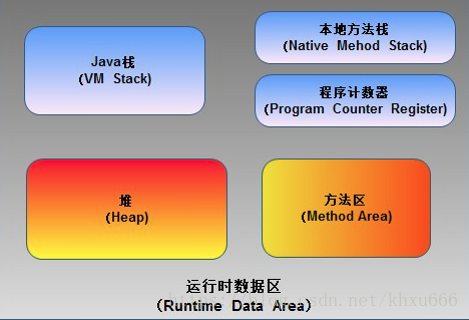
在这些分区中,占用内存空间最大的一部分叫做“堆(heap)”,也就是我们所说的堆内内存(on-heap memory)。java虚拟机中的“堆”主要是存放所有对象的实例。这一块区域在java虚拟机启动的时候被创建,被所有的线程所共享,同时也是垃圾收集器的主要工作区域,因此这一部分区域除了被叫做“堆内内存”以外,也被叫做“GC堆”(Garbage Collected Heap)。
1.2 堆内内存的垃圾回收
堆内内存是java垃圾收集器的主要工作区域,为了提高垃圾回收的效率,在堆内内存的内部又划分出了新生代、老年代和永久代。在新生代内存中又按照8:1:1的比例(java虚拟机默认分配比例为8:1:1,这个比例也可以自定义)划分出了Eden, Survivor1, Survivor2三个区域。
在执行垃圾回收算法的时候,不同的回收算法会对内存区域造成不一样的影响。但是大部分的回收算法会造成堆内内存空间在物理上的不连续性。下面以最基本的垃圾回收算法“标记 - 清除算法”为例:
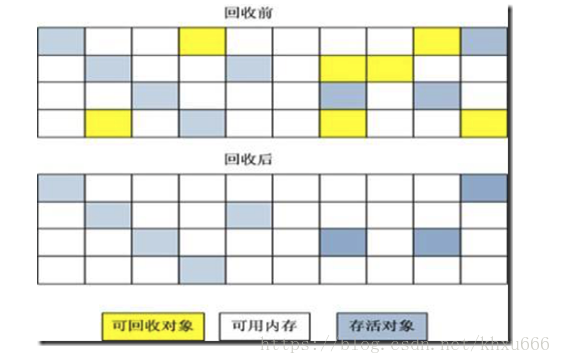
可以看到,内存区域在经过垃圾回收之后,产生大量不连续的内存空间。因此,java虚拟机中的堆内内存区域,只是逻辑上的连续,并不能保证物理上的连续性。 所以,操作系统并不能直接得到堆内内存区域所存储的数据在主存中的正确地址。在一些特定的时间点,Java虚拟机会进行一次彻底的垃圾回收(full gc)。彻底回收时,垃圾收集器会对所有分配的堆内内存进行完整的扫描,在扫描期间,绝大部分正在运行的java线程都会被暂时停止。这意味着:这样一次垃圾收集对Java应用造成的影响,跟堆内内存所存储的数据的多少是成正比的,过大的堆内内存会影响Java应用的性能。
2. 堆外内存(off-heap memory)
2.1 堆外内存的产生
为了解决堆内内存过大带来的长时间的GC停顿的问题,以及操作系统对堆内内存不可知的问题,java虚拟机开辟出了堆外内存(off-heap memory)。堆外内存意味着把一些对象的实例分配在Java虚拟机堆内内存以外的内存区域,这些内存直接受操作系统(而不是虚拟机)管理。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。同时因为这部分区域直接受操作系统的管理,别的进程和设备(例如GPU)可以直接通过操作系统对其进行访问,减少了从虚拟机中复制内存数据的过程。
2.2 堆外内存的分配
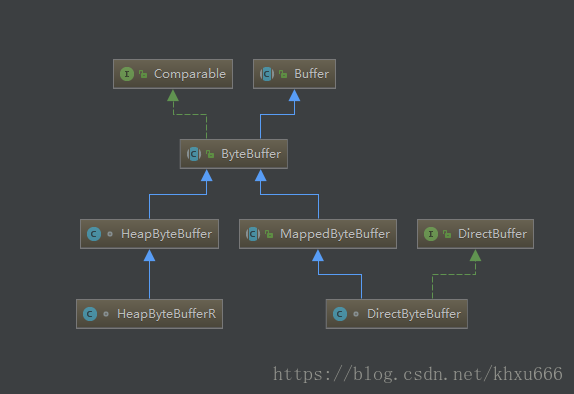
java 在NIO 包中提供了ByteBuffer类,对堆外内存进行访问。下图为NIO包中ByteBuffer的层次继承关系
使用下面的方式,可以直接开辟指定大小的对外内存:
import sun.nio.ch.DirectBuffer;
import java.nio.ByteBuffer;
