变量、数据类型、python内存管理
pycharm快捷键
ctrl + c 复制, 默认复制整行
ctrl + v 粘贴
ctrl + x 剪切
ctrl + a 全选
ctrl + z 撤销
ctrl + f 查找
ctrl + shift + z 反撤销
ctrl + d 复制粘贴选中内容,没有选中默认整行
ctrl + y 删除整行
ctrl + backspace 删除一个单词
ctrl + w 选中一个单词
ctrl + shift + r 全局搜索
shift + F10 运行上一个文件
ctrl + shift + F10 运行当前文件
shift + enter 进入下一行
ctrl + / 整体注释
ctrl + alt + l 格式化代码
home 回到行首
end 回到行尾
变量
什么是变量
变量: 定义世间万物变化的状态
IPO
I --> input --> 输入(变量)
P --> Process --> 处理
O --> Output --> 输出
变量的组成
- 变量名:具有描述意义; 接受变量值
- 赋值符号:赋值,把变量值传给变量名
- 变量值:具体的值
变量名的规范
- 变量名必须要有意义
- 变量名由数字、字母、下划线组成,不能以数字开头
- 不能以关键字命名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec','finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass','print', 'raise', 'return', 'try', 'while', 'with', 'yield']
定义变量名的两种方式
下划线(python推荐使用)
neo_of_name = 'neo'
驼峰体
NeoOfName = 'neo'
常量
常量是指不变化的量(变量名大写)
这个不变是约定俗成的
AGE = 19
AGE = AGE + 1 # 这样做就很沙雕了
python内存管理
变量存哪了
当我们在test.py文件里定义一个变量x = 10,单纯这样写只是几个字符而已,只有当python解释器运行时,才有变量这个意义。这个变量的概念是python解释器提供的。
变量在计算机内存里开辟一个小空间,小空间内存放变量值10,然后内存给这个小空间一个变量名x,x指向10。
python垃圾回收机制
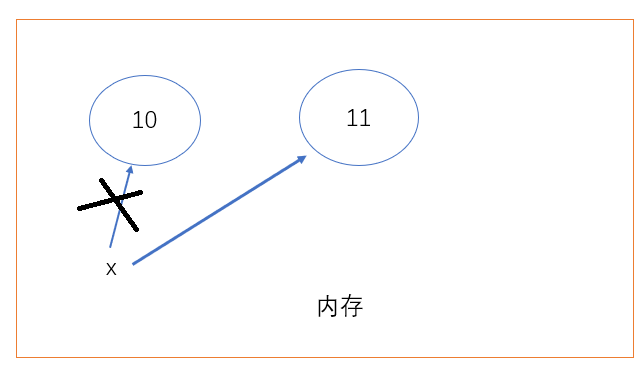
x = 10
x = 11
变量在内存开辟一个小空间,小空间内存放变量值10,变量名x指向10。加上一段代码x = 11,内存会重新开辟一个空间存放11,然后x会指向11,之前x指向10的连接会断掉。这样10就成了垃圾,python会自动处理这个垃圾,释放10的内存。
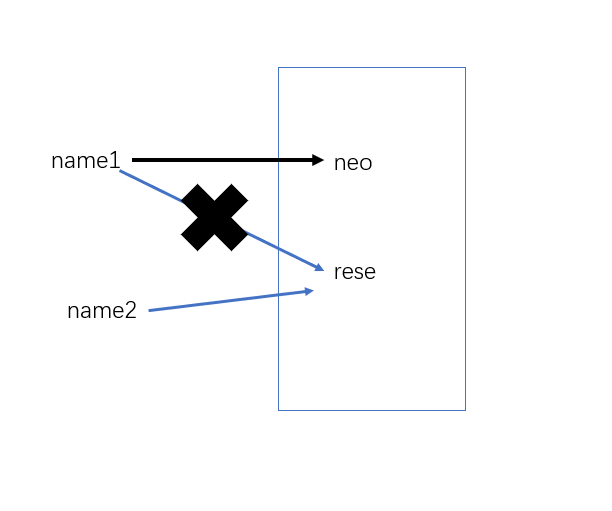
name1 = 'rese'
name2 = name1
name1 = 'neo'
引用计数
引用计数针对的是变量值, 变量值的引用次数
x = 1000 # 1000的引用次数为1
y = 1000 # 1000的引用次数为2
del x # del删除x,1000的引用次数为1
当一个变量值的引用计数为0时,会触发垃圾回收机制,之前的值会被回收
小整数池
>>> x = 10
>>> id(10)
140704061711472
>>> y = x
>>> id(y)
140704061711472
>>> z = 10
>>> id(z)
140704061711472 # 内存地址
>>> x = 1000
>>> id(x)
1619602196368 #
>>> x = 1000
>>> id(x)
1619602196496 # 这里内存地址与之前的不同
python实现int的时候有个小整数池,这是为了避免因创建相同的值而申请重复的内存空间带来的效率问题。
python解释器会自动定义[-5, 256]之间的 整数池,这是在内存中写死的。这个范围内的整数被全局调用时,永远不会触发垃圾回收机制。
在pycharm中,这个整数范围是扩大的,它优化了。
变量的三种打印形式
age = 20
# 打印值
print(age)
# 打印内存地址
print(id(age))
# 打印数据类型
print(type(age))
数据类型
什么是数据类型
数据类型对变量值做了分类,分成了不同类别
数字类型
整型
作用:描述年龄/id号
定义方式:
age = 21
age = int(21)
使用方法:
x = 2
y = 1
print(x + y) # 加
print(x - y) # 减
print(x * y) # 乘
print(x / y) # 除
print(x % y) # 取余
print(x // y) # 取整
print(x ** y) # 幂运算
当你需要使用如sin/cos/tan等函数时,怎么办呢?别担心,有方法
使用cmath模块
import cmath
print(cmath.sin(10))
浮点型
作用:描述薪资
定义方式:
salary = 3.2
salary = float(3) # 3.0
使用方法:与int整型类似
逻辑比较
>>> x = 1
>>> y = 2
>>> print(x > y)
False
>>> print(x >= y)
False
>>> print(x < y)
True
>>> print(x <= 1)
True
>>> print(x != y)
True
>>> print(x == y)
False
字符串
作用:描述姓名/性别
定义方式:
name = 'cwz'
name = "cwz's name"
使用方法:
str1 = 'neo'
str2 = 'zen'
print(str1 + ' ' + str2)
# 打印结果:neo zen
print(str2 * 10)
# 打印结果:zenzenzenzenzenzenzenzenzenzen
注释
单行注释
# 打印12
# print(12)
- 解释代码什么意思
- 让后面的代码失效
多行注释
用三引号
'''
写什么东西呢
'''
相当于定义了一个变量不使用
变量、数据类型、python内存管理的更多相关文章
- 【python测试开发栈】—python内存管理机制(二)—垃圾回收
在上一篇文章中(python 内存管理机制-引用计数)中,我们介绍了python内存管理机制中的引用计数,python正是通过它来有效的管理内存.今天来介绍python的垃圾回收,其主要策略是引用计数 ...
