快速制作规则及获取规则提取器API
1. 引言
前面文章的测试案例都用到了集搜客Gooseeker提供的规则提取器,在网页抓取工作中,调试正则表达式或者XPath都是特别繁琐的,耗时耗力,工作枯燥,如果有一个工具可以快速生成规则,而且可以可视化的即时验证,就能把程序员解放出来,投入到创造性工作中。
之前文章所用的例子中的规则都是固定的,如何自定义规则再结合提取器提取我们想要的网页内容呢?对于程序员来说,理想的目标是掌握一个通用的爬虫框架,每增加一个新目标网站就要跟着改代码,这显然不是好工作模式。这就是本篇文章的主要内容了,本文使用一个案例说明怎样将新定义的采集规则融入到爬虫框架中。也就是用可视化的集搜客GooSeeker爬虫软件针对亚马逊图书商品页做一个采集规则,并结合规则提取器抓取网页内容。
2. 安装集搜客GooSeeker爬虫软件
2.1. 前期准备
进入集搜客官网产品页面,下载对应版本。我的电脑上已经安装了Firefox 38,所以这里只需下载爬虫。
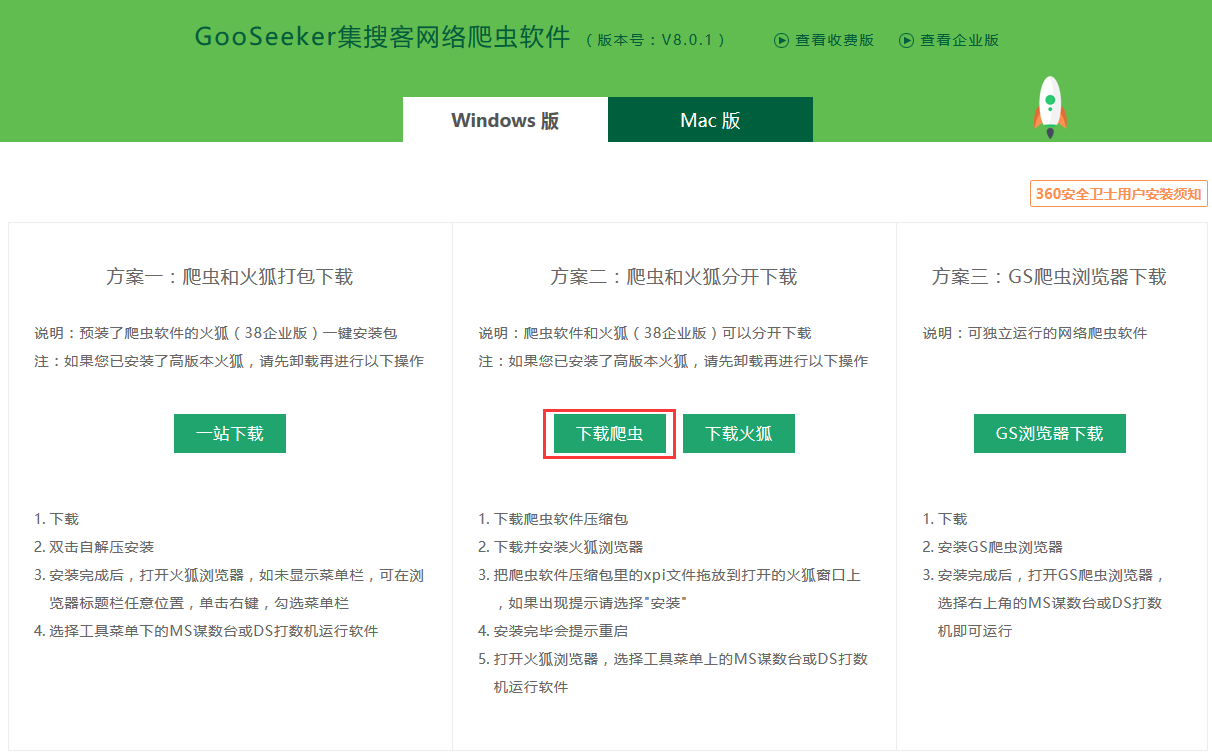
2.2 安装爬虫
打开Firefox –> 点击菜单工具 –> 附加组件 –> 点击右上角附加组件的工具 –> 选择从文件安装附加组件 -> 选中下载好的爬虫xpi文件 –> 立即安装
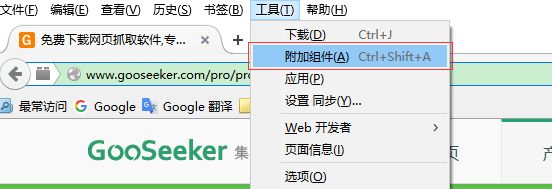
下一步

下一步

3. 开始制作抓取规则
3.1 运行规则定义软件
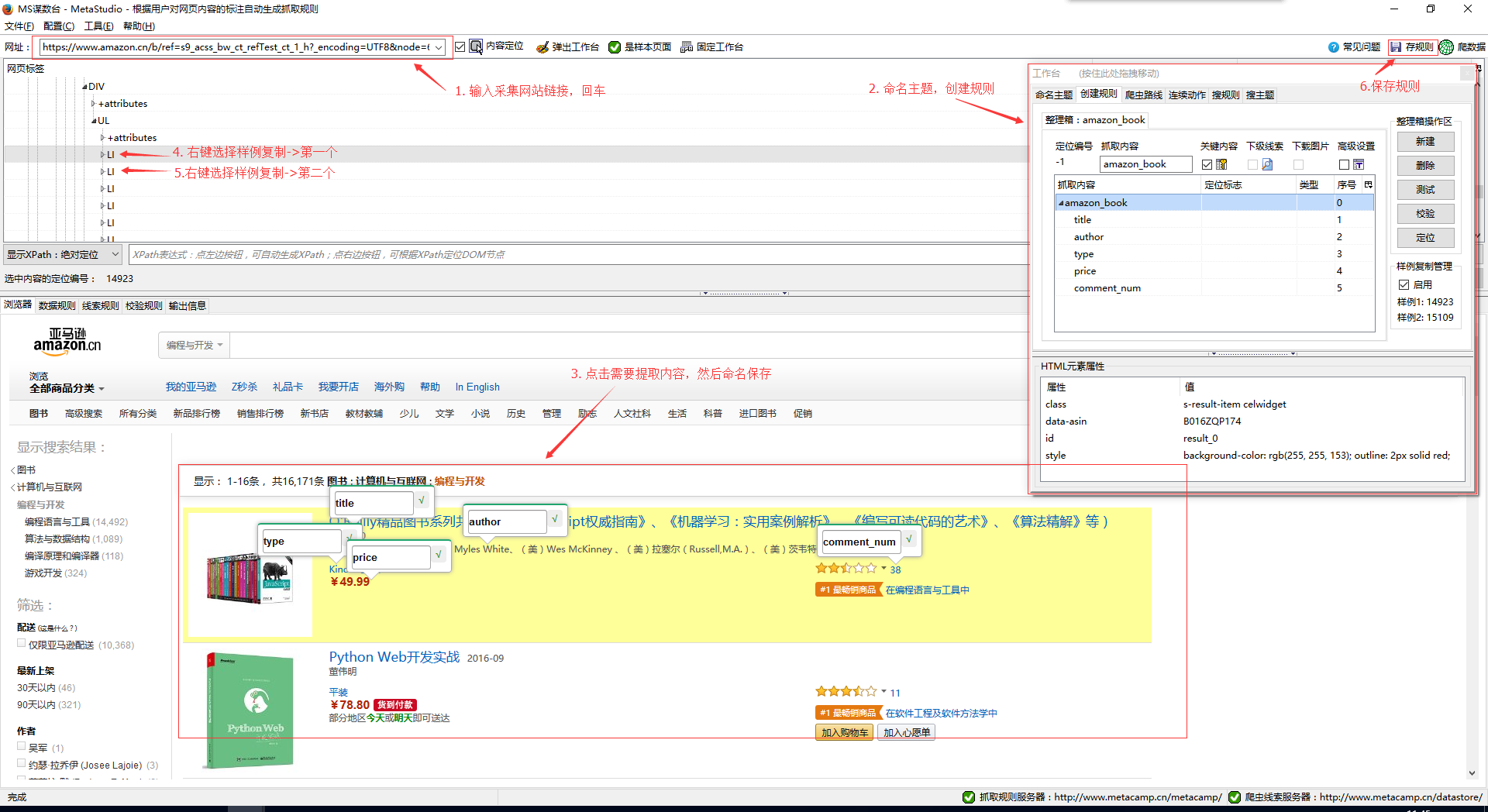
点击浏览器菜单:工具-> MS谋数台 弹出MS谋数台窗口。
3.2 做规则
在网址栏输入我们要采集的网站链接,然后回车。当页面加载完成后,在工作台页面依次操作:命名主题名 -> 创建规则 -> 新建整理箱 -> 在浏览器菜单选择抓取内容,命名后保存。