public class TestDirectByteBuffer {
public static void main(String[] args) throws Exception {
while (true) {
ByteBuffer buffer = ByteBuffer.allocateDirect(10 * 1024 * 1024);
}
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这样我们就开辟出了一块大小为10M的堆外内存。
3. 堆外内存的优缺点以及与堆内内存联系
3.1堆外内存的优缺点:
优点 :
- 可以很方便的自主开辟很大的内存空间,对大内存的伸缩性很好
- 减少垃圾回收带来的系统停顿时间
- 直接受操作系统控制,可以直接被其他进程和设备访问,减少了原本从虚拟机复制的过程
- 特别适合那些分配次数少,读写操作很频繁的场景
缺点 :
- 容易出现内存泄漏,并且很难排查
- 堆外内存的数据结构不直观,当存储结构复杂的对象时,会浪费大量的时间对其进行串行化。
3.2 堆内内存与堆外内存的联系:
虽然堆外内存本身不受垃圾回收算法的管辖,但是因为其是由ByteBuffer所创造出来的,因此这个buffer自身作为一个实例化的对象,其自身的信息(例如堆外内存在主存中的起始地址等信息)必须存储在堆内内存中,具体情况如下图所示。
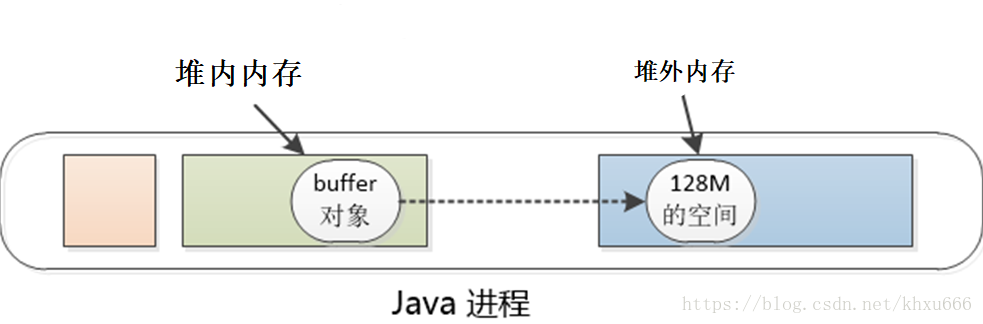
当在堆内内存中存放的buffer对象实例被垃圾回收算法回收掉的时候,这个buffer对应的堆外内存区域同时也就被释放掉了。
- TiDB Hackthon2019参赛总结 2019年10月26日
- 一场HBase2.x的写入性能优化之旅 2019年09月10日
- 推荐一本我们写的书《HBase原理与实践》 2019年09月06日
- 社区HBase未来值得做的一些工作 2019年07月15日
- HBaseConAsia2019 盛会即将来袭 2019年07月08日
- 漫谈HBase Filter 2019年07月02日
- Nebula北京Meetup总结 2019年06月29日
- Further GC optimization for HBase3.x: Reading HFileBlock into offheap directly 2019年06月23日
- 从HBase offheap到Netty的内存管理 2019年02月23日
- HBaseConWest2018演讲 - HBase Practice In XiaoMi 2018年06月18日
- 一个初中几何题 2017年11月12日
- 成为HBase Committer 2017年10月22日
- HBaseCon West 2017 Session解读 2017年06月28日
- HBase FlushCache原理实现 2017年04月12日
