Python学习之路 (五)爬虫(四)正则表示式爬去名言网
爬虫的四个主要步骤
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
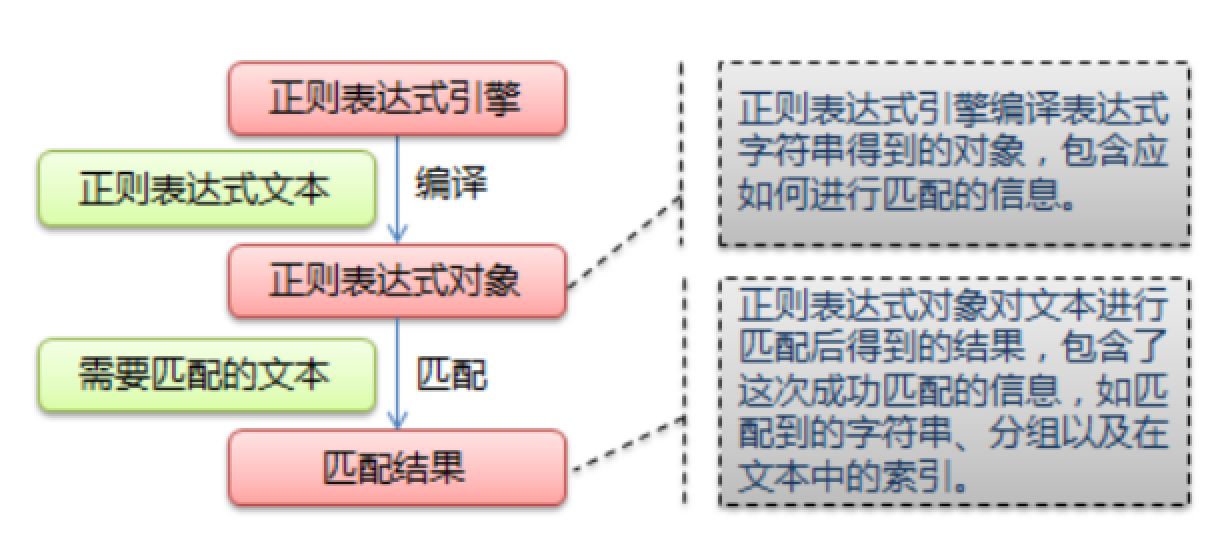
正则表达式匹配规则
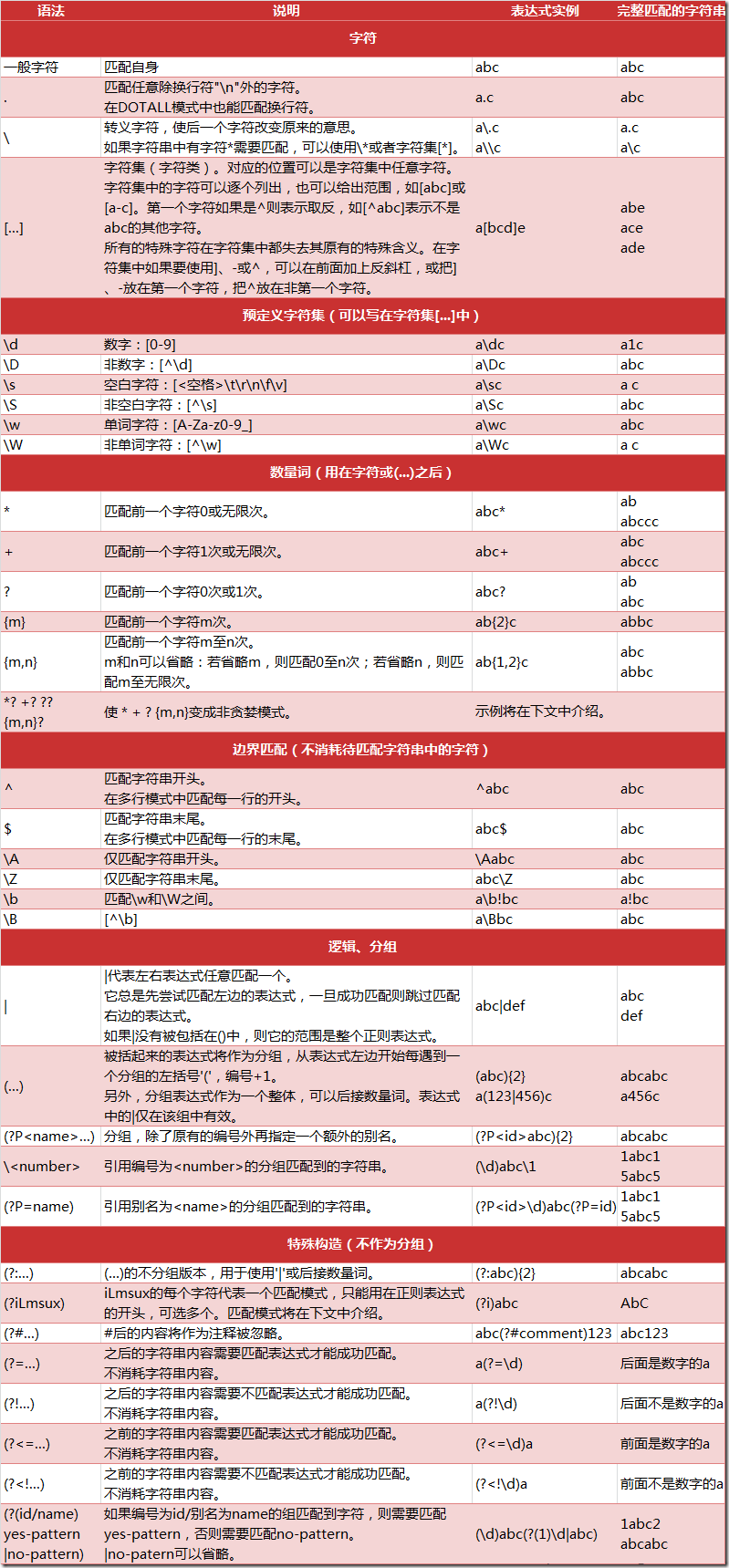
Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
使用正则爬去名言网的名言,只获取首页的10条数据
from urllib.request import urlopen
import re def spider_quotes(): url = "http://quotes.toscrape.com"
response = urlopen(url)
html = response.read().decode("utf-8") # 获取 10 个 名言
quotes = re.findall('<span class="text" itemprop="text">(.*)</span>',html)
list_quotes = []
for quote in quotes:
# strip 从两边开始搜寻,只要发现某个字符在当前这个方法的范围内,统统去掉
list_quotes.append(quote.strip("“”")) # 获取 10 个名言的作者
list_authors = []
authors = re.findall('<small class="author" itemprop="author">(.*)</small>',html)
for author in authors:
list_authors.append(author) # 获取这10个名言的 标签
tags = re.findall('<div class="tags">(.*?)</div>',html,re.RegexFlag.DOTALL)
list_tags = []
for tag in tags:
temp_tags = re.findall('<a class="tag" href=".*">(.*)</a>',tag)
tags_t1 = []
for tag in temp_tags:
tags_t1.append(tag)
list_tags.append(",".join(tags_t1)) # 结果汇总
results = []
for i in range(len(list_quotes)):
results.append("\t".join([list_quotes[i],list_authors[i],list_tags[i]])) for result in results:
