基于GoogLeNet的不同花分类微调训练案例
import tensorflow as tf
from tensorflow.contrib.slim import nets
slim = tf.contrib.slim
import numpy as np
/root/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
class GoogLeNet(object):
def __init__(self, lr, batch_size, iter_num):
self.lr = lr # 学习率
self.batch_size = batch_size
self.iter_num = iter_num # 总共训练多少次
tf.reset_default_graph() # 重置图。有时候大家运行程序时候会提示某某tensor已经被构造。这是因为之前创建的图还在,然后重新运行一遍代码又创建了一个新图。可以在这里加一句tf.reset_default_graph()
self.X = tf.placeholder(tf.float32, [None, 224, 224, 3])
self.y = tf.placeholder(tf.float32, [None, 17]) # 17flowersu数据集有17个类
self.dropRate = tf.placeholder(tf.float32)
with slim.arg_scope(nets.inception.inception_v1_arg_scope()):
net, endpoints = nets.inception.inception_v1(self.X, num_classes=1001)
# 在这里,我们直接使用预置的模型。
net = endpoints['Mixed_5c']
net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
net = tf.reshape(net , [-1, 1024])
# 下面这些,大家应该非常熟悉了,和MNIST的一样的
net = tf.nn.dropout(net, self.dropRate)
logits = tf.layers.dense(net, 17, use_bias=True,
kernel_initializer=tf.constant_initializer(0),
bias_initializer=tf.constant_initializer(0))
self.logits = logits
self.loss = tf.losses.softmax_cross_entropy(onehot_labels=self.y, logits=logits)
self.train_step = tf.train.GradientDescentOptimizer(self.lr).minimize(self.loss)
# 用于模型训练
self.correct_prediction = tf.equal(tf.argmax(self.y, axis=1), tf.argmax(logits, axis=1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_prediction, tf.float32))
# 用于保存训练好的模型
self.saver = tf.train.Saver()
summary_loss = tf.summary.scalar('loss', self.loss)
summary_accuracy = tf.summary.scalar('accuracy', self.accuracy)
self.merged_summary_op = tf.summary.merge_all()
def read_image_label_list(self, name_list):
# 读取图像文件和标注列表
img_list=[]
label_list=[]
with open(name_list) as fr:
for line in fr.readlines():
imgIndex = int(line.strip())
imgLabel = int(imgIndex / 80)
imgPath = 'data/jpg/image_%04d.jpg' % imgIndex
img_list.append(imgPath)
label_list.append(imgLabel)
return img_list, label_list
def read_file(self, name_list):
image_list, label_list = self.read_image_label_list(name_list)
imagepaths, labels = tf.train.slice_input_producer([image_list, label_list], shuffle=True)
image = tf.read_file(imagepaths)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize_images(image, [224, 224])
image = tf.image.random_brightness(image, 15)
image = tf.image.random_flip_left_right(image)
image = (image * 1.0 / 127.5 - 1)
label = tf.one_hot(labels, 17)
X, Y = tf.train.batch([image, label], batch_size=self.batch_size, num_threads=2, capacity=self.batch_size*4)
return X, Y
def train(self):
training_images, training_labels = self.read_file('trn1.txt')
test_images, test_labels = self.read_file('val1.txt')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
variables_to_restore = slim.get_variables_to_restore()
init_fn = slim.assign_from_checkpoint_fn(r'pre_trained/inception_v1.ckpt',
variables_to_restore,
ignore_missing_vars=True)
init_fn(sess)
summary_writer = tf.summary.FileWriter('log/train_base', sess.graph)
summary_writer_test = tf.summary.FileWriter('log/test_base')