- 一个滴滴老司机的故事 2016年07月09日
- HBase Region Balance实践 2016年06月21日
- HBase回放Hlog顺序不一致的问题 2016年06月13日
- 徒步穿越大觉寺~凤凰岭 2016年05月21日
- 菲律宾长滩岛之旅 2016年04月26日
- TokuDB的多版本并发控制(MVCC) 2015年12月13日
- TokuDB的索引结构--分形树的实现 2015年11月25日
- MySQL Proxy认证方式实现的一种思路 2015年10月27日
- Vitess解析 2015年02月02日
- Google2015校招笔试 Round B 2014年09月16日
- 无题 2014年08月29日
- LevelDB-Compaction 2014年08月17日
- Leetcode 151总结 2014年07月20日
- Zookeeper的客户端Kazoo 2014年06月07日
- 成功 2014年05月19日
- 关于国产码农 2014年05月18日
- 从第K元素看数据结构 2014年03月02日
- 谈谈Redis字典的实现 2014年02月13日
- 平面扫描思想在ACM竞赛中的应用 2013年01月01日
- 我的公开分享 2012年01月01日
从HBase offheap到Netty的内存管理
2019年02月23日
HBase的offheap现状
HBase作为一款流行的分布式NoSQL数据库,被各个公司大量应用,其中有很多业务场景,例如信息流和广告业务,对访问的吞吐和延迟要求都非常高。HBase2.0为了尽最大可能避免Java GC对其造成的性能影响,已经对读写两条核心路径做了offheap化,也就是对象的申请都直接向JVM offheap申请,而offheap分出来的内存都是不会被JVM GC的,需要用户自己显式地释放。在写路径上,客户端发过来的请求包都会被分配到offheap的内存区域,直到数据成功写入WAL日志和Memstore,其中维护Memstore的ConcurrentSkipListSet其实也不是直接存Cell数据,而是存Cell的引用,真实的内存数据被编码在MSLAB的多个Chunk内,这样比较便于管理offheap内存。类似地,在读路径上,先尝试去读BucketCache,Cache未命中时则去HFile中读对应的Block,这其中占用内存最多的BucketCache就放在offheap上,拿到Block后编码成Cell发送给用户,整个过程基本上都不涉及heap内对象申请。
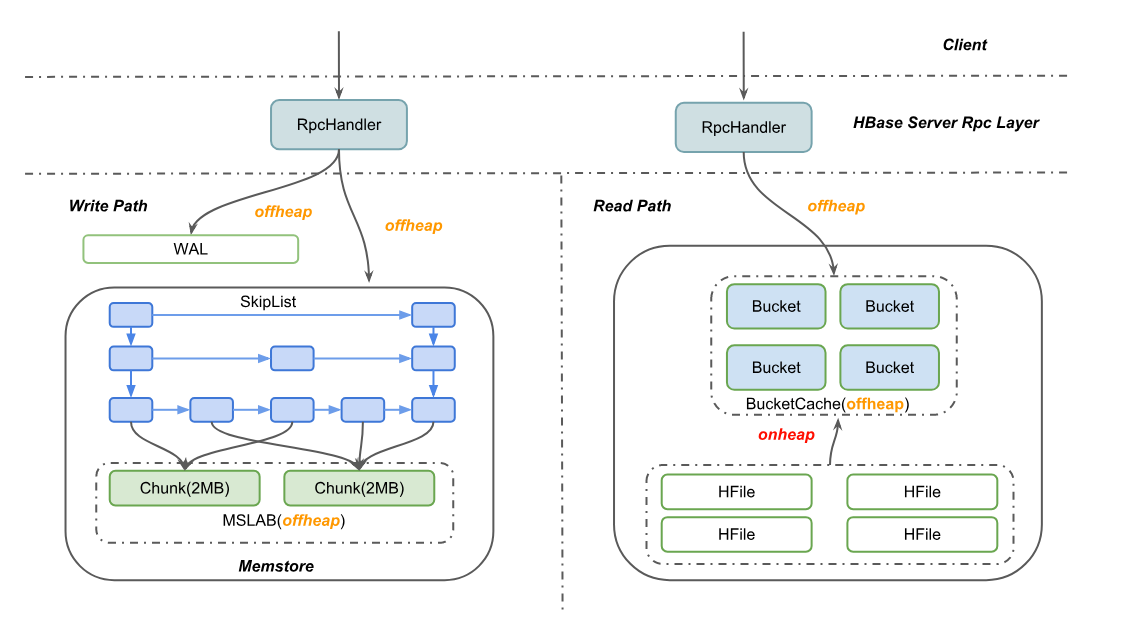
