SQL Server 2014聚集列存储索引
转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog)
简介
之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也就是可更新列存储索引。在SQL Server 2012中首次引入了基于列存储数据格式的存储方式。叫做“列存储索引”。前一篇我已经比较了行存储索引与非聚集的列存储索引(http://www.cnblogs.com/wenBlog/p/5682024.html)。其中对于在小表的指定值或者小范围的查询来讲,尤其针对事务性的负载行存储是很合适的。但是对于分析性负载像数据仓库和BI,在查询中将会对大量数据进行全扫描,例如事实表,这时候列存储索引就是更好地选择。
列存储索引结构
在列存储索引中,数据按照独立列组织到一起形成索引结构。每列都数据都位于被高度压缩的数据集中,叫做数据段。这个数据段只包含该列的值,对于大型表它分到多个数据段中,每个数据段中只含有100万行数据,这就叫做行组、数据段由一个或者多个数据页组成。数据将在内存和硬盘上以数据段的形式传输。
这种索引提高了数据仓库的查询效率。这种通过压缩获得数据格式要比B-Tree结构的压缩率高7倍多。同时由于列存储索引使用了批处理模式执行,数据处理也是批处理的,较少了CPU的使用。列存储索引强化了检索数据的速度,与行存储不同的是不用查询所有列。因为这个原因,更少数据被读取到内存中,再到处理器缓存处理。相关的这些因素都会减少硬盘IO,提高整体查询的性能。
在2014中列存储索引有以下限制:
最多支持1024列在你的索引中;
列存储索引不能被定义为唯一性索引;
不能创建视图;
不能包含稀疏列;
不能使用ALTER INDEX来修改索引,只能drop然后重新创建;
不能使用INCLUDE关键字。
不能排序列;
不能使用FILESTREAM属性。
当然还有一些数据类型不能包含在列存储索引中(binary , varbinary , ntext , text, , image, varchar(max) , nvarchar(max), uniqueidentifier, rowversion , sql_variant,精度大于18 的decimal,CLR 和xml等)
另一方面,对于索引列900字节的限制也不适用与列存储索引。
在SQL Server2012 中,只能创建非聚集列存储索引,并且不能更新。为了更新你必须删除索引,然后进行插入、更新或者删除的操作后在重建索引。
