mysql group by 查询非聚集列
本文为博主原创,转载请注明出处:
mysql使用group by可以使用一些聚合函数,可以计算最大值(max(column)),最小值(min(column)),总和(sum(column)),平均数(avg(column()))等等,
在使用聚合函数的函数的时候,我们只可以查询聚合函数相关的列,其余的列则不能进行查询。示例如下:
表结构如下:
CREATE TABLE `fucdn_hot_rank_domain` (
`id` int(12) NOT NULL AUTO_INCREMENT COMMENT '主键',
`domain` int(11) NOT NULL COMMENT '域名id',
`band` double NOT NULL COMMENT '带宽,单位为B',
`total` int(16) NOT NULL COMMENT '请求数',
`clock` varchar(255) NOT NULL COMMENT '时间',
PRIMARY KEY (`id`),
UNIQUE KEY `domain` (`domain`,`clock`),
KEY `domain_id` (`domain`)
) ENGINE=InnoDB AUTO_INCREMENT=21961394 DEFAULT CHARSET=utf8 COMMENT='域名用量热门排行表';
使用聚合函数查询非聚合列:
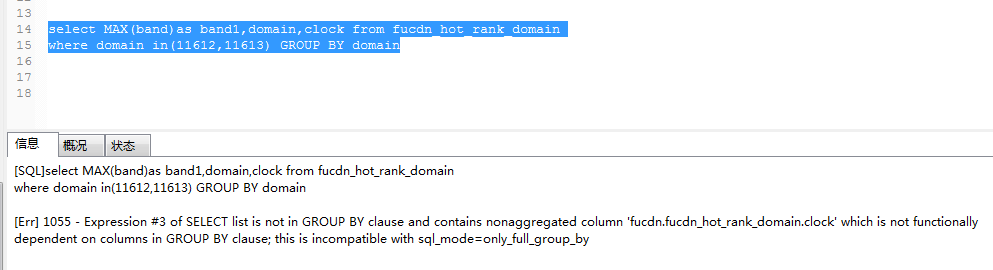
查询非聚合列的时候异常提示:
which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by,不在聚合函数之内,查询异常。
如果要查询非聚合函数的列,可以再嵌套一遍进行关联查询,
使用如下:
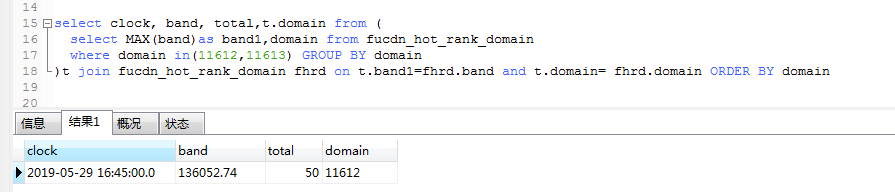
这种查询的方便之处在于它可以避免写多个sql进行多次查询,但如果需要查询的时候有多条,则需要手动过滤一下。项目中用到的sql如下:
select clock, band, total,domain from (
select MAX(band)as band1,domain from fucdn_hot_rank_domain
where domain
in(11612,11613,11614,11615,11616,11617,11618,11619,11620)
and clock BETWEEN '2019-10-20 00:00:00.0' and '2019-10-20 23:59:59.0' GROUP BY domain ORDER BY band1 desc limit 20
)t join fucdn_hot_rank_domain fhrd on t.band1=fhrd.band and t.domain= fhrd.domain ORDER BY domain
之前代码中要查询这些数据的时候是分批次查询的,先查询所有数据,再根据过滤出的所有域名,计算出对应的峰值以及峰值时间。
代码都是用的流式计算,由于数据量大,计算相对还是比较慢的,后来优化为上面的sql后,性能比之前快了两倍多。
原来实现的代码如下,以供警醒,哈哈
@Override
public List<HotRankDomainResult> getHotRankDomainList(DomainCodeHelper helper) throws FucdnException {
List<HotRankDomainResult> resultList = new ArrayList<>();
System.out.println("<<<<<<<<<<<<<<selectTime::"+new Date());
List<HotRankHelper> helperList = hotRankDao.getHotRankDomainList(helper);
System.out.println(">>>>>>>>>>>>>>selectEndTime::"+new Date()); // 计算出域名带宽峰值,峰值时间,总流量,总请求数等
// 1.获取域名列表
List<String> domainList = helperList.stream().map(HotRankHelper::getDomain).collect(Collectors.toList()); // 2.对域名列表去重
domainList = domainList.stream().distinct().collect(Collectors.toList());
for (String domain : domainList) {
HotRankDomainResult resultDetail = new HotRankDomainResult();
// 获取域名对应的列表数据
List<HotRankHelper> domainResultList = helperList.stream()
.filter((HotRankHelper flow) -> domain.equals(flow.getDomain())).collect(Collectors.toList());
// 计算峰值
domainResultList = domainResultList.stream().sorted(Comparator.comparing(HotRankHelper::getBand).reversed())
.collect(Collectors.toList()); // 计算总流量和请求数
double totalFlow = domainResultList.stream().collect(Collectors.summingDouble(HotRankHelper::getBand));
int totalRequest = domainResultList.stream().collect(Collectors.summingInt(HotRankHelper::getTotal));
// 获取峰值数据
HotRankHelper topHelper = domainResultList.get(0);
resultDetail.setMaxBand(topHelper.getBand());
resultDetail.setMaxBandTime(topHelper.getClock());
resultDetail.setDomain(topHelper.getDomain());
resultDetail.setTotalFlow(totalFlow);
resultDetail.setTotalRequest(Integer.toString(totalRequest));
resultList.add(resultDetail);
}
// 对集合进行排序:降序
resultList = resultList.stream().sorted(Comparator.comparing(HotRankDomainResult::getMaxBand).reversed())
.collect(Collectors.toList());
if (resultList.size() > 20) {
// 获取前20
resultList = resultList.subList(0, 20);
} System.out.println(">>>>>>>>>>>>>>sortEndTime::"+new Date());
return resultList;
}
mysql group by 查询非聚集列的更多相关文章
- PostgreSql之在group by查询下拼接列字符串
首先创建group_concat聚集函数: CREATE AGGREGATE group_concat(anyelement) ( sfunc = array_append, -- 每行的操作函数,将 ...