但是在小米内部最近的性能测试结果中发现,100% Get的场景受Young GC的影响仍然比较严重,在HBASE-21879贴的两幅图中,可以非常明显的观察到Get操作的p999延迟跟G1 Young GC的耗时基本相同,都在100ms左右。按理说,在HBASE-11425之后,应该是所有的内存分配都是在offheap的,heap内应该几乎没有内存申请。但是,在仔细梳理代码后,发现从HFile中读Block的过程仍然是先拷贝到堆内去的,一直到BucketCache的WriterThread异步地把Block刷新到Offheap,堆内的DataBlock才释放。而磁盘型压测试验中,由于数据量大,Cache命中率并不高(~70%),所以会有大量的Block读取走磁盘IO,于是Heap内产生大量的年轻代对象,最终导致Young区GC压力上升。
消除Young GC直接的思路就是从HFile读DataBlock的时候,直接往Offheap上读。之前留下这个坑,主要是HDFS不支持ByteBuffer的Pread接口,当然后面开了HDFS-3246在跟进这个事情。但后面发现的一个问题就是:Rpc路径上读出来的DataBlock,进了BucketCache之后其实是先放到一个叫做RamCache的临时Map中,而且Block一旦进了这个Map就可以被其他的RPC给命中,所以当前RPC退出后并不能直接就把之前读出来的DataBlock给释放了,必须考虑RamCache是否也释放了。于是,就需要一种机制来跟踪一块内存是否同时不再被所有RPC路径和RamCache引用,只有在都不引用的情况下,才能释放内存。自然而言的想到用reference Count机制来跟踪ByteBuffer,后面发现其实Netty已经较完整地实现了这个东西,于是看了一下Netty的内存管理机制。
Netty内存管理概述
Netty作为一个高性能的基础框架,为了保证GC对性能的影响降到最低,做了大量的offheap化。而offheap的内存是程序员自己申请和释放,忘记释放或者提前释放都会造成内存泄露问题,所以一个好的内存管理器很重要。首先,什么样的内存分配器,才算一个是一个“好”的内存分配器:
- 高并发且线程安全。一般一个进程共享一个全局的内存分配器,得保证多线程并发申请释放既高效又不出问题。
- 高效的申请和释放内存,这个不用多说。
- 方便跟踪分配出去内存的生命周期和定位内存泄露问题。
- 高效的内存利用率。有些内存分配器分配到一定程度,虽然还空闲大量内存碎片,但却再也没法分出一个稍微大一点的内存来。所以需要通过更精细化的管理,实现更高的内存利用率。
- 尽量保证同一个对象在物理内存上存储的连续性。例如分配器当前已经无法分配出一块完整连续的70MB内存来,有些分配器可能会通过多个内存碎片拼接出一块70MB的内存,但其实合适的算法设计,可以保证更高的连续性,从而实现更高的内存访问效率。
为了优化多线程竞争申请内存带来额外开销,Netty的PooledByteBufAllocator默认为每个处理器初始化了一个内存池,多个线程通过Hash选择某个特定的内存池。这样即使是多处理器并发处理的情况下,每个处理器基本上能使用各自独立的内存池,从而缓解竞争导致的同步等待开销。
