scrapy爬虫案例:问政平台
问政平台
http://wz.sun0769.com/index.php/question/questionType?type=4
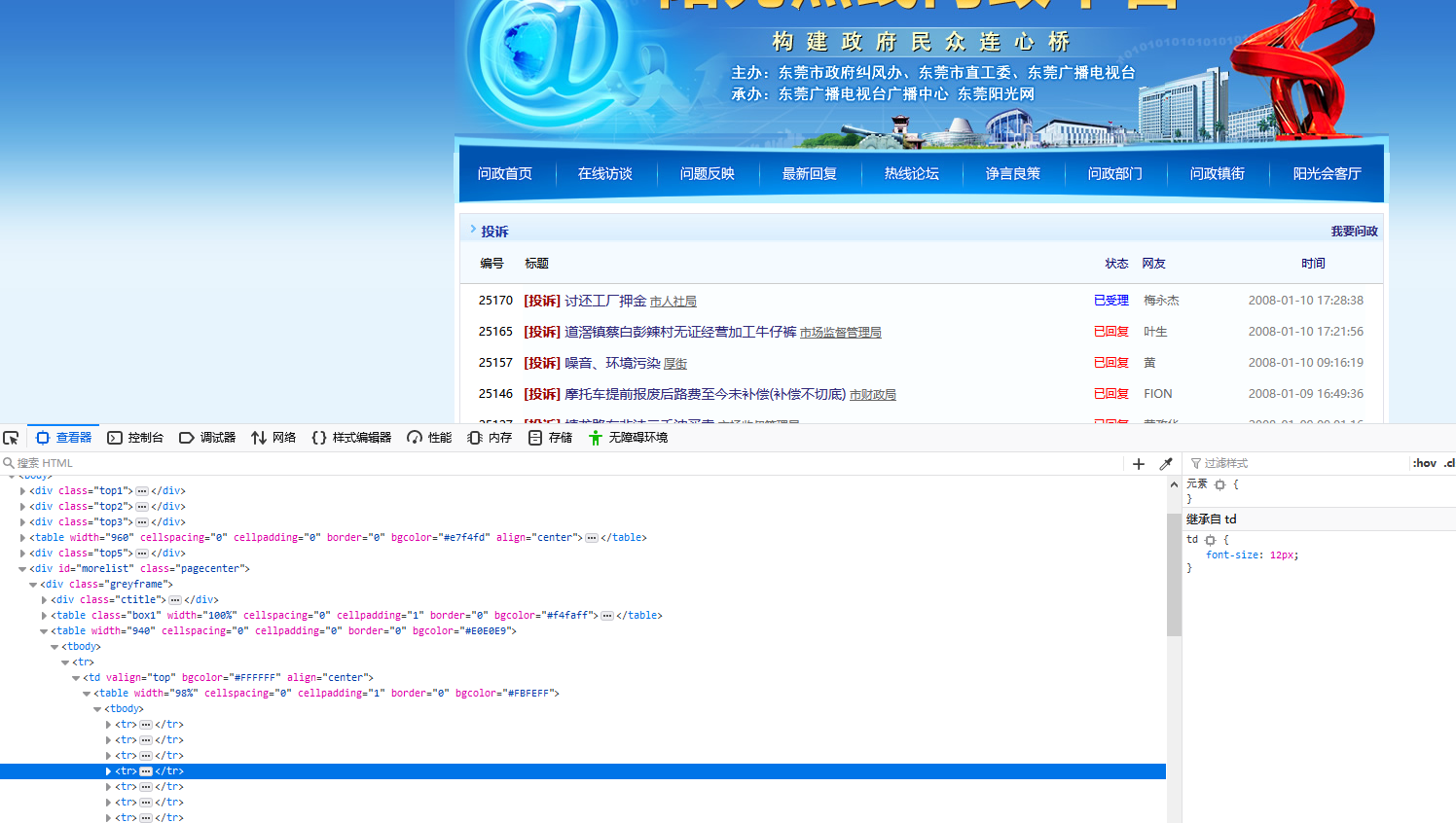
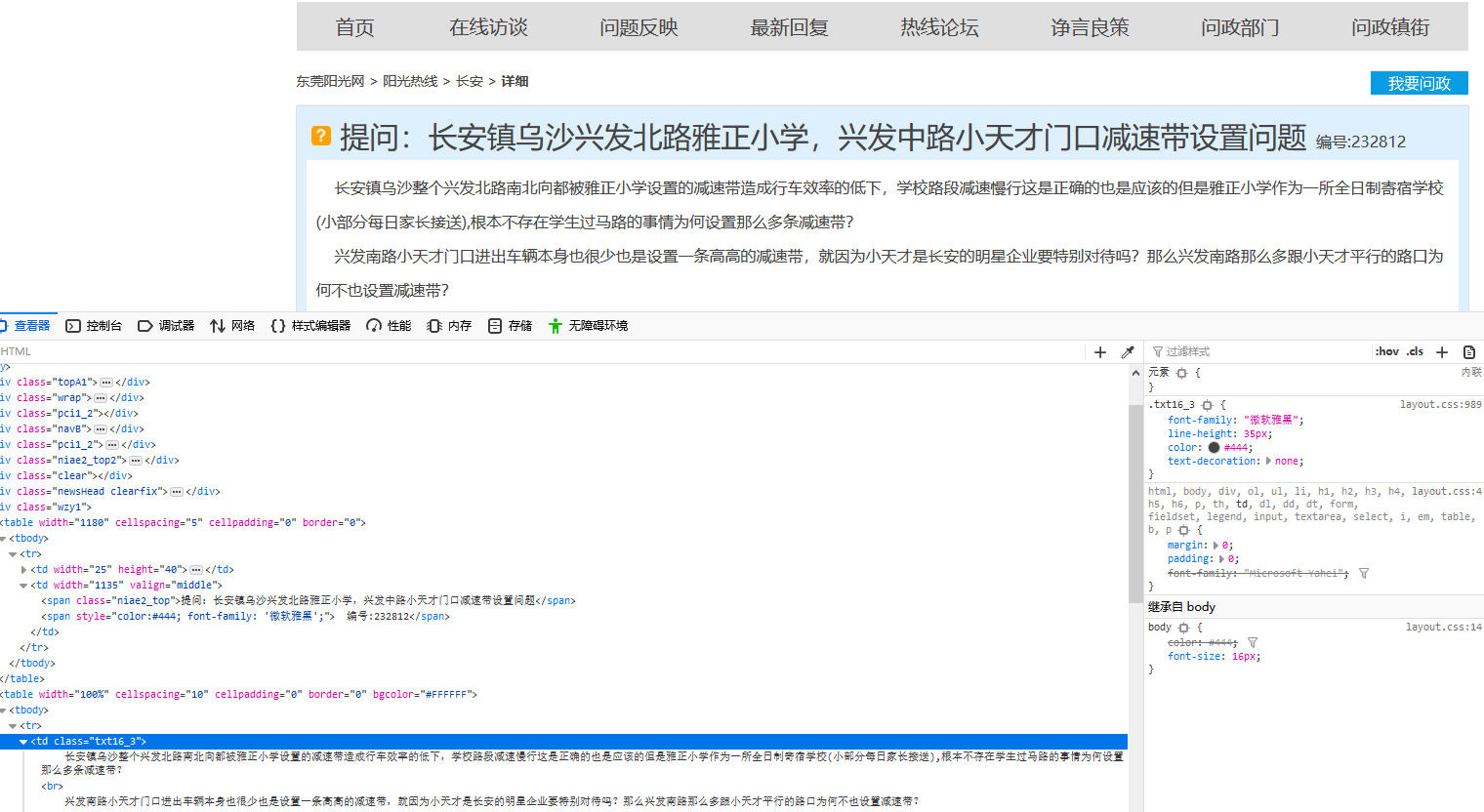
爬取投诉帖子的编号、帖子的url、帖子的标题,和帖子里的内容。
items.py
import scrapy class DongguanItem(scrapy.Item):
# 每个帖子的标题
title = scrapy.Field()
# 每个帖子的编号
number = scrapy.Field()
# 每个帖子的文字内容
content = scrapy.Field()
# 每个帖子的url
url = scrapy.Field()
spiders/sunwz.py
# -*- coding: utf-8 -*- import scrapy
from scrapy.spiders import CrawlSpider from scrapyDemo.items import DongguanItem class SunSpider(CrawlSpider):
name = 'sun'
allowed_domains = ['wz.sun0769.com']
url = 'http://wz.sun0769.com/index.php/question/questionType?type=4&page='
offset = 0
start_urls = [url + str(offset)] def parse(self, response):
# 取出每个页面里帖子链接列表
links = response.xpath("//div[@class='greyframe']/table//td/a[@class='news14']/@href").extract()
# 迭代发送每个帖子的请求,调用parse_item方法处理
for link in links:
yield scrapy.Request(link, callback=self.parse_item)
# 设置页码终止条件,并且每次发送新的页面请求调用parse方法处理
if self.offset <= 3876:
self.offset += 30
yield scrapy.Request(self.url + str(self.offset), callback=self.parse) # 处理每个帖子里
def parse_item(self, response):
item = DongguanItem()
# 标题
item['title'] = response.xpath('//span[contains(@class, "niae2_top")]/text()').extract()[0]