在2014中列存储索引得到了不小的提升,比如消除了只读限制。增加了聚集列存储索引,列存储索引作为了表的存储方式,存储表的数据。
比较聚集和非聚集列存储索引
区别 |
聚集列存储索引 |
非聚集列存储索引 |
| 索引列 | 需要指定列上创建 | 所有列都包含在内 |
| 存储 | 额外增加百分之10的空间作为索引 | 压缩十倍的数据量,如果表之前是页压缩,则可以压缩5倍左右 |
| 更新 | 是 | 否 |
| 排序 | 在创建之前进行排序 | 否 |
列存储索引的结构图:
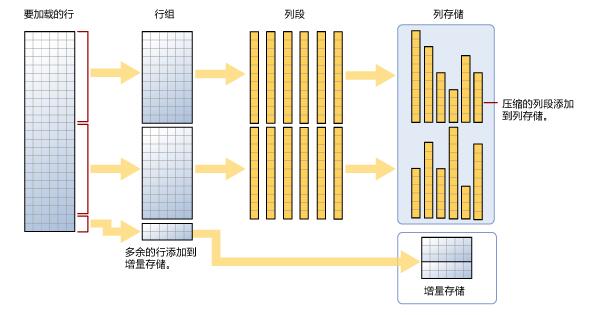
如图增量存储部分我们叫做deltastore,用于存储不够最小行组大小的数据。流程就是将行数据提取成列数据,然后进行压缩存储,多余的部分放到deltastore中。
聚集索引插入、删除和更新实现逻辑:
插入新行的时候,值被存储在deltastore中,直到达到最小rowgroup(行组)大小时,然后压缩并移动到列存储数据段中。
删除数据时,行将被删除从deltastore存储中,但是在列存储索引数据段中只是被标记为删除,除非重建后才会被真的删除。
更新的时候,在deltastore存储中行数据被删除,然后在列存储数据段中被标记为删除,新的列别插入到deltastore中。
最后当重建索引的时。SQLServer将会删除所有标记为删除的数据段,数据存储在deltastore中的将与数据段中的数据合并,然后进行压缩。
下面我们来展示下如何从列存储索引中获得性能:
我们首先创建一个事实表在数据库中脚本如下:
USE SQLShackDemo GO
--创建表
CREATE TABLE [dbo].[FactFinance]( [FinanceKey] [int] NOT NULL, [DateKey] [int] NOT NULL, [OrganizationKey] [int] NOT NULL, [DepartmentGroupKey] [int] NOT NULL, [ScenarioKey] [int] NOT NULL, [AccountKey] [int] NOT NULL, [Amount] [float] NOT NULL, [Date] [datetime] NULL ) ON [PRIMARY] GO --创建聚集索引: CREATE CLUSTERED INDEX [IX_FactFinance_FinanceKey_DateKey] ON [dbo].[FactFinance] ( [FinanceKey],[DateKey])
