Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景
在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作中。
2. 解决方案
为了解决这个问题,我们把影响通用性和工作效率的提取器隔离出来,描述了如下的数据处理流程图:

图中“可插拔提取器”必须很强的模块化,那么关键的接口有:
- 标准化的输入:以标准的HTML DOM对象为输入
- 标准化的内容提取:使用标准的xslt模板提取网页内容
- 标准化的输出:以标准的XML格式输出从网页上提取到的内容
- 明确的提取器插拔接口:提取器是一个明确定义的类,通过类方法与爬虫引擎模块交互
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义成一个类: gsExtractor
python源代码文件及其说明文档请从github 下载
使用模式是这样的:
- 实例化一个gsExtractor对象
- 为这个对象设定xslt提取器,相当于把这个对象配置好(使用三类setXXX()方法)
- 把html dom输入给它,就能获得xml输出(使用extract()方法)
下面是这个gsExtractor类的源代码
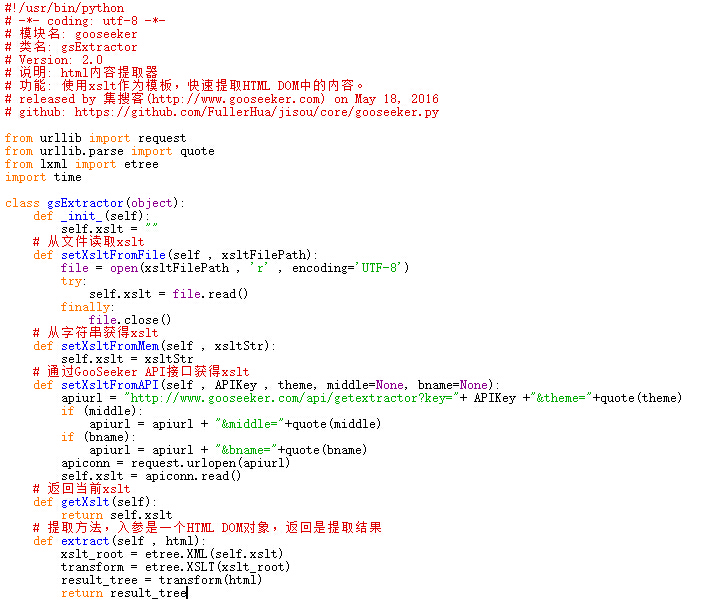
4. 用法示例
下面是一个示例程序,演示怎样使用gsExtractor类提取GooSeeker官网的bbs帖子列表。本示例有如下特征:
- 提取器所用的xslt模板提前放在文件中:xslt_bbs.xml
- 仅作为示例,实际使用场景中,xslt来源有多个,最主流的来源是GooSeeker平台上的api
- 在控制台界面上打印出提取结果
下面是源代码,都可从 github 下载

提取结果如下图所示:

5. 接下来阅读
本文已经说明了提取器的价值和用法,但是没有说怎样生成它,只有快速生成提取器才能达到节省开发者时间的目的,这个问题将在其他文章讲解,请看《Python使用xslt提取网页数据》。
6. 集搜客GooSeeker开源代码下载源
1. GooSeeker开源Python网络爬虫GitHub源
7. 文档修改历史
2016-05-27:V2.0,增补项目背景介绍和价值说明
2016-05-27:V2.1,实现了提取器类的从GooSeeker API接口获取xslt的方法
2016-05-29:V2.2,增加第六章:源代码下载源,并更换github源的网址
2016-06-03:V2.3,提取器代码更新为2.0。支持同一主题下多规则或多整理箱的情况,通过API方式获取xslt时可以传入参数“规则编号”和“整理箱名称”
Python即时网络爬虫项目: 内容提取器的定义的更多相关文章
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python即时网络爬虫:API说明
API说明——下载gsExtractor内容提取器 1,接口名称 下载内容提取器 2,接口说明 如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪 ...
- API例子:用Java/JavaScript下载内容提取器
1,引言 本文讲解怎样用Java和JavaScript使用 GooSeeker API 接口下载内容提取器,这是一个示例程序.什么是内容提取器?为什么用这种方式?源自Python即时网络爬虫开源项目: ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- 用Python写网络爬虫 第二版
书籍介绍 书名:用 Python 写网络爬虫(第2版) 内容简介:本书包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据 ...
- Python简单网络爬虫实战—下载论文名称,作者信息(下)
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的 1.从sou ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- Python 3网络爬虫开发实战》中文PDF+源代码+书籍软件包
Python 3网络爬虫开发实战>中文PDF+源代码+书籍软件包 下载:正在上传请稍后... 本书书籍软件包为本人原创,在这个时间就是金钱的时代,有些软件下起来是很麻烦的,真的可以为你们节省很多 ...
随机推荐
- Asp.Net通过SignalR实现IM即时通讯
前言:SignalR是一种针对H5中WebSocket的解决方案,可以实现在不支持H5的浏览器中实现IM 后端: step 1:通过NuGet安装SignalR step 2:新建一个类继承于Hub, ...
- EditText判断用户输入完成,然后进行操作解决方案
private Timer timer = new Timer(); private final long DELAY = 1000; // in ms EditText editTextStop = ...
- 解决onethink导出word后出现名字乱码的情况
这个问题让我纠结了好久最后终于在网上看到一篇文章讲解的还不错 http://www.oschina.net/question/142207_39393
- Knight Moves(BFS,走’日‘字)
Knight Moves Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tota ...
- c# vs2010 winfrom控件检测网络环境
写下以作备用,代码附上. public partial class UserControl1 : UserControl, IObjectSafety { //检测网络状态 [DllImport(&q ...
- Mysql基本类型(字符串类型)——mysql之二
转自: http://www.cnblogs.com/doit8791/archive/2012/05/28/2522556.html 1.varchar类型的变化 MySQL 数据库的varchar ...
- jQuery中的选择器《思维导图》
学习jQuery的课程中,我对jQuery中的选择器有了更深的认识,它的简洁写法,完美的兼容性,可靠的处理机制,都让我们省了很多事, 下面是我在学习过程中对jQuery选择器写的思维导图(全屏查看:& ...
- 基于spark的plsa实现
PLSA.py # coding:utf8 from pyspark import SparkContext from pyspark import RDD import numpy as np fr ...
- 认识SVN
TortoiseSVN 是 Subversion 版本控制系统的一个免费开源客户端,可以超越时间的管理文件和目录.文件保存在中央版本库,除了能记住文件和目录的每次修改以外,版本库非常像普通的文件 服务 ...
- A Simple Problem with Integers(100棵树状数组)
A Simple Problem with Integers Time Limit: 5000/1500 MS (Java/Others) Memory Limit: 32768/32768 K ...