Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景
在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作中。
2. 解决方案
为了解决这个问题,我们把影响通用性和工作效率的提取器隔离出来,描述了如下的数据处理流程图:

图中“可插拔提取器”必须很强的模块化,那么关键的接口有:
- 标准化的输入:以标准的HTML DOM对象为输入
- 标准化的内容提取:使用标准的xslt模板提取网页内容
- 标准化的输出:以标准的XML格式输出从网页上提取到的内容
- 明确的提取器插拔接口:提取器是一个明确定义的类,通过类方法与爬虫引擎模块交互
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义成一个类: gsExtractor
python源代码文件及其说明文档请从github 下载
使用模式是这样的:
- 实例化一个gsExtractor对象
- 为这个对象设定xslt提取器,相当于把这个对象配置好(使用三类setXXX()方法)
- 把html dom输入给它,就能获得xml输出(使用extract()方法)
下面是这个gsExtractor类的源代码
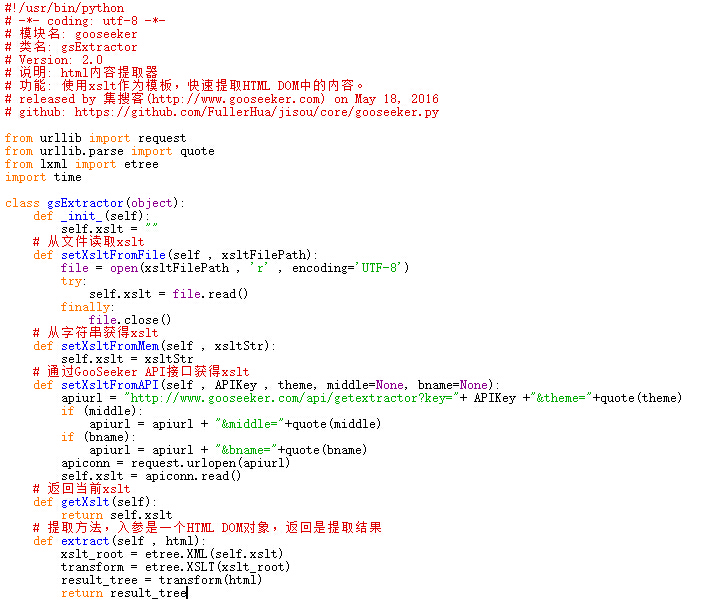
4. 用法示例
下面是一个示例程序,演示怎样使用gsExtractor类提取GooSeeker官网的bbs帖子列表。本示例有如下特征:
- 提取器所用的xslt模板提前放在文件中:xslt_bbs.xml
- 仅作为示例,实际使用场景中,xslt来源有多个,最主流的来源是GooSeeker平台上的api
- 在控制台界面上打印出提取结果
下面是源代码,都可从 github 下载

提取结果如下图所示:

5. 接下来阅读
本文已经说明了提取器的价值和用法,但是没有说怎样生成它,只有快速生成提取器才能达到节省开发者时间的目的,这个问题将在其他文章讲解,请看《Python使用xslt提取网页数据》。
6. 集搜客GooSeeker开源代码下载源
1. GooSeeker开源Python网络爬虫GitHub源
7. 文档修改历史
2016-05-27:V2.0,增补项目背景介绍和价值说明
2016-05-27:V2.1,实现了提取器类的从GooSeeker API接口获取xslt的方法
2016-05-29:V2.2,增加第六章:源代码下载源,并更换github源的网址
2016-06-03:V2.3,提取器代码更新为2.0。支持同一主题下多规则或多整理箱的情况,通过API方式获取xslt时可以传入参数“规则编号”和“整理箱名称”
Python即时网络爬虫项目: 内容提取器的定义的更多相关文章
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python即时网络爬虫:API说明
API说明——下载gsExtractor内容提取器 1,接口名称 下载内容提取器 2,接口说明 如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪 ...
- API例子:用Java/JavaScript下载内容提取器
1,引言 本文讲解怎样用Java和JavaScript使用 GooSeeker API 接口下载内容提取器,这是一个示例程序.什么是内容提取器?为什么用这种方式?源自Python即时网络爬虫开源项目: ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- 用Python写网络爬虫 第二版
书籍介绍 书名:用 Python 写网络爬虫(第2版) 内容简介:本书包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据 ...
- Python简单网络爬虫实战—下载论文名称,作者信息(下)
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的 1.从sou ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- Python 3网络爬虫开发实战》中文PDF+源代码+书籍软件包
Python 3网络爬虫开发实战>中文PDF+源代码+书籍软件包 下载:正在上传请稍后... 本书书籍软件包为本人原创,在这个时间就是金钱的时代,有些软件下起来是很麻烦的,真的可以为你们节省很多 ...
随机推荐
- select2使用详解
官网: https://select2.github.io/examples.html 引用: <link href="~/Scripts/select2/select2.css&qu ...
- awk之基本信息
awk 利用RS来分割文本,分割后形成一条一条的record awk 利用FS来分割record,分割后形成一段一段的field field由一串一串的字符串构成 默认的RS是换行符 默认的FS是空格 ...
- The kth great number(优先队列)
The kth great number Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65768/65768 K (Java/Oth ...
- 十、装饰(Decorator)模式 --结构模式(Structural Pattern)
装饰(Decorator)模式又名包装(Wrapper)模式[GOF95].装饰模式以对客户端透明的方 式扩展对象的功能,是继承关系的一个替代方案. 装饰模式类图: 类图说明: 抽象构件(Compon ...
- 大规模集群FTP代理(基于lvs的vsftpd网络负载均衡方案部署(PASV))
[目的] 在日常工作中,我们经常需要在某服务器上开FTP(Server)服务.但就是这么简单的事情通常也会变得很复杂,原因如下:1.需要开通FTP的服务器没有公网IP地址:(即不能直接访问到)2.这样 ...
- Redis应用场景-整理
1. MySql+Memcached架构的问题 Memcached采用客户端-服务器的架构,客户端和服务器端的通讯使用自定义的协议标准,只要满足协议格式要求,客户端Library可以用任何语言实现. ...
- Linux下的摄影后期处理软件
由于喜欢摄影,在LInux上折腾,想找一款能代替lightroom的软件.发现darktable这款软件专业.于是就安装了. 以下是在Linux上安装darktable的instruction,需要添 ...
- Course Schedule 解答
Question There are a total of n courses you have to take, labeled from 0 to n - 1. Some courses may ...
- python多线程简单例子
python多线程简单例子 作者:vpoet mail:vpoet_sir@163.com import thread def childthread(threadid): print "I ...
- php php打乱数组二维数组、多维数组
php中的shuffle函数只能打乱一维数组,有什么办法快速便捷的打乱多维数组?手册上提供了 <?php function shuffle_assoc($list) { if (!is ...