GO --查询表: SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance]

让我们检查下聚集索引扫描操作符,Estimated I/O Cost(估计IO花销) 的值为0.183866,Estimated CPU Cost(估计CPU花销)为0.0435069,为了比较列索引的值,我们先记住:

现在我们创建列存储索引在非聚集索引:
CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey] ON [FactFinance] ([FinanceKey],[DateKey],[OrganizationKey],[DepartmentGroupKey]) GO
SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance]

这个列存储索引扫描操作符如下所示:
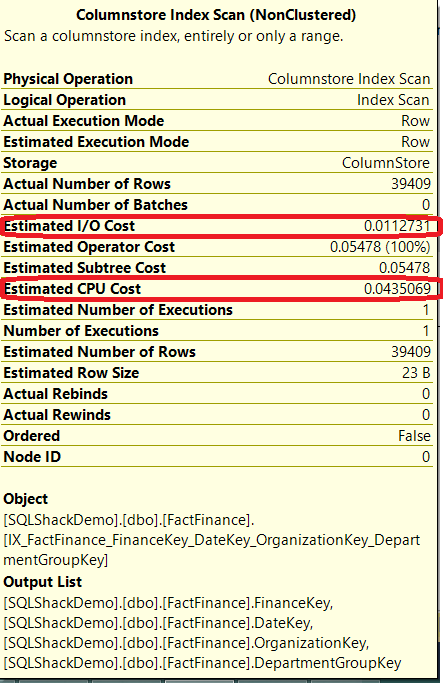
如上所示,Estimated I/O Cost从0.183866下降到0.0112731,这是因为SQL引擎只检索需要的列,节省了IO和内存资源。Estimated CPU的时间没有变化。
IO强化与之前相比是明显的,我们也可以比较两个查询,启用I/O statistics,检查IO的hits 表现如下:
SET STATISTICS IO ON
GO
SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index (IX_FactFinance_FinanceKey_DateKey))
GO
SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index(IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey))
正如所示,比较执行计划,使用列存储索引的要比行索引的好四倍,那么期望一下处理大数据时的10倍性能:
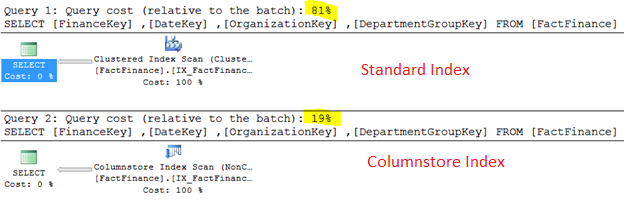
当比较逻辑读时你也能发现相似的结果。明显这个逻辑读也是四倍+关系。

那么我们可以根据下图概括一下传统的行索引与列存储所以的一般性区别:

列存储索引的创建
也能够使用SSMS创建索引: Indexes -> New Index ->Non-Clustered Columnstore Index 如下:
