Hive入门(三)分桶
1 什么是分桶
上一篇说到了分区,分区中的数据可以被进一步拆分成桶,bucket。不同于分区对列直接进行拆分,桶往往使用列的哈希值进行数据采样。在分区数量过于庞大以至于可能导致文件系统崩溃时,建议使用桶。
hive使用对分桶所用的值进行hash,并用hash结果除以桶的个数做取余运算的方式来分桶,保证了每个桶中都有数据,但每个桶中的数据条数不一定相等。
2 如何分桶
首先,在建立桶之前,需要设置hive.enforce.bucketing属性为true,使得hive能识别桶。
然后,创建带有桶的表:
CREATE TABLE bucketed_user(
id INT,
name String
)
CLUSTERED BY (id) INTO 5 BUCKETS;
向桶中插入数据,这里按照用户id分成了5个桶
此时查看文件系统中的目录结构如下:
/usr/hive/warehouse/bucketed_user/000000_0
/usr/hive/warehouse/bucketed_user/000001_0
/usr/hive/warehouse/bucketed_user/000002_0
/usr/hive/warehouse/bucketed_user/000003_0
/usr/hive/warehouse/bucketed_user/000004_0
5个桶就是将数据表存储分为5个文件存储
注:cluster by不会影响数据的导入,这意味着,用户必须自己负责数据如何导入,包括数据的分桶和排序。
3 分区与分桶比较
- 桶的数量是固定的;
- 分区可以再分子区,桶不行;
- 分区或表组织成桶,Hive在处理有些查询时能利用桶的结构,获得更高的查询处理效率
- 分桶使取样(sampling)更高效
- 物理存储方式不同
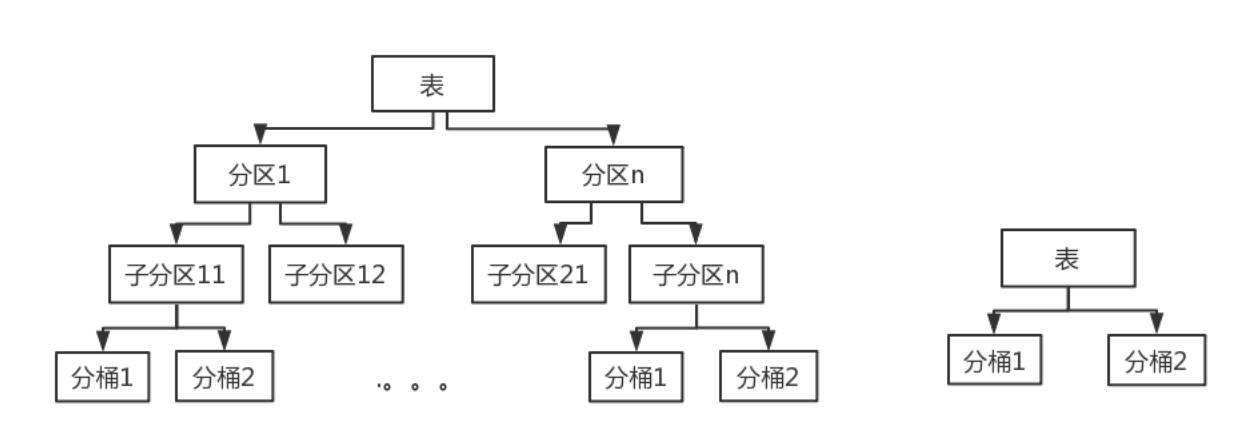
如下图,分区又分桶和只分桶的图:
注:
抽样语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
Hive入门(三)分桶的更多相关文章
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- Hive 学习之路(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中.如 ...
- Hive 系列(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- hive -- 分区,分桶(创建,修改,删除)
hive -- 分区,分桶(创建,修改,删除) 分区: 静态创建分区: 1. 数据: john doe 10000.0 mary smith 8000.0 todd jones 7000.0 boss ...
- Hive为什么要分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- hive 分区表和分桶表
1.创建分区表 hive> create table weather_list(year int,data int) partitioned by (createtime string,area ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive分区表与分桶
分区表 在Hive Select查询中.通常会扫描整个表内容,会消耗非常多时间做不是必需的工作. 分区表指的是在创建表时,指定partition的分区空间. 分区语法 create table tab ...
- hive中的分桶表
桶表也是一种用于优化查询而设计的表类型.创建通表时,指定桶的个数.分桶的依据字段,hive就可以自动将数据分桶存储.查询时只需要遍历一个桶里的数据,或者遍历部分桶,这样就提高了查询效率 ------创 ...
- 第2节 hive基本操作:11、hive当中的分桶表以及修改表删除表数据加载数据导出等
分桶表 将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去 开启hive的桶表功能 set hive.enforce.bucketing= ...
随机推荐
- abp框架(aspnetboilerplate)扩展系统表
以OrganizationUnit为例,进行扩展,加入IsUse属性 1.创建一个新类,比如ExtendedOrganizationUnit,继承OrganizationUnit public cla ...
- ef core code first from exist db
目标 为现有数据库生成新的连接,允许只选择部分表 可以处理一些很怪的需求,比如EF升级EF Core(这个可能有其他解),EF.EF Core同时连接一个数据库 我遇到的问题是: 原项目是.net f ...
- Bootstrap 单按钮下拉菜单
@{ Layout = null;}<!DOCTYPE html><html><head> <meta name="viewport&q ...
- WPF事件(一)内置路由事件
原文:WPF事件(一)内置路由事件 Windows是消息驱动的操作系统,运行其上的程序也遵照这个机制运行,随着面向对象开发平台日趋成熟,微软把消息机制封装成了更容易让人理解的事件模型,一个事件包含3个 ...
- makedownpad安装解锁
http://blog.csdn.net/na_beginning/article/details/53414102
- 【Git】整合分支那些事儿
对于scm这个岗位来说,基线升级应该是这个岗位需要的必备技能了,现在来说说我司进行高通代码基线升级时选择的方式方法,供大家参考,也供自己学习积累. git这个工具大家都并不陌生,但是对于不经常提交代码 ...
- Win10《芒果TV》商店版更新v3.2.3:新增应用内意见反馈、播放重试、透明磁贴
在2016圣诞节临近之际,<芒果TV>UWP版迅速更新v3.2.3版,主要是新增应用内意见反馈提交功能.播放重试.透明磁贴.动态磁贴等功能,进一步优化稳定性.视觉细节.运行速度. 芒果TV ...
- 关于Tiff图片的编解码
TiffBitmapEncoder 类 (System.Windows.Media.Imaging)https://msdn.microsoft.com/zh-cn/library/ms635161( ...
- 领域驱动设计(DDD)的实践经验分享之持久化透明
原文:领域驱动设计(DDD)的实践经验分享之持久化透明 前一篇文章中,我谈到了领域驱动设计中,关于ORM工具该如何使用的问题.谈了很多我心里的想法,大家也对我的观点做了一些回复,或多或少让我深深感觉到 ...
- Elevated privileges for Delphi applications
BY CRAIG CHAPMAN · PUBLISHED 2015-06-08 · UPDATED 2015-06-08 One of my customers recently asked th ...