for i in range(self.iter_num):
tf.local_variables_initializer().run()
images, labels = sess.run([training_images, training_labels])
feed_dict = {self.dropRate: 0.5,
self.X :images,
self.y :labels}
loss, _ = sess.run([self.loss, self.train_step],
feed_dict=feed_dict) # 每调用一次sess.run,就像拧开水管一样,所有self.loss和self.train_step涉及到的运算都会被调用一次。
if i%10 ==0:
images, labels = sess.run([training_images, training_labels])
train_accuracy, summary_str = sess.run([self.accuracy,self.merged_summary_op], feed_dict={self.X: images, self.y: labels, self.dropRate: 1.}) # 把训练集数据装填进去
summary_writer.add_summary(summary_str, i)
images, labels = sess.run([test_images, test_labels])
test_accuracy, summary_str = sess.run([self.accuracy,self.merged_summary_op], feed_dict={self.X: images, self.y: labels, self.dropRate: 1.}) # 把测试集数据装填进去
summary_writer_test.add_summary(summary_str, i)
print ('iter\t%i\tloss\t%f\ttrain_accuracy\t%f\ttest_accuracy\t%f' % (i,loss,train_accuracy, test_accuracy))
self.saver.save(sess, 'model/flowerModel') # 保存模型
summary_writer.flush()
summary_writer_test.flush()
coord.request_stop()
coord.join(threads)
def test(self):
test_images, test_labels = self.read_file('tst1.txt')
with tf.Session() as sess:
self.saver.restore(sess, 'model/flowerModel')
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
Accuracy = []
for i in range(int(340/self.batch_size) + 1):
images, labels = sess.run([test_images, test_labels])
test_accuracy = sess.run(self.accuracy, feed_dict={self.X: images, self.y: labels, self.dropRate: 1.}) # 把测试集数据装填进去
Accuracy.append(test_accuracy)
print('==' * 15)
print( 'Test Accuracy: ', np.mean(np.array(Accuracy)) )
coord.request_stop()
coord.join(threads)
model = GoogLeNet(0.1, 50, 100)
model.train()
model.test()
WARNING:tensorflow:From <ipython-input-2-7ce60d3cb483>:18: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
WARNING:tensorflow:Variable dense/kernel missing in checkpoint pre_trained/inception_v1.ckpt
WARNING:tensorflow:Variable dense/bias missing in checkpoint pre_trained/inception_v1.ckpt
INFO:tensorflow:Restoring parameters from pre_trained/inception_v1.ckpt
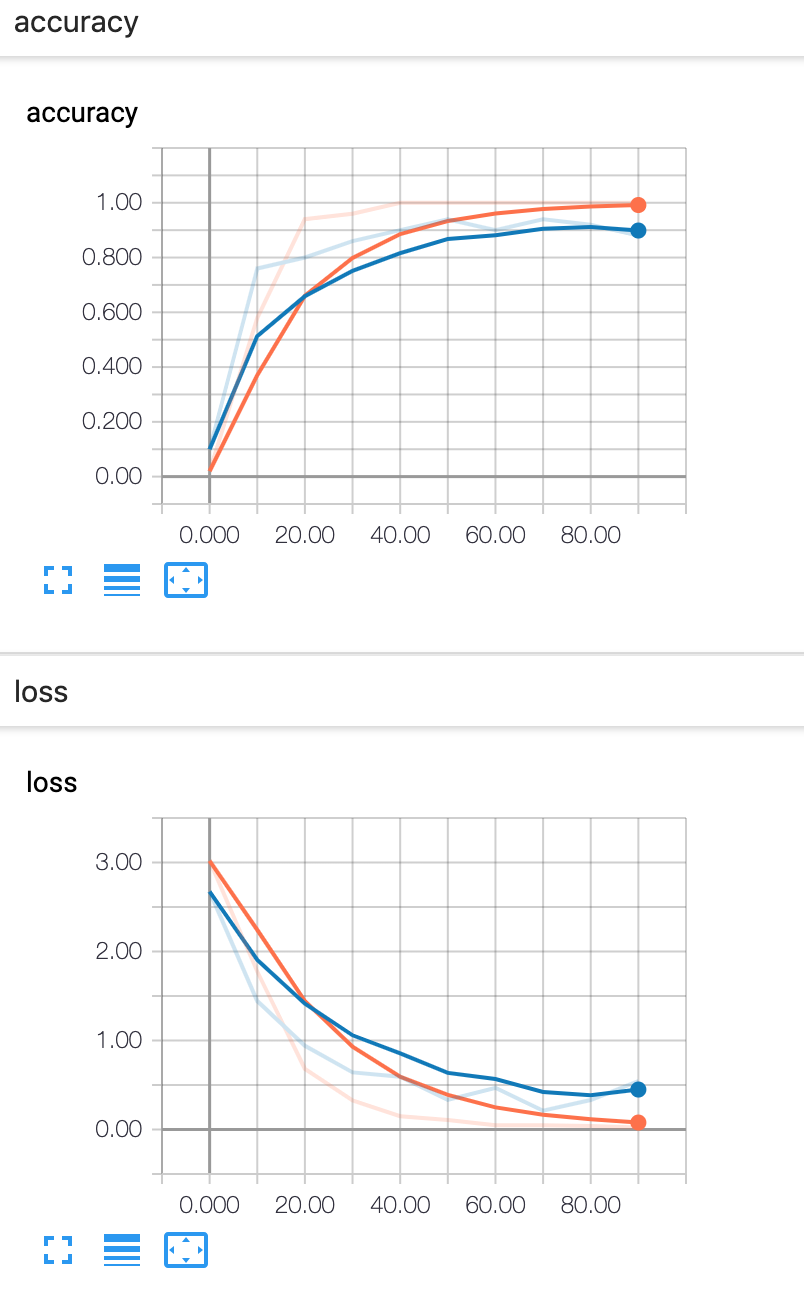
iter 0 loss 2.833214 train_accuracy 0.020000 test_accuracy 0.100000
iter 10 loss 1.716118 train_accuracy 0.580000 test_accuracy 0.760000
iter 20 loss 0.940882 train_accuracy 0.940000 test_accuracy 0.800000
iter 30 loss 0.329169 train_accuracy 0.960000 test_accuracy 0.860000
iter 40 loss 0.229579 train_accuracy 1.000000 test_accuracy 0.900000
iter 50 loss 0.096816 train_accuracy 1.000000 test_accuracy 0.940000
iter 60 loss 0.138667 train_accuracy 1.000000 test_accuracy 0.900000
iter 70 loss 0.133150 train_accuracy 1.000000 test_accuracy 0.940000
iter 80 loss 0.048020 train_accuracy 1.000000 test_accuracy 0.920000
iter 90 loss 0.057278 train_accuracy 1.000000 test_accuracy 0.880000
INFO:tensorflow:Restoring parameters from model/flowerModel
==============================
Test Accuracy: 0.94285715
基于GoogLeNet的不同花分类微调训练案例的更多相关文章
- 基于Spark Mllib的文本分类
基于Spark Mllib的文本分类 文本分类是一个典型的机器学习问题,其主要目标是通过对已有语料库文本数据训练得到分类模型,进而对新文本进行类别标签的预测.这在很多领域都有现实的应用场景,如新闻网站 ...