print(result) #调取方法
spider_quotes()
BeautifulSoup4解析器
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
使用BeautifulSoup4获取名言网首页数据
from urllib.request import urlopen
from bs4 import BeautifulSoup url = "http://quotes.toscrape.com"
response = urlopen(url) # 初始化一个 bs 实例
# 对应的response对象的解析器, 最常用的解析方式,就是默认的 html.parser
bs = BeautifulSoup(response, "html.parser") # 获取 10 个 名言
spans = bs.select("span.text")
list_quotes = []
for span in spans:
span_text = span.text
list_quotes.append(span_text.strip("“”")) # 获取 10 个名言的作者
authors = bs.select("small")
list_authors = []
for author in authors:
author_text = author.text
list_authors.append(author_text) # 获取这10个名言的 标签
divs = bs.select("div.tags")
list_tags = []
for div in divs:
tag_text = div.select("a.tag")
tag_list = [ tag_a.text for tag_a in tag_text]
list_tags.append(",".join(tag_list)) #结果汇总
results = []
for i in range(len(list_quotes)):
results.append("\t".join([list_quotes[i],list_authors[i],list_tags[i]])) for result in results:
print(result)
Python学习之路 (五)爬虫(四)正则表示式爬去名言网的更多相关文章
- python学习之路 五:函数式编程
本节重点 掌握函数的作用.语法 掌握作用域.全局变量与局部变量知识 掌握函数名称空间.闭包 一.函数编程基础知识 1.基本定义 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数 ...