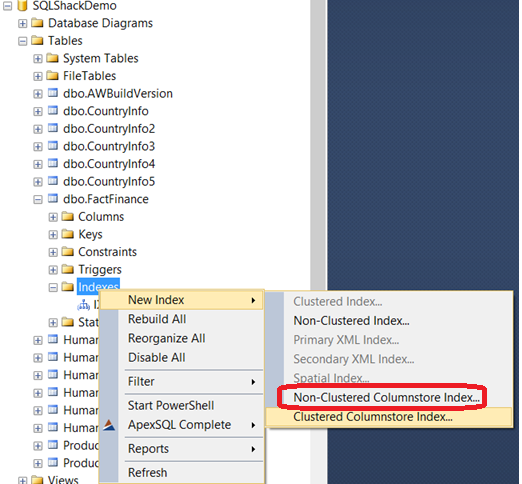
与非聚集索引创建类似,选择列,然后这些列没有排序也不能使用Include选项:
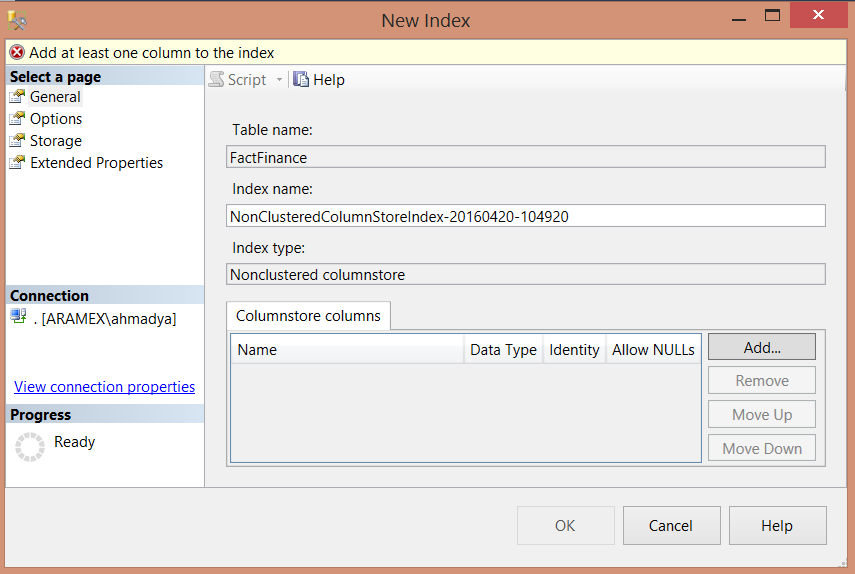
下图中我在SQL Server2014 企业版中,创建聚集索引:
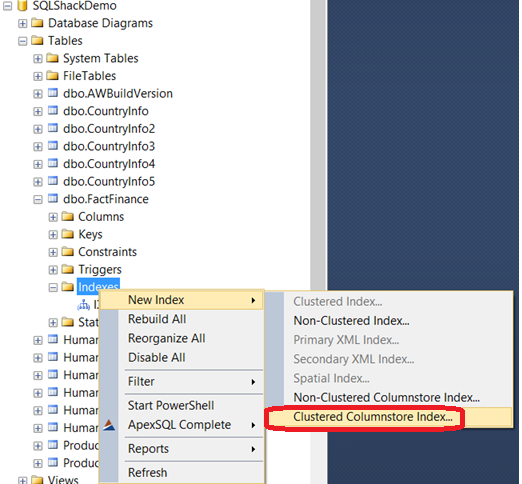
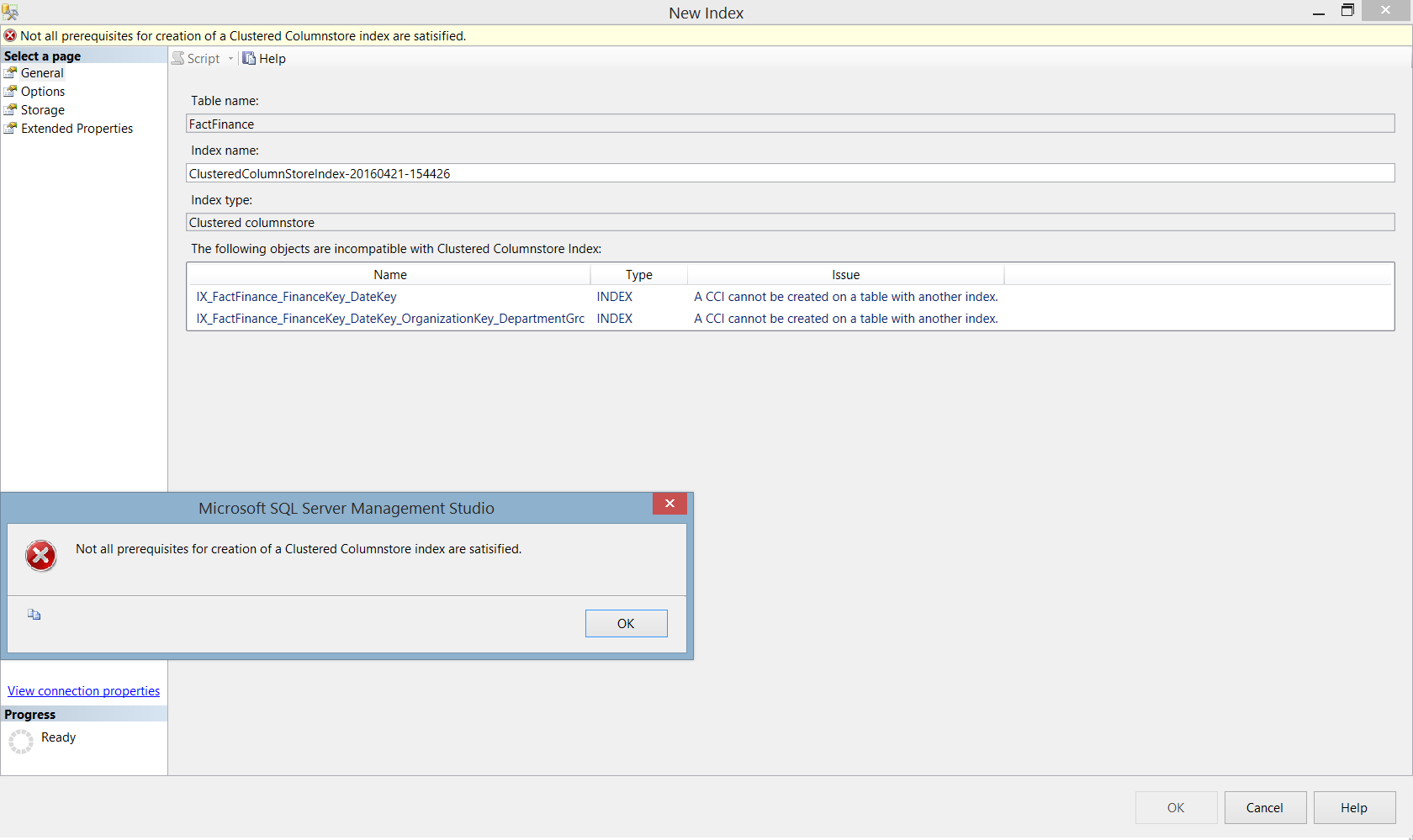
需要注意的是如果在表上已经有其他索引,尝试创建聚集列存储索引就会出现错误,正如我们之前说的,同一个表中不能或者其他索引:
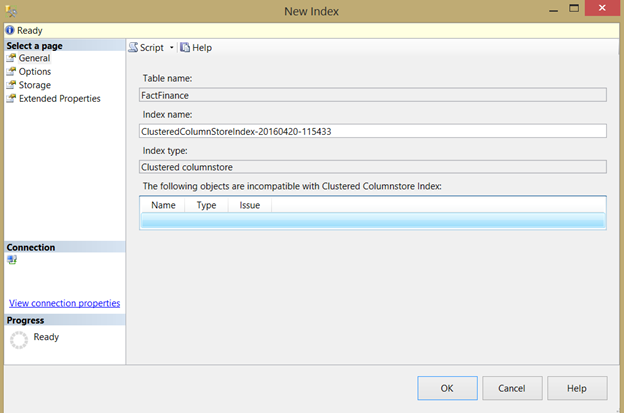
不用选择列,所有数据都包含在内了:
几个好的应用场景:
如果你有大型的事实表并且存在查询问题的,或者SSAS存在其他性能问题的,列存储是一个不错的方案。一下两种情况是经过测试的比较好的应用场景:
- 对于高频率响应的报表/仪表板,尤其分析当性能表现不佳的时候,会有很不错的性能。
- 对于ETL的过程来讲,源数据的列存储索引将会极大提高性能,如果数据足够大甚至可以考虑临时创建列存储索引。然后执行ETL。
总结:
列存储索引是一个使用SQL Server性能优化的方案,通过减少IO消耗,尤其对数据仓库和BI查询都是由明显性能提升。它通过排序数据作为列存储,然后压缩,并使用批处理来处理数据。当然,必须要确保使用列存储索引的使用带来了好处,而不会引起其他性能问题才能使用。比如需要注意使用的硬件环境和数据,如果没有join、过滤、或者聚合导出巨大的数据量没有足够的内存则将被暂时放入硬盘进行switch off,从而引起查询性能下降。尽量在使用之前在测试环境中测试是否适合使用,同时还要关注其他环节是否受影响。
补充,在2016中增加的几个我认为不错新的feature:
基于聚集列存储索引的 B 树索引;
基于内存优化表的列存储索引;
CREATE TABLE 和 ALTER TABLE 中的列存储索引的压缩延迟选项;
单线程查询的批处理执行。
SQL Server 2014聚集列存储索引的更多相关文章
- SQL Server 2014 聚集列存储
SQL Server 自2012以来引入了列存储的概念,至今2016对列存储的支持已经是非常友好了.由于我这边线上环境主要是2014,所以本文是以2014为基础的SQL Server 的列存储的介绍. ...