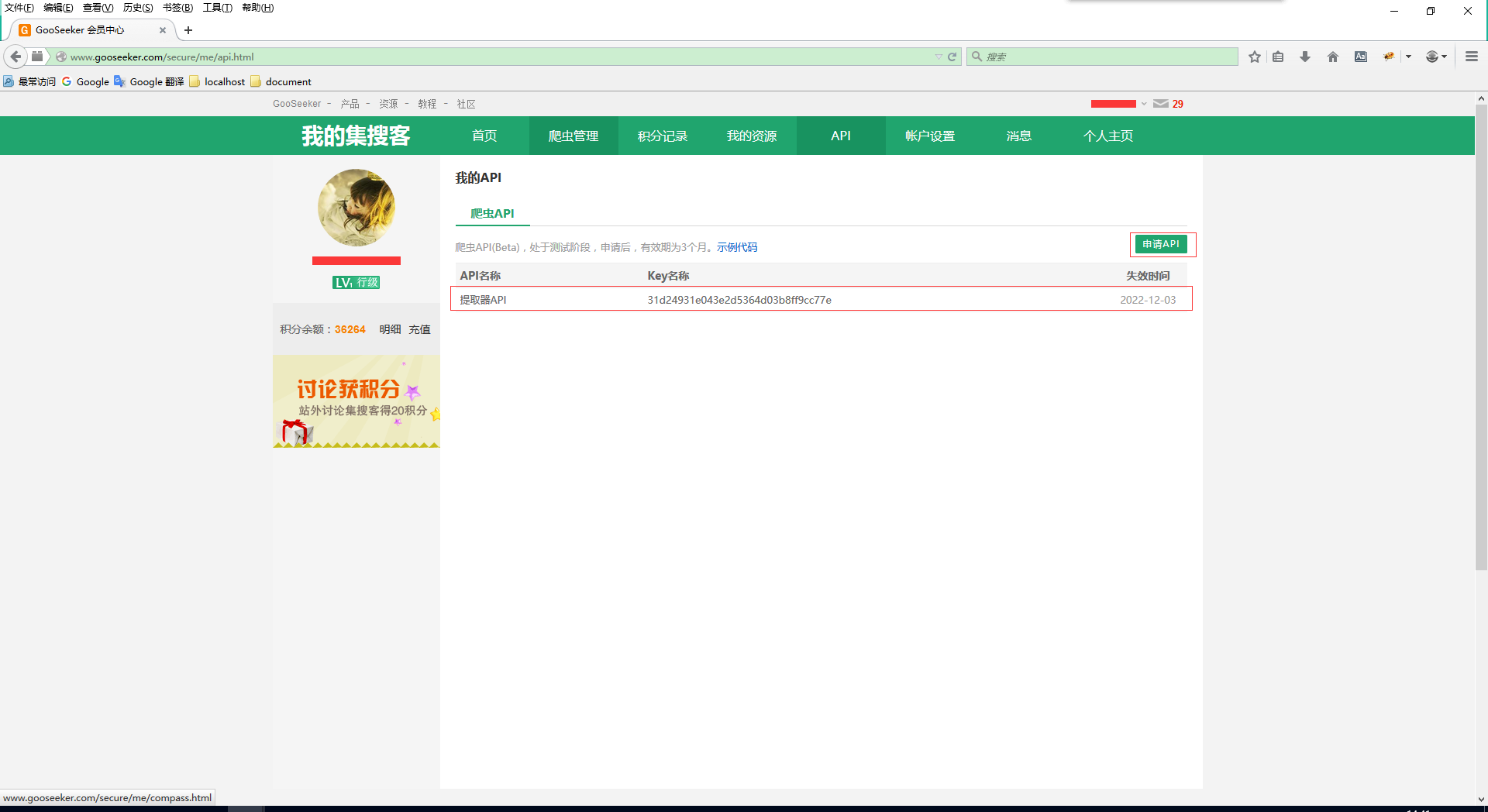
4. 申请规则提取器API KEY
打开集搜客Gooseeke官网,注册登陆后进入会员中心 -> API -> 申请API
5. 结合提取器API敲一个爬虫程序
5.1 引入Gooseeker规则提取器模块gooseeker.py
(下载地址: https://github.com/FullerHua/gooseeker/tree/master/core), 选择一个存放目录,这里为E:\demo\gooseeker.py
5.2 与gooseeker.py同级创建一个.py后缀文件
如这里为E:\Demo\third.py,再以记事本打开,敲入代码: 注释:代码中的31d24931e043e2d5364d03b8ff9cc77e 就是API KEY,用你申请的代替;amazon_book_pc 是规则的主题名,也用你的主题名代替
# -*- coding: utf-8 -*-
# 使用GsExtractor类的示例程序
# 以webdriver驱动Firefox采集亚马逊商品列表
# xslt保存在xslt_bbs.xml中
# 采集结果保存在third文件夹中
import os
import time
from lxml import etree
from selenium import webdriver
from gooseeker import GsExtractor # 引用提取器
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "amazon_book_pc") # 设置xslt抓取规则 # 创建存储结果的目录