- python内存管理&垃圾回收
python内存管理&垃圾回收 引用计数器 环装双向列表refchain 在python程序中创建的任何对象都会放在refchain连表中 name = '张三' age = 18 hobby ...
- 转发:[Python]内存管理
本文为转发,原地址为:http://chenrudan.github.io/blog/2016/04/23/pythonmemorycontrol.html 本文主要为了解释清楚python的内存管理 ...
- Python内存管理机制及优化简析(转载)
from:http://kkpattern.github.io/2015/06/20/python-memory-optimization-zh.html 准备工作 为了方便解释Python的内存管理 ...
- 【python测试开发栈】python内存管理机制(一)—引用计数
什么是内存 在开始进入正题之前,我们先来回忆下,计算机基础原理的知识,为什么需要内存.我们都知道计算机的CPU相当于人类的大脑,其运算速度非常的快,而我们平时写的数据,比如:文档.代码等都是存储在磁盘 ...
- python内存管理(通俗易懂,详细可靠)
python内存管理 python3.6.9 内存管理的官方文档 https://docs.python.org/zh-cn/3.6/c-api/memory.html 一.变量存哪了? x = 10 ...
- python内存管理总结
之前在学习与工作中或多或少都遇到关于python内存管理的问题,现在将其梳理一下. python内存管理机制 第0层 操作系统提供的内存管理接口 c实现 第1层 基于第0层操作系统内存管理接口包装而成 ...
- Python 内存管理与垃圾回收
Python 内存管理与垃圾回收 参考文献:https://pythonav.com/wiki/detail/6/88/ 引用计数器为主标记清除和分代回收为辅 + 缓存机制 1.1 大管家refcha ...
- 解读Python内存管理机制
转自:http://developer.51cto.com/art/201007/213585.htm 内存管理,对于Python这样的动态语言,是至关重要的一部分,它在很大程度上甚至决定了Pytho ...
随机推荐
- Linux—服务器SSL/TLS快速检测工具(TLSSLed)
一.下载TLSSLed [root@localhost ~]# yum install tlssled 二.服务器SSL/TLS快速检测工具TLSSLed 现在SSL和TLS被广泛应用服务器的数据加密 ...
- ckeditor4.7配置图片上传
ckeditor作为老牌的优秀在线编辑器,一直受到开发者的青睐. 这里我们讲解下 ckeditor最新版本4.7的图片上传配置. https://ckeditor.com/ 官方 进入下载 https ...
- viscode 使用 格式的配置
viscode 现在也越来越适用于 python 开发使用的 IDEA ,慢慢不逊色于 pycharm .下面是关于使用的 格式[字体颜色,背景之类的配置] 1. 2. 如果是设置的 中文显示,在界 ...
- jQuery中的筛选(六)
1. eq(index|-index) 获取当前链式操作中第N个jQuery对象,返回jQuery对象,当参数大于等于0时为正向选取,比如0代表第一个,1代表第二个.当参数为负数时为反向选取,比如-1 ...
- Haproxy+Keepalived构建高可用负载均衡集群
实验环境: 主机名 IP地址 VIP 192.168.200.254 Haproxy-1 192.168.200.101 Haproxy-2 192.168.200.102 Nginx1 192.16 ...
- 第三方系统平台如何对接gooflow2.0
第一步,参与者数据源配置 目前提供3种参与者数据源(员工,角色,部门),还有一种sql语句 XML配置如下 <?xml version="1.0" encoding=&quo ...
- 实验1c语言的开发环境使用和数据类型,运算符,表达式
#include<stdio.h> int main() { printf("); ; } /*求两个整数的乘积*/ #include<stdio.h> int pr ...
- [转]numpy的getA()/getA1()/getH()/getI()函数
转自https://blog.csdn.net/weixin_42906066/article/details/82625779 1.mat.getA() 将自身矩阵变量转化为ndarray类型的变量 ...
- 手把手教你使用gogs搭建git私有仓库
本来想在 Github 上建一个私仓,但是发现只能设置 3 个贡献者. 国内的码云也只能设置 5 个. 无意间看到了使用 gogs 可以搭建私服,正好手头有空闲的服务器,于是开干! https://g ...
- iOS Workflow 分享 - Debug Action
有时候我们想要知道别人的 app 在调用 Share Extension 时提供了什么类型的数据以及具体数据是什么,我们可以自己在 Xcode 里面写个 app 去接收别人 app 的数据,但我们也可 ...