情感分析snownlp包部分核心代码理解
snownlps是用Python写的个中文情感分析的包,自带了中文正负情感的训练集,主要是评论的语料库。使用的是朴素贝叶斯原理来训练和预测数据。主要看了一下这个包的几个主要的核心代码,看的过程作了一些注释,记录一下免得以后再忘了。
1. sentiment文件夹下的__init__.py,主要是集成了前面写的几个模块的功能,进行打包。
# -*- coding: utf-8 -*-
from __future__ import unicode_literals import os
import codecs from .. import normal
from .. import seg
from ..classification.bayes import Bayes data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),
'sentiment.marshal') class Sentiment(object): def __init__(self):# 实例化Bayes()类作为属性,下面的很多方法都是调用的Bayes()的方法完成的
self.classifier = Bayes() def save(self, fname, iszip=True):# 保存最终的模型
self.classifier.save(fname, iszip) def load(self, fname=data_path, iszip=True):
self.classifier.load(fname, iszip)# 加载贝叶斯模型 # 分词以及去停用词的操作
def handle(self, doc):
words = seg.seg(doc)# 分词
words = normal.filter_stop(words)# 去停用词
return words# 返回分词后的结果,是一个list列表 def train(self, neg_docs, pos_docs):
data = []
for sent in neg_docs:# 读入负样本
data.append([self.handle(sent), 'neg'])
# 所以可以看出进入bayes()的训练的数据data格式是[[[第一行分词],类别],
# [[第二行分词], 类别],
# [[第n行分词],类别]
# ]
for sent in pos_docs: # 读入正样本
data.append([self.handle(sent), 'pos'])
self.classifier.train(data) # 调用的是Bayes模型的训练方法train() def classify(self, sent):
ret, prob = self.classifier.classify(self.handle(sent))#得到分类结果和概率
if ret == 'pos':#默认返回的是pos('正面'),否则就是负面
return prob
return 1-prob classifier = Sentiment()#实例化Sentiment()对象
classifier.load() def train(neg_file, pos_file):
#读取正负语料库文本
neg_docs = codecs.open(neg_file, 'r', 'utf-8').readlines()
pos_docs = codecs.open(pos_file, 'r', 'utf-8').readlines()
global classifier#声明classifier为全局变量,下面重新赋值,虽然值仍然是Sentiment()函数
classifier = Sentiment()
classifier.train(neg_docs, pos_docs)#调用Sentment()模块里的train()方法 def save(fname, iszip=True):
classifier.save(fname, iszip) def load(fname, iszip=True):
classifier.load(fname, iszip) def classify(sent):
return classifier.classify(sent)
2.使用的朴素贝叶斯原理及公式变形
推荐一篇解释得很好的文章:情感分析——深入snownlp原理和实践

classification文件夹下的Bayes.py模块主要包含两个方法train(data)和classify(X),训练和预测方法
# 训练数据集
# 训练的数据data格式是[[['分词1','分词2','分词x'],类别],
# [[第二行分词], 类别],
# [[第n行分词],类别]
# ]
def train(self, data):#训练后得到的self.d={'neg':AddOneProb,'pos':AddOneProb},AddOneProb包含重要的分词信息,他里面也有一个self.d={'分词1':v1,'分词2':v2,'分词3':v3,...}包含分词和相应的分词个数。 # 遍历数据集
for d in data:
# d[1]标签-->分类类别
c = d[1]
# 判断数据字典中是否有当前的标签
if c not in self.d:
# 如果没有该标签,加入标签,值是一个AddOneProb对象。其实就是为每个分词建一个AddOnePro对象来计数
self.d[c] = AddOneProb()
# d[0]是评论的分词list,遍历分词list
for word in d[0]:
# 调用AddOneProb中的add方法,添加单词
self.d[c].add(word, 1)#self.d[c]是AddOneProb对象,调用AddOneProb的add()函数来对词word计数,重点看frequency.py中的几个类
