scrapy爬虫案例:问政平台
问政平台
http://wz.sun0769.com/index.php/question/questionType?type=4
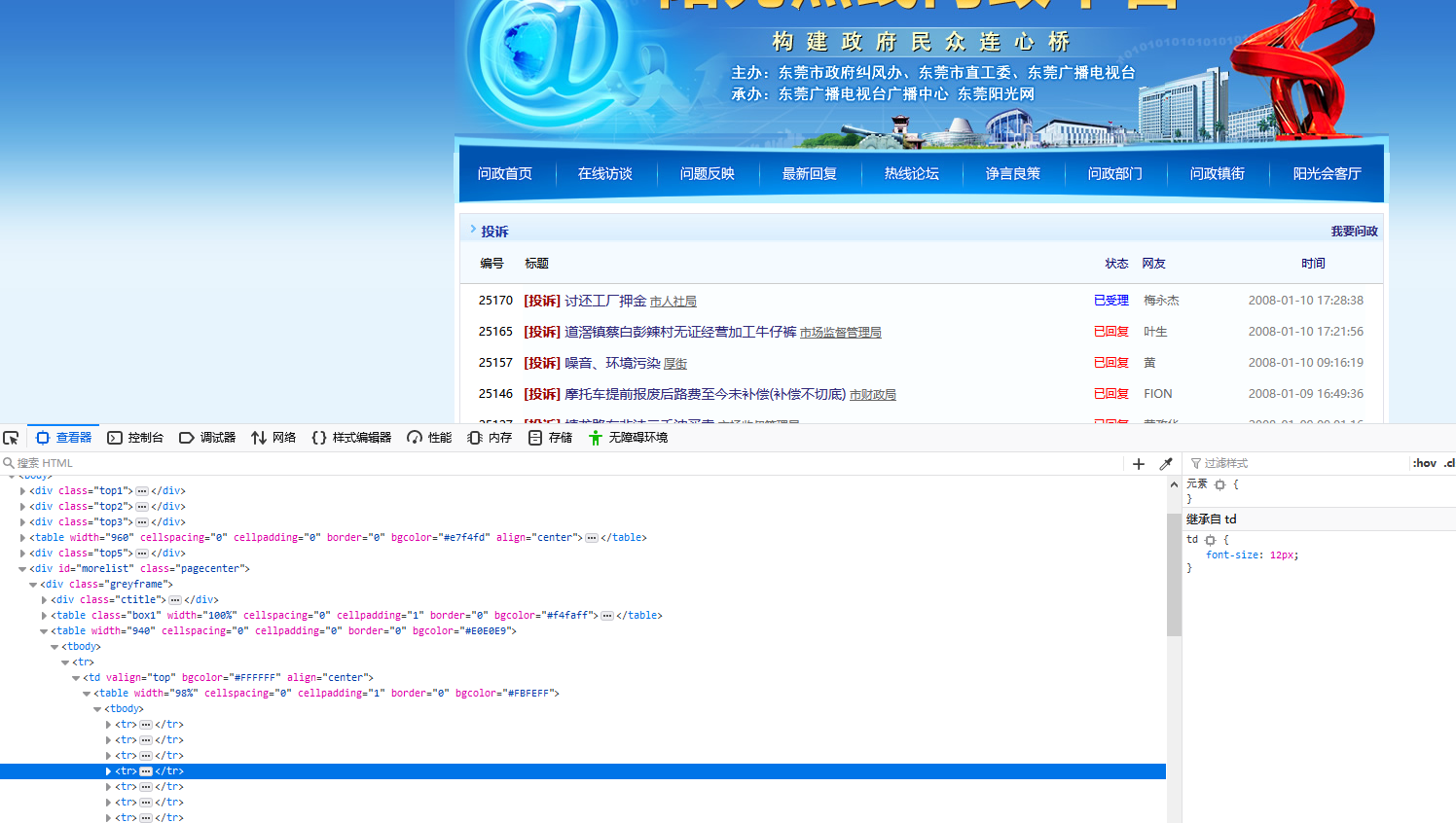
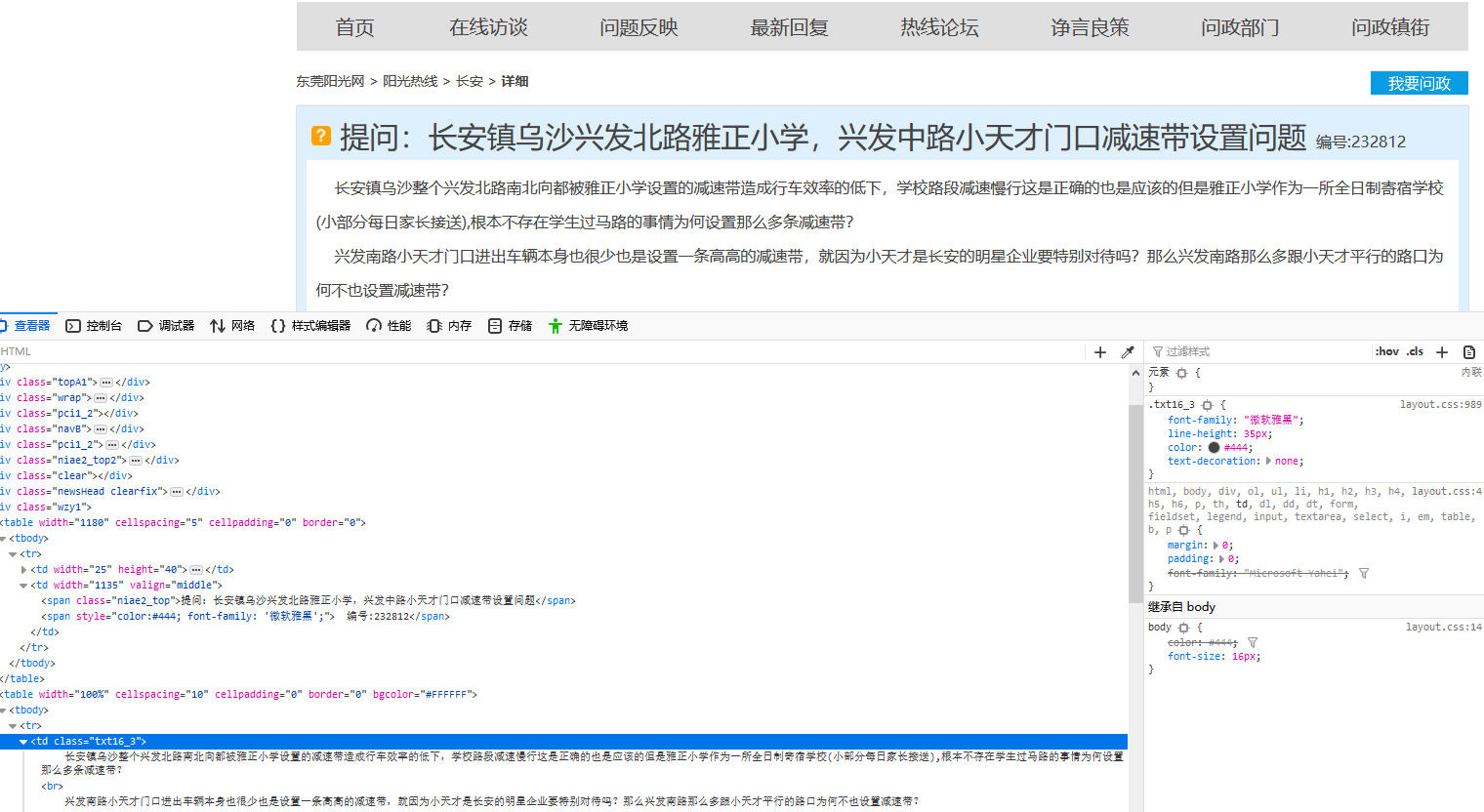
爬取投诉帖子的编号、帖子的url、帖子的标题,和帖子里的内容。
items.py
import scrapy class DongguanItem(scrapy.Item):
# 每个帖子的标题
title = scrapy.Field()
# 每个帖子的编号
number = scrapy.Field()
# 每个帖子的文字内容
content = scrapy.Field()
# 每个帖子的url
url = scrapy.Field()
spiders/sunwz.py
# -*- coding: utf-8 -*- import scrapy
from scrapy.spiders import CrawlSpider from scrapyDemo.items import DongguanItem class SunSpider(CrawlSpider):
name = 'sun'
allowed_domains = ['wz.sun0769.com']
url = 'http://wz.sun0769.com/index.php/question/questionType?type=4&page='
offset = 0
start_urls = [url + str(offset)] def parse(self, response):
# 取出每个页面里帖子链接列表
links = response.xpath("//div[@class='greyframe']/table//td/a[@class='news14']/@href").extract()
# 迭代发送每个帖子的请求,调用parse_item方法处理
for link in links:
yield scrapy.Request(link, callback=self.parse_item)
# 设置页码终止条件,并且每次发送新的页面请求调用parse方法处理
if self.offset <= 3876:
self.offset += 30
yield scrapy.Request(self.url + str(self.offset), callback=self.parse) # 处理每个帖子里
def parse_item(self, response):
item = DongguanItem()
# 标题
item['title'] = response.xpath('//span[contains(@class, "niae2_top")]/text()').extract()[0]