- SQL Server 2016 —— 聚集列存储索引的功能增强
作者 Jonathan Allen,译者 邵思华 发布于 2015年6月14日 聚集列存储索引(CC Index)是SQL Server 2014中两大最引 ...
- 在SQL Server 2014里可更新的列存储索引 (Updateable Column Store Indexes)
传统的关系数据库服务引擎往往并不是对超大量数据进行分析计算的最佳平台,为此,SQL Server中开发了分析服务引擎去对大笔数据进行分析计算.当然,对于数据的存放平台SQL Server数据库引擎而言 ...
- 解读SQL Server 2014可更新列存储索引——存储机制
概述 SQL Server 2014被号称是微软数据库的一个革命性版本,其性能的提升的幅度是有史以来之最. 可更新的列存储索引作为SQL Server 2014的一个关键功能之一,在提升数据库的查询性 ...
- SQL Server 列存储索引 第四篇:实时运营数据分析
实时运营数据分析(real-time operational analytics )是指同时在同一张数据表上执行分析处理和业务处理.分析查询主要是对海量数据执行聚合查询,而事务主要是指对数据表进行少量 ...
- SQL Server 2014新特性探秘(3)-可更新列存储聚集索引
简介 列存储索引其实在在SQL Server 2012中就已经存在,但SQL Server 2012中只允许建立非聚集列索引,这意味着列索引是在原有的行存储索引之上的引用了底层的数据,因此会 ...
- SQL Server ->> ColumnStore Index(列存储索引)
Columnstored index是SQL Server 2012后加入的重大特性,数据不再以heap或者B Tree的形式存储(row level)存储在每一个数据库文件的页里面,而是以列为单位存 ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
- SQL Server 列存储索引概述
第一次接触ColumnStore是在2017年,数据库环境是SQL Server 2012,Microsoft开始在SQL Server 2012中推广列存储索引,到现在的SQL Server 201 ...
随机推荐
- ASP.NET Core MVC/WebAPi 模型绑定探索
前言 相信一直关注我的园友都知道,我写的博文都没有特别枯燥理论性的东西,主要是当每开启一门新的技术之旅时,刚开始就直接去看底层实现原理,第一会感觉索然无味,第二也不明白到底为何要这样做,所以只有当你用 ...
- 旺财速啃H5框架之Bootstrap(四)
上一篇<<旺财速啃H5框架之Bootstrap(三)>>已经把导航做了,接下来搭建内容框架.... 对于不规整的网页,要做成自适应就有点玩大了.... 例如下面这种版式的页面. ...
- CYQ.Data、ASP.NET Aries 百家企业使用名单
如果您或您所在的公司正在使用此框架,请联系左侧的扣扣,告知我信息,我将为您添加链接: 以下内容为已反馈的用户,(收集始于:2016-08-08),仅展示99家: 序号 企业名称 企业网址 备注 1 山 ...
- ElasticSearch 5学习(9)——映射和分析(string类型废弃)
在ElasticSearch中,存入文档的内容类似于传统数据每个字段一样,都会有一个指定的属性,为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成字符串值,Elasticsearc ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- lua 学习笔记(1)
一.lua函数赋值与函数调用 在lua中函数名也是作为一种变量出现的,即函数和所有其他值一样都是匿名的,当要使用某个函数时,需要将该函数赋值给一个变量,这样在函数块的其他地方就可以通过 ...
- 【开源】.Net Api开放接口文档网站
开源地址:http://git.oschina.net/chejiangyi/ApiView 开源QQ群: .net 开源基础服务 238543768 ApiView .net api的接口文档查看 ...
- CRL快速开发框架系列教程十二(MongoDB支持)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- html5 canvas常用api总结(二)--绘图API
canvas可以绘制出很多奇妙的样式和美丽的效果,通过几个简单的api就可以在画布上呈现出千变万化的效果,还可以制作网页游戏,接下来就总结一下和绘图有关的API. 绘画的时候canvas相当于画布,而 ...
- 趣说游戏AI开发:曼哈顿街角的A*算法
0x00 前言 请叫我标题党!请叫我标题党!请叫我标题党!因为下面的文字既不发生在美国曼哈顿,也不是一个讲述美国梦的故事.相反,这可能只是一篇没有那么枯燥的关于算法的文章.A星算法,这个在游戏寻路开发 ...