# 计算总词数
self.total = sum(map(lambda x: self.d[x].getsum(), self.d.keys()))#self.d[x].getsum()是调用AddOneProb对象的getsum()函数计算词 #对句子x分类,而x是被分过词的列表,(将句子分词的步骤会在Sentiment类中的分类函数classify()执行,这里不要管,只要知道x是分词后的的列表)
def classify(self, x):
tmp = {}
# 遍历每个分类标签,本案例中只有两个类别
for k in self.d:
tmp[k] = log(self.d[k].getsum()) - log(self.total)#计算先验概率,即p(neg)和p(pos)两个类别的概率
for word in x:
tmp[k] += log(self.d[k].freq(word))#计算后验概率,即每个类别条件下某个分词的概率p('词A'|neg)和p('词A'|pos),# 词频,词word不在字典里的话就为0
ret, prob = 0, 0
for k in self.d:#遍历两个类
now = 0#预测值赋初值为0
try:
for otherk in self.d:#当类相同时now=1,类不同时now累加exp(tmp[otherk]-tmp[k]),最终计算now为变形后的朴素贝叶斯预测值的分母
now += exp(tmp[otherk]-tmp[k])#朴素贝叶斯变形式可见博客
now = 1/now#求倒数为得到的这个类的预测值
except OverflowError:
now = 0
if now > prob:#比较两个类别的概率谁大,大的就是这个文本的类别。注意:初始prob等于0,经过遍历后悔更新prob并且prob等于相应类别的朴素贝叶斯概率
ret, prob = k, now
return (ret, prob)
#这里用朴素贝叶斯方法计算
注意:classify()方法中的朴素贝叶斯变形方法的编写,下面两个for循环,先是遍历两个类,比例第一个类,now表示对这个类计算的贝叶斯预测值,赋初值为0,第二个循环遍历第一个类(otherk=k),
exp(tmp[otherk]-tmp[k])=exp(0)=1,则now=1,再遍历第二个类得到上面变形公式中的第二部分值,这两个相加得到的new就是
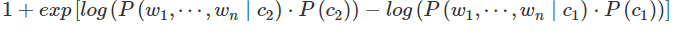
最后再倒数就得到了
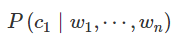
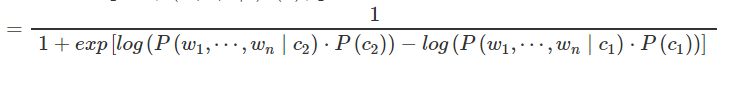
再附加一个上面的AddOneProb()方法的源代码解析,他就是一个对输入的分词计数的函数,将语料库的词进行分类计数,为了训练做得到先后验概率准备:
'''对词计算频数'''
class BaseProb(object): def __init__(self):
self.d = {}#用来存储分词和分词的个数,键是分词,值是分词的个数
self.total = 0.0#计数总共的词个数
self.none = 0 def exists(self, key):#判断字典self.d中是否存在这个词key
return key in self.d def getsum(self):#返回语self.d中存储的词的总数
return self.total def get(self, key):#判断字典中是否存在这个词key,并且返回这分词的词个数
if not self.exists(key):
return False, self.none
return True, self.d[key] def freq(self, key):#计算词key的频率
return float(self.get(key)[1])/self.total def samples(self):#返回字典的键,其实就是返回所有的分词,以列表形式
return self.d.keys() class NormalProb(BaseProb): def add(self, key, value):
if not self.exists(key):
self.d[key] = 0
self.d[key] += value
self.total += value '''对词计数'''
class AddOneProb(BaseProb):#继承BaseProb类,所以BaseProb类中的属性和函数都能用。 def __init__(self):
self.d = {}
self.total = 0.0
self.none = 1 def add(self, key, value):
self.total += value#计算总词数
if not self.exists(key):#如果这个词key不在self.d中的话,那么在字典中加上这个词,即键为此,并且给这个词计数1,同时总的词数量total加1.
self.d[key] = 1
self.total += 1#感觉不应该再加1了,上面都已经计算过总数了????说是后面预测要用到,可能是要平滑
self.d[key] += value#如果字典已经有这个词了的话,那么给这个词数量加1
对于局进行分词的方法Handle()感觉也很重要,也需要看一看。
再码个帖子:snownlp情感分析源码解析,snownlp的Github代码
情感分析snownlp包部分核心代码理解的更多相关文章
- Zepto源码分析(一)核心代码分析
本文只分析核心的部分代码,并且在这部分代码有删减,但是不影响代码的正常运行. 目录 * 用闭包封装Zepto * 开始处理细节 * 正式处理数据(获取选择器选择的DOM) * 正式处理数据(添加DOM ...