# 编号
item['number'] = response.xpath('//div[contains(@class, "wzy1")]//td//span/text()').extract()[1]
# 文字内容,默认先取出有图片情况下的文字内容列表
content = response.xpath('//td[@class="txt16_3"]/text()').extract()
# 如果没有内容,则取出没有图片情况下的文字内容列表
if len(content) == 0:
content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()
# content为列表,通过join方法拼接为字符串,并去除首尾空格
item['content'] = "".join(content).strip()
else:
item['content'] = "".join(content).strip() # 链接
item['url'] = response.url
yield item
pipelines.py
# -*- coding: utf-8 -*- # 文件处理类库,可以指定编码格式
import codecs
import json class DongguanPipeline(object): def __init__(self):
# 创建一个只写文件,指定文本编码格式为utf-8
self.filename = codecs.open('sunwz.json', 'w', encoding='utf-8') def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.filename.write(content)
return item def spider_closed(self, spider):
self.file.close()
settings.py
ITEM_PIPELINES = {
'dongguan.pipelines.DongguanPipeline': 300,
}
# 日志文件名和处理等级
LOG_FILE = "dg.log"
LOG_LEVEL = "DEBUG"
在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl sunwz'.split())
执行程序
py2 main.py
效果:

scrapy爬虫案例:问政平台的更多相关文章
- scrapy爬虫案例--爬取阳关热线问政平台
阳光热线问政平台:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1 爬取最新问政帖子的编号.投诉标题.投诉内容以 ...
- Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表 然后编写各个模块 item.py import scrapy class JianliItem(scrapy.Item): name = scrapy.Field() ...
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- scrapy爬虫案例:用MongoDB保存数据
用Pymongo保存数据 爬取豆瓣电影top250movie.douban.com/top250的电影数据,并保存在MongoDB中. items.py class DoubanspiderItem( ...
- 爬虫——Scrapy框架案例二:阳光问政平台
阳光热线问政平台 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖子的编号.投诉类 ...
- Scrapy项目_阳光热线问政平台
目的: 爬取阳光热线问政平台问题中每个帖子的标题.详情URL.详情内容.图片以及发布时间 步骤: 1.创建爬虫项目 1 scrapy startproject yangguang 2 cd yangg ...
- 如何让你的scrapy爬虫不再被ban之二(利用第三方平台crawlera做scrapy爬虫防屏蔽)
我们在做scrapy爬虫的时候,爬虫经常被ban是常态.然而前面的文章如何让你的scrapy爬虫不再被ban,介绍了scrapy爬虫防屏蔽的各种策略组合.前面采用的是禁用cookies.动态设置use ...
- 爬虫框架Scrapy之案例一
阳光热线问政平台 http://wz.sun0769.com/index.php/question/questionType?type=4 爬取投诉帖子的编号.帖子的url.帖子的标题,和帖子里的内容 ...
- Scrapy爬虫及案例剖析
由于互联网的极速发展,所有现在的信息处于大量堆积的状态,我们既要向外界获取大量数据,又要在大量数据中过滤无用的数据.针对我们有益的数据需要我们进行指定抓取,从而出现了现在的爬虫技术,通过爬虫技术我们可 ...
随机推荐
- 【前端_js】Bootstrap之表单验证
Bootstrap表单验证插件bootstrapValidator使用方法整理 BootstrapValidator 表单验证超详细教程
- linux设备驱动程序--在用户空间注册文件接口
linux字符设备驱动程序--创建设备节点 基于4.14内核,运行在beagleBone green 在上一讲中,我们写了第一个linux设备驱动程序--hello_world,在驱动程序中,我们什么 ...
- spring cloud微服务实战教程/pdf/视频/百度云资源
资源站:http://www.supan.vip 点击进入直接查找资源: http://www.supan.vip/spring%20cloud微服务实战 <Spring Cloud微服务实战& ...
- Vuex准备
(1)简介 每一个 Vuex 应用的核心就是 store(仓库).“store”基本上就是一个容器,它包含着你的应用中大部分的状态 (state).Vuex 和单纯的全局对象有以下两点不同: Vuex ...
- 项目Beta冲刺(4/7)(追光的人)(2019.5.26)
所属课程 软件工程1916 作业要求 Beta冲刺博客汇总 团队名称 追光的人 作业目标 描述Beta冲刺每日的scrum和PM报告两部分 队员学号 队员博客 221600219 小墨 https:/ ...
- js版本规范的表示:ES6 == ES 6 == ECMAScript 6 == ECMA-262 6
Ecma 国际大会宣布正式批准ECMA-262第 6 版,亦即 ECMAScript 2015(曾用名:ECMAScript 6.ES6)的语言规范. 关系 ECMA-262 == ECMAScrip ...
- UI系统的核心在于渲染机制:效率与生命--原生渲染为何比webview渲染快?
作者:谷宝剑链接:https://www.zhihu.com/question/264592475/answer/283852178来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- windows10家庭版升级专业版/企业版
以防万一,还是把Windows10家庭版的密钥保存下来. 一.保留原密钥 1. Win+R,输入regedit 2. 进入目录 HKEY_LOCAL_MACHINE\SOFTWARE\Microsof ...
- Frightful Formula Gym - 101480F (待定系数法)
Problem F: Frightful Formula \[ Time Limit: 10 s \quad Memory Limit: 512 MiB \] 题意 题意就是存在一个\(n*n\)的矩 ...
- 「插头dp」
Tasklist: 标识设计 神奇游乐园 Manhattan Wiring ParkII 游览计划 CITY: 只用一条回路经过所有可通过的块 括号匹配,注意结束位置不一定是(n,m) 地板: 分已经 ...