Java使用Jsoup之爬取博客数据应用实例
导入Maven依赖
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.</version>
</dependency>
选择你要爬取网站(这里我以爬取自己的博客文章为例)
通过浏览器进入这个网址
如我的博客
使用浏览器调试工具(后面会说到这个目的)
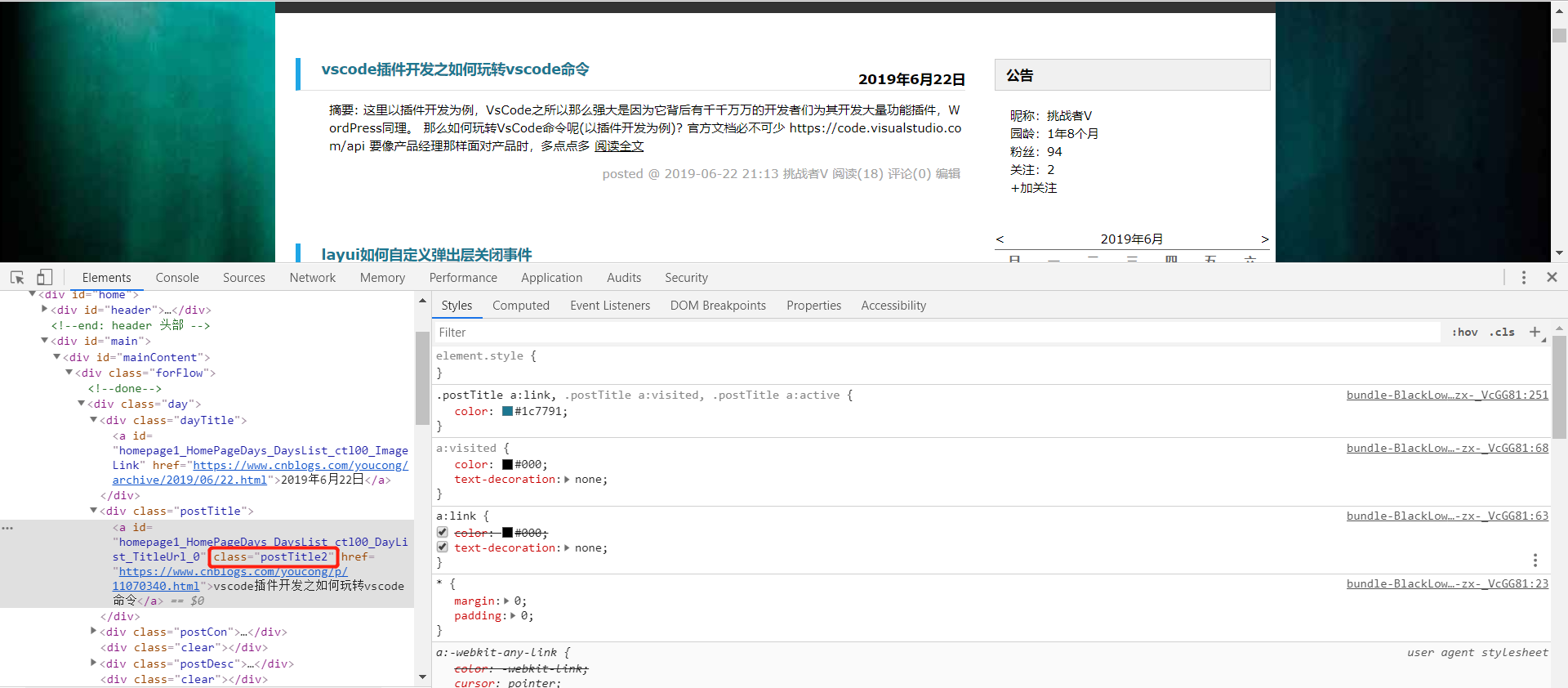
编写对应的Java的代码
package cn.test;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* A simple example, used on the jsoup website.
*/
public class BlogJsoup {
/**
* 获取博客最近十篇文章
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
Connection connection = Jsoup.connect("https://www.cnblogs.com/youcong/");
connection.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36");
try {
Document document = connection.timeout(100000).get();
//包含所有列表的文章
Elements elements = document.getElementsByClass("postTitle2");
for (Element element : elements) {
String path = element.attr("href");
String text = element.text();
String msg = text+" "+path;
System.out.println(msg);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
上面的代码,用流程可以梳理为如下:
连接爬取的网站->设置浏览器请求头(防止因浏览器的限制导致爬取数据失败)->获取整个HTML(实际就是一个html)->选择HTML中的某一个元素(如类选择器postTitle2,如果不指定对应的元素选择器,那么直接爬取的就是整个HTML)->爬取数据并输出
输出结果如图:

Java使用Jsoup之爬取博客数据应用实例的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- 爬虫---lxml爬取博客文章
上一篇大概写了下lxml的用法,今天我们通过案例来实践,爬取我的博客博客并保存在本地 爬取博客园博客 爬取思路: 1.首先找到需要爬取的博客园地址 2.解析博客园地址 # coding:utf-8 i ...