current_path = os.getcwd()
res_path = current_path + "/third-result"
if os.path.exists(res_path):
pass
else:
os.mkdir(res_path) # 驱动火狐
driver = webdriver.Firefox()
url = "https://www.amazon.cn/s/ref=sr_pg_1?rh=n%3A658390051%2Cn%3A!658391051%2Cn%3A658414051%2Cn%3A658810051&page=1&ie=UTF8&qid=1476258544"
driver.get(url)
time.sleep(2) # 获取总页码
total_page = driver.find_element_by_xpath("//*[@class='pagnDisabled']").text
total_page = int(total_page) + 1 # 用简单循环加载下一页链接(也可以定位到下一页按钮,循环点击)
for page in range(1,total_page):
# 获取网页内容
content = driver.page_source.encode('utf-8') # 获取docment
doc = etree.HTML(content)
# 调用extract方法提取所需内容
result = bbsExtra.extract(doc) # 保存结果
file_path = res_path + "/page-" + str(page) + ".xml"
open(file_path,"wb").write(result)
print('第' + str(page) + '页采集完毕,文件:' + file_path) # 加载下一页
if page < total_page - 1:
url = "https://www.amazon.cn/s/ref=sr_pg_" + str(page + 1) + "?rh=n%3A658390051%2Cn%3A!658391051%2Cn%3A658414051%2Cn%3A658810051&page=" + str(page + 1) + "&ie=UTF8&qid=1476258544"
driver.get(url)
time.sleep(2)
print("~~~采集完成~~~")
driver.quit()
5.3 执行third.py
打开命令提示窗口,进入third.py文件所在目录,输入命令 :python third.py 回车

5.4 查看结果文件
进入third.py文件所在目录,找到名称为result-2的文件夹然后打开
6. 总结
制作规则时,由于定位选择的是偏好id,而采集网址的第二页对应页面元素的id属性有变化,所以第二页内容提取出现了问题,然后对照了一下网页元素发现class是一样的,果断将定位改为了偏好class,这下提取就正常了。下一篇《在Python3.5下安装和测试Scrapy爬网站》简单介绍Scrapy的使用方法。
7. 集搜客GooSeeker开源代码下载源
快速制作规则及获取规则提取器API的更多相关文章
- 爬虫Scrapy框架-Crawlspider链接提取器与规则解析器
Crawlspider 一:Crawlspider简介 CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著 ...