- 中文情感分析——snownlp类库 源码注释及使用
最近发现了snownlp这个库,这个类库是专门针对中文文本进行文本挖掘的. 主要功能: 中文分词(Character-Based Generative Model) 词性标注(TnT 3-gram 隐 ...
- python snownlp情感分析简易demo
SnowNLP是国人开发的python类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和T ...
- 学习Redux之分析Redux核心代码分析
1. React,Flux简单介绍 学习React我们知道,React自带View和Controller库,因此,实现过程中不需要其他任何库,也可以独立开发应用.但是,随着应用程序规模的增大,其需要控 ...
- R语言︱情感分析—词典型代码实践(最基础)(一)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:词典型情感分析对词典要求极高,词典中 ...
- Darwin Streaming Server 核心代码分析
基本概念 首先,我针对的代码是Darwin Streaming Server 6.0.3未经任何改动的版本. Darwin Streaming Server从设计模式上看,采用了Reactor的并发服 ...
- 【转】Darwin Streaming Server 核心代码分析
无意中看到了dqzhangp的一篇博客,分析了DSS的核心架构,读完顿时感觉豁然开朗,茅塞顿开,写得非常的鞭辟入里,言简意赅,我想没有相当的功力是写不出这样的文章的,情不自禁转到自己空间来,生怕弄丢了 ...
- 对Java tutorial-examples中hello2核心代码分析
1.在hello2中有两个.java源文件分别是GreetingServlet.Java和ResponseServlet.jva文件主要对以下核心代码做主要分析. String username = ...
- Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析
爬取过程在这里: Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图 本文基于前文爬取生成的douban.txt,基于SnowNLP做情感分析. 依赖库: 豆瓣镜像比较快: ...
随机推荐
- SparkSession
在2.0版本之前,使用Spark必须先创建SparkConf和SparkContext catalog:目录 Spark2.0中引入了SparkSession的概念,SparkConf.SparkCo ...
- leetcode415
public class Solution { public string AddStrings(string num1, string num2) { //判断num1和num2的长度,进行对齐 i ...
- parseInt 和 parseFloat 实现字符串转换为数字
age = '18' a = parseInt(age) b = parseFloat(age)
- Simple2D-15(音乐播放器)使用 glfw 库
glfw 是一个专门针对 OpenGL 的 C 语言库,它提供了一些渲染物体所需的最低限度的接口.它允许用户创建 OpenGL 上下文,定义窗口参数以及处理用户输入. 这次打算使用 GLFW 替代掉 ...
- WebConfig配置讲解
http://www.cnblogs.com/cyq1162/archive/2006/11/16/562690.html sqlserver配置数据库连接字符串时需分2种情况 windows 和 s ...
- GPU寄存器相关
1,shader model 3.0 只有256个常量寄存器,32个临时寄存器.对应dx9, opengl2.0, opengles2.0 2,shader model 4.0 有65536个寄存器, ...
- 电影TS、TC、BD版和HD版
HD的意思是指HDTV,HDTV指网上下载的高清影片,它的画面品质会比BD稍差,主要表现为亮度不足,色彩不自然等.BD是指蓝光(Blu-ray)或称蓝光盘(Blu-ray Disc,缩写为BD),目前 ...
- JDBC连接数据库创建连接对象
1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机), 这通过java.lang.Class类的静态方法forName(String classN ...
- DNN例子
[Tensorflow DNNClassifier ValueError]http://stackoverflow.com/questions/40264622/tensorflow-dnnclass ...
- CentOS7使用yum详细搭建zabbix3.2过程
本文引用于:http://blog.csdn.net/s3275492383/article/details/62417210 一.准备搭建环境: 1.系统:CentOS7 2.默认有使用linux服 ...