Netty的内存管理设计的比较精细。首先,将内存划分成一个个16MB的Chunk,每个Chunk又由2048个8KB的Page组成。这里需要提一下,对每一次内存申请,都将二进制对齐,例如需要申请150B的内存,则实际待申请的内存其实是256B,而且一个Page在未进Cache前(后续会讲到Cache)都只能被一次申请占用,也就是说一个Page内申请了256B的内存后,后面的请求也将不会在这个Page中申请,而是去找其他完全空闲的Page。有人可能会疑问,那这样岂不是内存利用率超低?因为一个8KB的Page被分配了256B之后,就再也分配了。其实不是,因为后面进了Cache后,还是可以分配出31个256B的ByteBuffer的。
多个Chunk又可以组成一个ChunkList,再根据Chunk内存占用比例(Chunk使用内存/16MB * 100%)划分成不同等级的ChunkList。例如,下图中根据内存使用比例不同,分成了6个不同等级的ChunkList,其中q050内的Chunk都是占用比例在[50,100)这个区间内。随着内存的不断分配,q050内的某个Chunk占用比例可能等于100,则该Chunk被挪到q075这个ChunkList中。因为内存一直在申请和释放,上面那个Chunk可能因某些对象释放后,导致内存占用比小于75,则又会被放回到q050这个ChunkList中;当然也有可能某次分配后,内存占用比例再次到达100,则会被挪到q100内。这样设计的一个好处在于,可以尽量让申请请求落在比较空闲的Chunk上,从而提高了内存分配的效率。
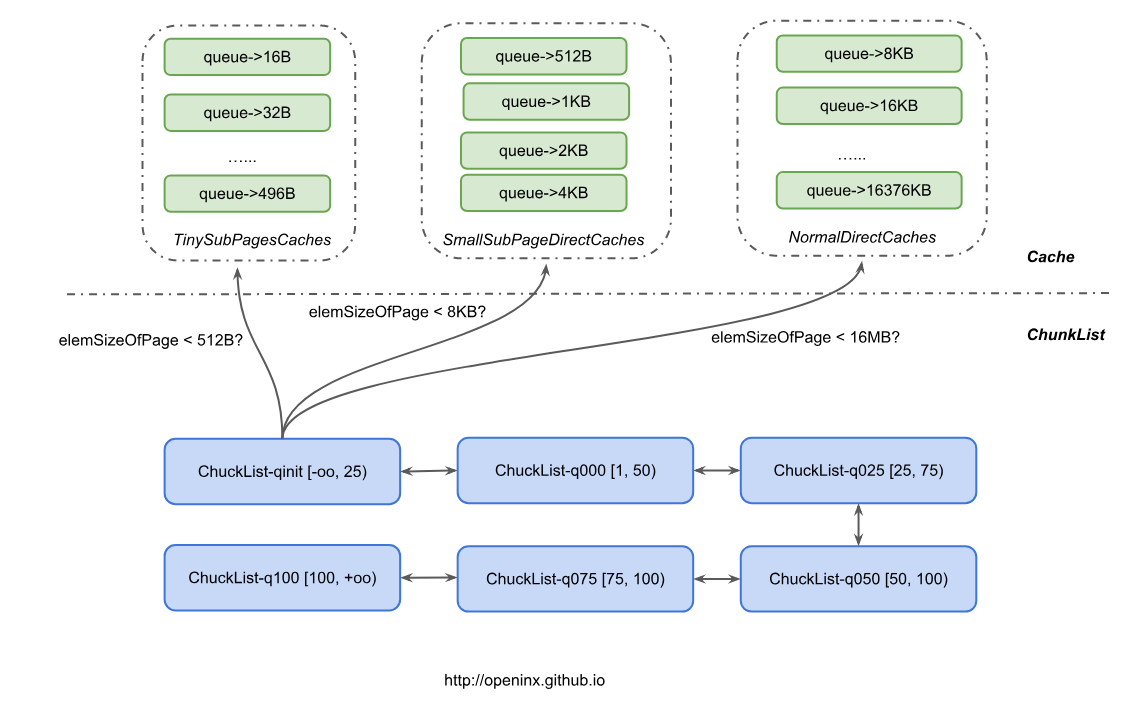
仍以上述为例,某对象A申请了150B内存,二进制对齐后实际申请了256B的内存。对象A释放后,对应申请的Page也就释放,Netty为了提高内存的使用效率,会把这些Page放到对应的Cache中,对象A申请的Page是按照256B来划分的,所以直接按上图所示,进入了一个叫做TinySubPagesCaches的缓冲池。这个缓冲池实际上是由多个队列组成,每个队列内代表Page划分的不同尺寸,例如queue->32B,表示这个队列中,缓存的都是按照32B来划分的Page,一旦有32B的申请请求,就直接去这个队列找 未占满的Page。这里,可以发现,队列中的同一个Page可以被多次申请,只是他们申请的内存大小都一样,这也就不存在之前说的内存占用率低的问题,反而占用率会比较高。
当然,Cache又按照Page内部划分量(称之为elemSizeOfPage,也就是一个Page内会划分成8KB/elemSizeOfPage个相等大小的小块)分成3个不同类型的Cache。对那些小于512B的申请请求,将尝试去TinySubPagesCaches中申请;对那些小于8KB的申请请求,将尝试去SmallSubPagesDirectCaches中申请;对那些小于16MB的申请请求,将尝试去NormalDirectCaches中申请。若对应的Cache中,不存在能用的内存,则直接去下面的6个ChunkList中找Chunk申请,当然这些Chunk有可能都被申请满了,那么只能向Offheap直接申请一个Chunk来满足需求了。