- JMeter学习-011-JMeter 后置处理器实例之 - 正则表达式提取器(三)多参数获取进阶引用篇
前两篇文章分表讲述了 后置处理器 - 正则表达式提取器概述及简单实例.多参数获取,相应博文敬请参阅 简单实例.多参数获取. 此文主要讲述如何引用正则表达式提取器获取的数据信息.其实,正则表达式提取器获 ...
- JMeter学习-009-JMeter 后置处理器实例之 - 正则表达式提取器(二)多参数获取
前文简述了通过后置处理器 - 正则表达式提取器 获取 HTTP请求 响应结果中的特定数据,未看过的亲,敬请参阅 JMeter学习-008-JMeter 后置处理器实例之 - 正则表达式提取器(一). ...
- Jmeter-正则表达式提取器获取token-小实例
步骤一:在需要获取token的接口上,添加正则表达式提取器 说明: (1) Apply to:应用范围 Main sample and sub-samples:匹配范围包括当前父取样器并覆盖至子取样器 ...
- Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作 ...
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- JMeter 后置处理器之正则表达式提取器详解
后置处理器之正则表达式提取器详解 by:授客 QQ:1033553122 1. 添加正则表达式提取器 右键线程组->添加->后置处理器->正则表达式提取器 2. 提取器配置介绍 ...
- Jmeter正则表达式提取器(转载)
转载自 http://blog.csdn.net/qq_35885203 使用jmeter来测试时,经常会碰到需要上下文传输数据的情况,如登录后生成的token,在其他页面的操作,都需传入这个toke ...
- Jmeter--正则表达式提取器
正则提取器的一般使用场景是, 在我第二个请求参数中需要加入第一个请求的返回值, 此时通过正则提取器可以提取第一个请求返回值中指定的字段信息并赋值, 在第二个请求参数中直接引用该变量即可 jmeter的 ...
随机推荐
- 正式学习react(二)
今天把上一篇还没学习完的 webpack部分学习完: 之前有说过关于css的webpack使用.我们讲了 ExtractTextPlugin 来单独管理css讲了module.loaders下关于 c ...
- iOS -多字体混合
label 加下划线 UILabel *label = [[UILabel alloc] initWithFrame:CGRectMake(0, 100, 300, 100)]; label.b ...
- sort命令总结
功能:排序 语法:sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--ver ...
- 安装Oracle10g on RedHat as 4 64bit(摘)
一.安装前的配置 1.修改RH版本 vi /etc/redhat-release Red Hat Enterprise Linux AS release 3 (Taroon Update 3) 2. ...
- cf A. Jeff and Digits
http://codeforces.com/contest/352/problem/A #include <cstdio> #include <cstring> #includ ...
- WebDriver使用IE浏览器
开始使用Selenium2之后就一直在用FireFox,因为文章上都说webdriver对firefox支持的最好,同时也很好上手,试了一下就可用了,也就没再用其他浏览器,不过最近遇到了一个问题,是我 ...
- POJ3260:The Fewest Coins(混合背包)
Description Farmer John has gone to town to buy some farm supplies. Being a very efficient man, he a ...
- 由查找session IP 展开---函数、触发器、包
由查找session IP 展开---函数.触发器.包 一.userenv函数.sys_context函数 --查看当前client会话的session IP信息 SQL>select sys_ ...
- Qt Assistant 的配置文件qhp--->qch 和qhcp--->qhc详解与生成
Qt Assistant 这个exe文件可以被我们利用到我们自己的程序为我们添加help,是一个文档浏览器,它的搜索功能,还有最主要的就是他可以让客户自己定义自己索要显示的文档,也就是qch文档. ...
- 仿桌面通知pnotify插件
在做网站的时候,alert弹出框是非常常见的情形.但是,有些情况下,弹框对用户来说是并不友好的.调研了几个其他的提示插件了,发现pnotify比较好用,可配置性也高. 使用示例: <!DOCTY ...