- matlab 基于 libsvm工具箱的svm分类遇到的问题与解决
最近在做基于无线感知的身份识别这个工作,在后期数据处理阶段,需要使用二分类的方法进行训练模型.本身使用matlab做,所以看了一下网上很多都是使用libsvm这个工具箱,就去下载了,既然用到了想着就把 ...
- NLP之基于TextCNN的文本情感分类
TextCNN @ 目录 TextCNN 1.理论 1.1 基础概念 最大汇聚(池化)层: 1.2 textCNN模型结构 2.实验 2.1 实验步骤 2.2 算法模型 1.理论 1.1 基础概念 在 ...
- Windows下mnist数据集caffemodel分类模型训练及测试
1. MNIST数据集介绍 MNIST是一个手写数字数据库,样本收集的是美国中学生手写样本,比较符合实际情况,大体上样本是这样的: MNIST数据库有以下特性: 包含了60000个训练样本集和1000 ...
- 【ALB技术笔记】基于多线程方式的串行通信接口数据接收案例
基于多线程方式的串行通信接口数据接收案例 广东职业技术技术学院 欧浩源 1.案例背景 在本博客的<[CC2530入门教程-06]CC2530的ADC工作原理与应用>中实现了电压数据采集的 ...
- 【ALB学习笔记】基于事件触发方式的串行通信接口数据接收案例
基于事件触发方式的串行通信接口数据接收案例 广东职业技术学院 欧浩源 一.案例背景 之前写过一篇<基于多线程方式的串行通信接口数据接收案例>的博文,讨论了采用轮询方式接收串口数据的情况. ...
- 【ALB学习笔记】基于多线程方式的串行通信接口数据接收案例
基于多线程方式的串行通信接口数据接收案例 广东职业技术技术学院 欧浩源 1.案例背景 在本博客的<[CC2530入门教程-06]CC2530的ADC工作原理与应用>中实现了电压数据采集的 ...
- Httpd服务进阶知识-基于Apache Modele的LAMP架构之WordPress案例
Httpd服务进阶知识-基于Apache Modele的LAMP架构之WordPress案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装依赖包及数据库授权 博主推荐阅读 ...
- Httpd服务进阶知识-基于Apache Modele的LAMP架构之PhpMyAdmin案例
Httpd服务进阶知识-基于Apache Modele的LAMP架构之PhpMyAdmin案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.常见LAMP应用 PhpMyAdm ...
随机推荐
- ASP.NET MVC Form表单验证与Authorize特性
一.Form表单验证 1.基本概念 表单验证是一个基于票据(ticket-based)[也称为基于令牌(token-based)]的系统.当用户登录系统以后,会得到一个包含基于用户信息的票据(tick ...
- expect 安装使用
expect 命令相当于crt远程连接,可用于脚本化实现多服务器巡检功能. 一.expect 命令安装: 1.rpm 文件下载:百度云链接:http://pan.baidu.com/s/1sl1wSU ...
- Android-Kotlin-区间与for&List&Map简单使用
区间与for: package cn.kotlin.kotlin_base04 /** * 区间与for */ fun main(args: Array<String>) { /** * ...
- XML语法随记
1.特殊字符的转义 & ---- & < ---- < > ---- > " ---- " ' ----- &ap ...
- netcore的Session使用小记
之前说过,core需要什么功能就添加并使用什么中间件 照例,在Startup.cs的ConfigureServices方法中添加services.AddSession();再在Configure方法中 ...
- 百度小程序button去掉默认边框
百度小程序button去掉默认边框: button::after{ border:none; }
- solr 加载 停用/扩展词典
startup.bat 停止词典的效果
- python项目实现配置统一管理的方法
一个比较大的项目总是会涉及到很多的参数,最好的方法就是在一个地方统一管理这些参数.最近看了不少的python项目,总结了两种很有意思的配置管理方法. 第一种 基于easydict实现的配置管理 首先需 ...
- 对"某V皮"N服务器节点的一次后渗透测试
i春秋作家:jasonx 前言:由于这个VPN节点服务器是之前拿到的,一直没时间做进一步渗透,昨天看到我蛋总表哥发红包,然后我运气爆表抢了个运气王,再加上好久没发文章了,所以就抽空测试下咯. 0×01 ...
- Java - 获取帮助信息
在线开发文档 Java SE 8 Java SE 8 Developer Guides Java SE 8 API Specification Java API Specifications 离线开发 ...