Chunk内部分配的连续性(cache coherence)
上文基本理清了Chunk之上内存申请的原理,总体来看,Netty的内存分配还是做的非常精细的,从算法上看,无论是 申请/释放效率 还是 内存利用率 都比较有保障。这里简单阐述一下Chunk内部如何分配内存。
一个问题就是:如果要在一个Chunk内申请32KB的内存,那么Chunk应该怎么分配Page才比较高效,同时用户的内存访问效率比较高?
一个简单的思路就是,把16MB的Chunk划分成2048个8KB的Page,然后用一个队列来维护这些Page。如果一个Page被用户申请,则从队列中出队;Page被用户释放,则重新入队。这样内存的分配和释放效率都非常高,都是O(1)的复杂度。但问题是,一个32KB对象会被分散在4个不连续的Page,用户的内存访问效率会受到影响。
Netty的Chunk内分配算法,则兼顾了 申请/释放效率 和 用户内存访问效率。提高用户内存访问效率的一种方式就是,无论用户申请多大的内存量,都让它落在一块连续的物理内存上,这种特性我们称之为 Cache coherence。
来看一下Netty的算法设计:
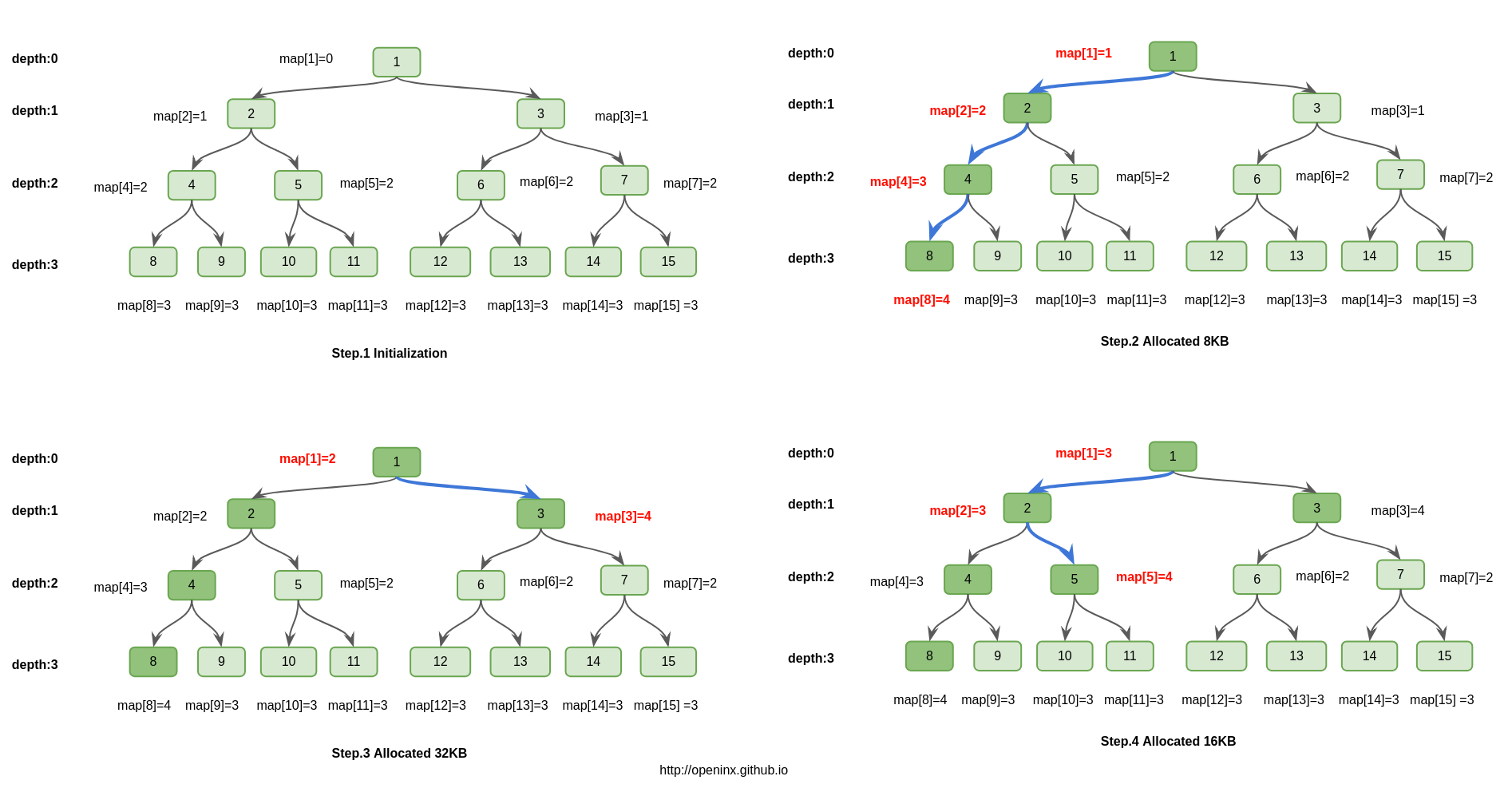
首先,16MB的Chunk分成2048个8KB的Page,这2048个Page正好可以组成一颗完全二叉树(类似堆数据结构),这颗完全二叉树可以用一个int[] map来维护。例如,map[1]就表示root,map[2]就表示root的左儿子,map[3]就表示root的右儿子,依次类推,map[2048]是第一个叶子节点,map[2049]是第二个叶子节点…,map[4095]是最后一个叶子节点。这2048个叶子节点,正好依次对应2048个Page。
这棵树的特点就是,任何一颗子树的所有Page都是在物理内存上连续的。所以,申请32KB的物理内存连续的操作,可以转变成找一颗正好有4个Page空闲的子树,这样就解决了用户内存访问效率的问题,保证了Cache Coherence特性。
但如何解决分配和释放的效率的问题呢?
思路其实不是特别难,但是Netty中用各种二进制优化之后,显的不那么容易理解。所以,我画了一副图。其本质就是,完全二叉树的每个节点id都维护一个map[id]值,这个值表示以id为根的子树上,按照层次遍历,第一个完全空闲子树对应根节点的深度。例如在step.3图中,id=2,层次遍历碰到的第一颗完全空闲子树是id=5为根的子树,它的深度为2,所以map[2]=2。
理解了map[id]这个概念之后,再看图其实就没有那么难理解了。图中画的是在一个64KB的chunk(由8个page组成,对应树最底层的8个叶子节点)上,依次分配8KB、32KB、16KB的维护流程。可以发现,无论是申请内存,还是释放内存,操作的复杂度都是log(N),N代表节点的个数。而在Netty中,N=2048,所以申请、释放内存的复杂度都可以认为是常数级别的。