- oracle中clob字段怎么查询非空列_20180517
select * from uap_groupsynlogvo a where a.log_msg is not null ; 附加demo的建表脚本跟业务数据. 链接:https://pan.bai ...
- SQL Server 2014聚集列存储索引
转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog) 简介 之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL查询优化:详解SQL Server非聚集索引(转载)
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml 在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索 ...
- SQL Server 2014 聚集列存储
SQL Server 自2012以来引入了列存储的概念,至今2016对列存储的支持已经是非常友好了.由于我这边线上环境主要是2014,所以本文是以2014为基础的SQL Server 的列存储的介绍. ...
- SQL Server 2016 —— 聚集列存储索引的功能增强
作者 Jonathan Allen,译者 邵思华 发布于 2015年6月14日 聚集列存储索引(CC Index)是SQL Server 2014中两大最引 ...
- MySQL 排错-解决MySQL非聚合列未包含在GROUP BY子句报错问题
排错-解决MySQL非聚合列未包含在GROUP BY子句报错问题 By:授客 QQ:1033553122 测试环境 win10 MySQL 5.7 问题描述: 执行类似以下mysql查询, SEL ...
- 使用聚集索引和非聚集索引对MySQL分页查询的优化
内容摘录来源:MSSQL123 ,lujun9972.github.io/blog/2018/03/13/如何编写bash-completion-script/ 一.先公布下结论: 1.如果分页排序字 ...
随机推荐
- SVM 实现多分类思路
svm 是针对二分类问题, 如果要进行多分类, 无非就是多训练几个svm呗 OVR (one versus rest) 对于k个类别(k>2) 的情况, 训练k个svm, 其中, 第j个svm用 ...
- sqlserver语句随笔
替换数据:update 表名 set 列=replace(列,'要替换的数据','替换成的数据'),例子:update kers set KeyConn=replace(KeyConn,'-','/' ...
- IP切换小技巧
说到这个问题很多人都有同感.公司一般使用的都是静态的IP(如图:使用下面的IP地址),而我们在外面是用的一般是动态获取的IP(如图:自动获得IP地址),因此就产生了一个问题,需要来回切换IP,也就是需 ...
- MySQL IFNULL() 函数
MySQL函数 IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值. IFNULL() 函数语法格式为: IF ...
- Shell 编程 条件语句
本篇主要写一些shell脚本条件语句的使用. 条件测试 test 条件表达式 [ 条件表达式 ] 文件测试 -d:测试是否为目录(Directory). -e:测试文件或目录是否存在(Exist). ...
- python-gitlab 之更改 merge_method
参考: https://docs.gitlab.com/ee/api/projects.html https://python-gitlab.readthedocs.io/en/stable/gl_o ...
- Httpd服务进阶知识-基于FASTCGI实现的LAMP架构
Httpd服务进阶知识-基于FASTCGI实现的LAMP架构 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.httpd+php结合的方式 module: php fastcgi ...
- Httpd服务入门知识-Httpd服务常见配置案例之基于客户端来源地址实现访问控制
Httpd服务入门知识-Httpd服务常见配置案例之基于客户端来源地址实现访问控制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Options 1>.OPTIONS指 ...
- 启动keepalived报错(VI_1): received an invalid passwd!
一.署keepalived后测试主down掉后无法自动切换到备 查看message日志一直报此错误 [root@lb-nginx-master ~]# tailf /var/log/messages ...
- 线性排序总结(c++实现)
前面介绍了一些常用的比较排序算法,它们都是通过比较两个元素的大小进行排序,归并排序和堆排序在最坏情况下的复杂度为O(nlgn),可以证明(使用决策树模型),通过比较进行排序,算法的下界为O(nlgn) ...