# 编号
item['number'] = response.xpath('//div[contains(@class, "wzy1")]//td//span/text()').extract()[1]
# 文字内容,默认先取出有图片情况下的文字内容列表
content = response.xpath('//td[@class="txt16_3"]/text()').extract()
# 如果没有内容,则取出没有图片情况下的文字内容列表
if len(content) == 0:
content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()
# content为列表,通过join方法拼接为字符串,并去除首尾空格
item['content'] = "".join(content).strip()
else:
item['content'] = "".join(content).strip() # 链接
item['url'] = response.url
yield item
pipelines.py
# -*- coding: utf-8 -*- # 文件处理类库,可以指定编码格式
import codecs
import json class DongguanPipeline(object): def __init__(self):
# 创建一个只写文件,指定文本编码格式为utf-8
self.filename = codecs.open('sunwz.json', 'w', encoding='utf-8') def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.filename.write(content)
return item def spider_closed(self, spider):
self.file.close()
settings.py
ITEM_PIPELINES = {
'dongguan.pipelines.DongguanPipeline': 300,
}
# 日志文件名和处理等级
LOG_FILE = "dg.log"
LOG_LEVEL = "DEBUG"
在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl sunwz'.split())
执行程序
py2 main.py
效果:

scrapy爬虫案例:问政平台的更多相关文章
- scrapy爬虫案例--爬取阳关热线问政平台
阳光热线问政平台:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1 爬取最新问政帖子的编号.投诉标题.投诉内容以 ...
- Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表 然后编写各个模块 item.py import scrapy class JianliItem(scrapy.Item): name = scrapy.Field() ...
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- scrapy爬虫案例:用MongoDB保存数据
用Pymongo保存数据 爬取豆瓣电影top250movie.douban.com/top250的电影数据,并保存在MongoDB中. items.py class DoubanspiderItem( ...
- 爬虫——Scrapy框架案例二:阳光问政平台
阳光热线问政平台 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖子的编号.投诉类 ...
- Scrapy项目_阳光热线问政平台
目的: 爬取阳光热线问政平台问题中每个帖子的标题.详情URL.详情内容.图片以及发布时间 步骤: 1.创建爬虫项目 1 scrapy startproject yangguang 2 cd yangg ...
- 如何让你的scrapy爬虫不再被ban之二(利用第三方平台crawlera做scrapy爬虫防屏蔽)
我们在做scrapy爬虫的时候,爬虫经常被ban是常态.然而前面的文章如何让你的scrapy爬虫不再被ban,介绍了scrapy爬虫防屏蔽的各种策略组合.前面采用的是禁用cookies.动态设置use ...
- 爬虫框架Scrapy之案例一
阳光热线问政平台 http://wz.sun0769.com/index.php/question/questionType?type=4 爬取投诉帖子的编号.帖子的url.帖子的标题,和帖子里的内容 ...
- Scrapy爬虫及案例剖析
由于互联网的极速发展,所有现在的信息处于大量堆积的状态,我们既要向外界获取大量数据,又要在大量数据中过滤无用的数据.针对我们有益的数据需要我们进行指定抓取,从而出现了现在的爬虫技术,通过爬虫技术我们可 ...
随机推荐
- PHP的垃圾回收机制之引用计数
1,介绍 php的垃圾回收机制(GC)是在PHP5之后出现的,而在PHP5.3版本之前使用的都是“引用计数”的方式.实现引用计数的实质就是在每个内存对象中都有一个计数器,当内存对象被变量引用时,计数器 ...
- 浅谈Python设计模式 - 工厂模式
声明:本系列文章主要参考<精通Python设计模式>一书,并且参考一些资料,结合自己的一些看法来总结而来. 工厂模式: 顾名思义,工厂则是根据提供的不同的材料,生产出不同的产品.那么在编程 ...
- 《linux就该这么学》课堂笔记10 SWAP、磁盘容量配额、软硬链接、RAID
1988年,加利福尼亚大学伯克利分校首次提出并定义了RAID技术的概念.RAID技术通过把多个硬盘设备组合成一个容量更大.安全性更好的磁盘阵列,并把数据切割成多个区段后分别存放在各个不同的物理硬盘设备 ...
- IEnumerable,ICollection ,
一般规定——IEnumerable < >(MSDN:http://msdn.microsoft.com/en-us/library/system.collections.ienumera ...
- 24、python re正则表达式模块
一.re模块的基本使用 Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符.正则表达式是用来匹配处理字符串的. 假如你需要匹配文本中的字符\,Python里的使用原生字符串表示:r'\\'表 ...
- wordpress自定义菜单间添加分隔符
我们知道wordpress自定义菜单每个item是用<li></li>来固定的,那如果想在</li>加分隔符要如何操作呢?如下图所示.我们可以用PHP的str_re ...
- http协议 | http缓存
缓存控制 1.禁止进行缓存:缓存中不得存储任何关于客户端请求和服务端响应的内容.每次由客户端发起的请求都会下载完整的响应内容. Cache-Control: no-store Cache-Contro ...
- 顶部选项卡-可左右拖动(webview)示例如何做到tab与webview联动滚动
顶部选项卡-可左右拖动(webview)的示例中,如何做到tab与webview联动滚动,效果类似uc头条一样 ps:自己也不确定有多少了到航头,页面怎么办,到航头从后台获取,页面不可能建N多个.ht ...
- (3)使用Android手机作为树莓派的屏幕
https://jingyan.baidu.com/album/676629977483b154d51b848e.html
- 电商平台+keepalived高可用
192.168.189.131 电商平台 192.168.189.129 MySQL主192.168.189.130 MySQL备192.168.189.181 VIP 配置MySQL为互为主从并结合 ...