通过上述算法,Netty同时保证了Chunk内部分配/申请多个Pages的高效和用户内存访问的高效。
引用计数和内存泄露检查
上文提到,HBase的ByteBuf也尝试采用引用计数来跟踪一块内存的生命周期,被引用一次则其refCount++,取消引用则refCount– ,一旦refCount=0则认为内存可以回收到内存池。思路很简单,只是需要考虑下线程安全的问题。
但事实上,即使有了引用计数,可能还是容易碰到忘记显式refCount– 的操作,Netty提供了一个叫做ResourceLeakDetector的跟踪器。在Enable状态下,任何分出去的ByteBuf都会进入这个跟踪器中,回收ByteBuf时则从跟踪器中删除。一旦发现某个时间点跟踪器内的ByteBuff总数太大,则认为存在内存泄露。开启这个功能必然会对性能有所影响,所以生产环境下都不开这个功能,只有在怀疑有内存泄露问题时开启用来定位问题用。
总结
Netty的内存管理其实做的很精细,对HBase的Offheap化设计有不少启发。目前HBase的内存分配器至少有3种:
- Rpc路径上offheap内存分配器。实现较为简单,以定长64KB为单位分配Page给对象,发现Offheap池无法分出来,则直接去Heap申请。
- Memstore的MSLAB内存分配器,核心思路跟RPC内存分配器相差不大。应该可以合二为一。
- BucketCache上的BucketAllocator。
就第1点和第2点而言,我觉得今后尝试改成用Netty的PooledByteBufAllocator应该问题不大,毕竟Netty在多核并发/内存利用率以及CacheCoherence上都做了不少优化。由于BucketCache既可以存内存,又可以存SSD磁盘,甚至HDD磁盘。所以BucketAllocator做了更高程度的抽象,维护的都是一个(offset,len)这样的二元组,Netty现有的接口并不能满足需求,所以估计暂时只能维持现状。
可以预期的是,HBase2.0性能必定是朝更好方向发展的,尤其是GC对P999的影响会越来越小。
参考资料
- https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
- https://www.facebook.com/notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919/
- https://netty.io/wiki/reference-counted-objects.html
《从HBase offheap到Netty的内存管理》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- Codeforces Round #578 (Div. 2)