- python学习之路网络编程篇(第四篇)
python学习之路网络编程篇(第四篇) 内容待补充
- python学习之路------你想要的都在这里了
python学习之路------你想要的都在这里了 (根据自己的学习进度后期不断更新哟!!!) 一.python基础 1.python基础--python基本知识.七大数据类型等 2.python基础 ...
- python学习之路-day2-pyth基础2
一. 模块初识 Python的强大之处在于他有非常丰富和强大的标准库和第三方库,第三方库存放位置:site-packages sys模块简介 导入模块 import sys 3 sys模 ...
- Python学习之路-Day1-Python基础
学习python的过程: 在茫茫的编程语言中我选择了python,因为感觉python很强大,能用到很多领域.我自己也学过一些编程语言,比如:C,java,php,html,css等.但是我感觉自己都 ...
- Python学习之路【第一篇】-Python简介和基础入门
1.Python简介 1.1 Python是什么 相信混迹IT界的很多朋友都知道,Python是近年来最火的一个热点,没有之一.从性质上来讲它和我们熟知的C.java.php等没有什么本质的区别,也是 ...
- Python学习之路【目录】
本系列博文包含 Python基础.前端开发.Web框架.缓存以及队列等,希望可以给正在学习编程的童鞋提供一点帮助!!! 目录: Python学习[第一篇]python简介 Python学习[第二篇]p ...
- python学习心得第五章
python学习心得第五章 1.冒泡排序: 冒泡是一种基础的算法,通过这算法可以将一堆值进行有效的排列,可以是从大到小,可以从小到大,条件是任意给出的. 冒泡的原理: 将需要比较的数(n个)有序的两个 ...
- Python学习笔记(五)
Python学习笔记(五): 文件操作 另一种文件打开方式-with 作业-三级菜单高大上版 1. 知识点 能调用方法的一定是对象 涉及文件的三个过程:打开-操作-关闭 python3中一个汉字就是一 ...
随机推荐
- mybatis-plus之Mapper CRUD接口和 Service CRUD 接口
中文官网链接: https://mp.baomidou.com/guide/crud-interface.html
- spring事务注解失效问题
问题描述: 由于工作需要,需要在spring中配置两个数据源,有一天突然发现@Transactional注解失效 环境框架: springmvc+spring+spring jdbcTemplate ...
- Windows下Sqlplus中显示乱码
set NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK 如果想显示英文 Set nls_lang=american_america.zhs16gbk 注意,前提是 ...
- sys模块 常用函数
sys模块是和python解释器打交道的 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) s ...
- HTML5扩展之微数据与丰富网页摘要——张鑫旭
一.微数据是? 一个页面的内容,例如人物.事件或评论不仅要给用户看,还要让机器可识别.而目前机器智能程度有限,要让其知会特定内容含义,我们需要使用规定的标签.属性名以及特定用法等.举个简单例子,我们使 ...
- java.lang.NoSuchMethodError 报500
1. 概述 mvc项目 接口报500 localhost 错误日志 07-Jan-2019 17:12:43.664 SEVERE [catalina-exec-21] org.apache.cata ...
- Django之WSGI浅谈
一.什么是Web框架 框架,即framework,特指为解决一个开放性问题而设计的具有一定约束性的支撑结构,使用框架可以帮你快速开发特定的系统. 浏览器与服务器之间发起HTTP请求: 1.浏览器发送一 ...
- SSRS 报表开发小技巧
说明: 开发工具为: SQL Server Data Tools (英文版) 开发环境为: SQL Server 2012 (英文版) 一. 饼图数据外部显示 首先我们来看3张效果图: 内部 ...
- opencv3.2.0形态学滤波之腐蚀
/* 腐蚀(erode)含义: 腐蚀和膨胀是相反的一对操作,所以腐蚀就是求局部最小值的操作,腐蚀操作使原图中 国的高亮部分被腐蚀,效果图比原图有更小的高亮的区域. 腐蚀函数原型API及参数同膨胀相同 ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...