- 使用JAVA爬取博客里面的所有文章
主要思路: 1.找到列表页. 2.找到文章页. 3.用一个队列来保存将要爬取的网页,爬取队头的url,如果队列非空,则一直爬取. 4.如果是列表页,则抽取里面所有的文章url进队:如果是文章页,则直接 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- python 小爬虫爬取博客文章初体验
最近学习 python 走火入魔,趁着热情继续初级体验一下下爬虫,以前用 java也写过,这里还是最初级的爬取html,都没有用html解析器,正则等...而且一直在循环效率肯定### 很低下 imp ...
- (java)Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页
Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页,输出 职位名称*****公司名称*****职位月薪*****工作地点*****发布日期 import java.io.I ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- 【Android 我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取
打算做个自己在博客园的博客APP,首先要能访问首页获取数据获取首页的文章列表,第一步抓取博客首页文章列表内容的功能已实现,在小米2S上的效果图如下: 思路是:通过编写的工具类访问网页,获取页面源代码, ...
- [js高手之路]Node.js实现简易的爬虫-抓取博客文章列表信息
抓取目标:就是我自己的博客:http://www.cnblogs.com/ghostwu/ 需要实现的功能: 抓取文章标题,超链接,文章摘要,发布时间 需要用到的库: node.js自带的http库 ...
随机推荐
- js实现输入密码之延迟星号和点击按钮显示或隐藏
缘由 手机打开segmentfalut时,长时间不登陆了,提示要重新登陆,输入的过程中看到输入密码时,延迟后再变成密文,很好奇,所以捣鼓了一下.本文实现了两种密码展示 代码实现 1 先明后密 js实现 ...
- java实现顺序表、链表、栈 (x)->{持续更新}
1.java实现节点 /** * 节点 * @luminous-xin * @param <T> */ public class Node<T> { T data; Node& ...
- 如何解决NoSuchMethodError
背景 工作中写单测,本来用的Mockito,但是为了mock方法里调用的其他静态方法,所以需要使用powermock,于是开始报错. 我把包引入了,然后照着网上的写单测代码,写完了之后运行.噩梦开始. ...
- python day 15: IO多路复用,socketserver源码培析,
目录 python day 15 1. IO多路复用 2. socketserver源码分析 python day 15 2019/10/20 学习资料来自老男孩教育 1. IO多路复用 ''' I/ ...
- CSS 之 圣杯布局&双飞翼布局
圣杯布局 和 双飞翼布局 是重要布局方式.两者的功能相同,都是为了实现一个两侧宽度固定,中间宽度自适应的三栏布局. 遵循了以下要点: 两侧宽度固定,中间宽度自适应 中间部分在DOM结构上优先,以便先行 ...
- MES实施会有哪些情况?为你介绍两种常见的类型
MES项目实施顾问是一份极具挑战的工作,需具备大量的专业知识,以及丰富的实施经验.今天,小编为大家介绍最常见的两种MES实施顾问类型,希望对大家有所启发. 保姆型实施顾问 是指以实施顾问为主导,只要是 ...
- linux档案和目录管理(后续)
资料来自鸟哥的linux私房菜 四:档案和目录的预设权限和隐藏权限 umask:预设权限,相比与chomd的4,2,1权限,档案满分为666,目录满分为777,umask可以预设消除部分权限,比如一个 ...
- MySQL/MariaDB数据库的触发器
MySQL/MariaDB数据库的触发器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.触发器概述 1>.什么是触发器 触发器的执行不是由程序调用,也不是由手工启动,而是 ...
- k8s部署etcd集群
1.k8s部署高可用etcd集群时遇到了一些麻烦,这个是自己其中一个etcd的配置文件 例如: [Unit] Description=Etcd Server After=network.target ...
- Kali下的内网劫持(三)
前面两种说的是在Kali下的ettercap工具通过配合driftnet和urlsnarf进行数据捕获,接下来我要说的是利用Kali下的另外一种抓包分析工具——wireshark来进行捕获数据: 首先 ...