Codeforces Round #578 (Div. 2) 传送门 A. Hotelier 暴力即可. Code #include <bits/stdc++.h> using names ...
- CSS3的nth-child() 选择器
CSS3的nth-child() 选择器,表格奇偶行变色 nth-child() 应用背景 CSS3的nth-child() 选择器,我之前很少用,在做表格偶数行变色的时候,我通常在绑定的时候,做一个 ...
- RabbitMQ学习笔记(三、生产者与消费者)
目录: 细说交换器 细说队列 发送消息 消费消息 确认与拒绝 细说交换器: 1.方法: public AMQP.Exchange.DeclareOk exchangeDeclare(String ex ...
- 《算法问题实战策略》 BOGGLE
oj地址是韩国网站 连接比较慢 https://algospot.com/judge/problem/read/BOGGLE大意如下 输入输出 输入 URLPM XPRET GIAET XTNZY X ...
- Gson的序列化和反序列化-待更新
反序列化为List List<Person> persons =gson.fromJson(json, new TypeToken<List<Person>>() ...
- typescript里一些有趣的点
联合类型 在原生的JS里,null和undefined经常会导致BUG的产生, 在ts里,你又想用null,又担心出错的时候 你可以考虑用联合类型,当某值可能为 number或null,你可以声明它的 ...
- Ubuntu 16.04 安装 mujoco, mujoco_py 和 gym
Mujoco (1)官网(https://www.roboti.us/license.html)注册 license,教育邮箱注册可以免费使用一年.注意:一个邮箱账号只能供一台主机使用. 填写个人信息 ...
- 现象:SpringApplication.run后面的语句未执行
下面的两种情况下,红色的log.info中的内容一直没有执行,和预期不符. 看来,需要在@PostConstruct修饰的函数.CommandLineRunner的run方法中调用 另外的线程 来执行 ...
- C语言程序设计100例之(12):Eratosthenes筛法求质数
例12 Eratosthenes筛法求质数 问题描述 Eratosthenes筛法的基本思想是:把某范围内的自然数从小到大依次排列好.宣布1不是质数,把它去掉:然后从余下的数中取出最小的数,宣布它 ...
- kafka 重放 重播 从某个时间点或者offset开始消费
转自: https://www.jianshu.com/p/932663e9a226 consumer.subscribe(topicA); consumer.poll(100);//正常订阅topi ...