基于yolo12进行深度学习的机动车车牌检测
视频演示
前言
大家好,我是Coding茶水间。
今天分享一个基于YOLOv12的深度学习项目:机动车车牌检测算法。
这个项目使用YOLOv12模型进行车牌检测和分割,支持图片和视频输入,并通过PyQt5构建了一个简洁的图形界面。
整个系统可以实时检测车牌位置,并在界面上显示原始图像和分割后的车牌区域,还支持保存结果。
项目概述
核心技术
- YOLOv12模型:Ultralytics库提供的YOLO系列最新版本,用于目标检测。模型训练后可以准确识别机动车车牌,包括传统车牌和新能源车牌。
- PyQt5:用于构建图形用户界面(GUI),界面简洁,包括选择图片/视频、分割检测和保存结果的功能。
- OpenCV:处理图像和视频帧,进行显示和保存。
- 数据集:使用了约1300张训练图像,包括不同角度、颜色、透明度和尺度变化的车牌图片,以增强模型鲁棒性。数据集分为训练集、验证集和测试集,每张图像有对应的标注文件。
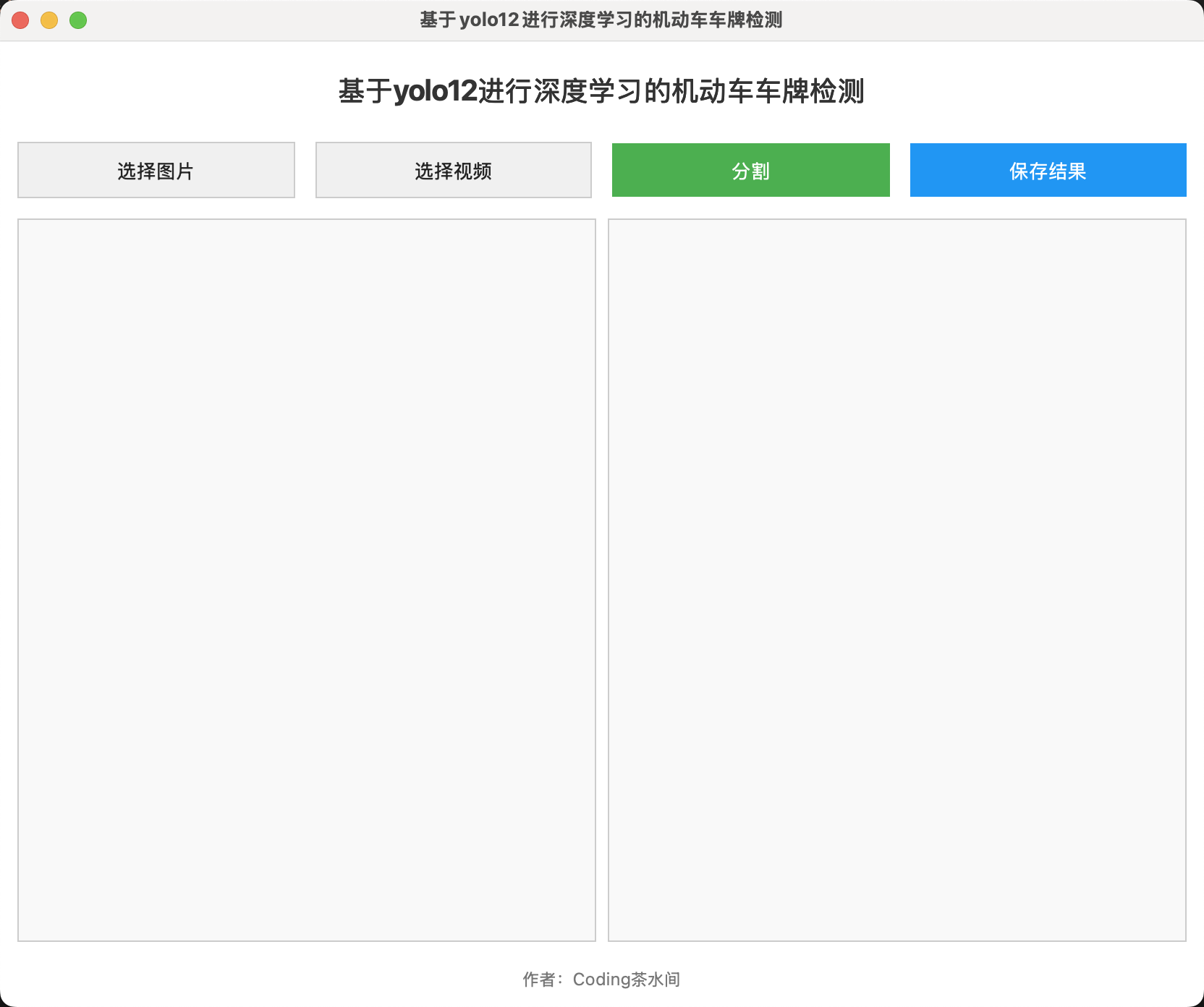
界面设计
界面布局如下:
- 顶部标题:显示项目名称。
- 按钮区域:四个按钮——“选择图片”、“选择视频”、“分割”、“保存结果”。
- 显示区域:左侧显示原始图像或视频帧,右侧显示分割后的车牌图像。
环境配置
运行本项目需要以下环境:
- Python 3.8+
- 安装依赖库:
text
pip install pyqt5 opencv-python ultralytics![]()
- 下载YOLOv12模型权重。
如果需要自己训练模型,还需准备车牌数据集(格式为YOLO标注:images和labels文件夹)。
代码实现
下面是完整的主程序代码(main.py)。代码使用PyQt5创建窗口,集成YOLO模型进行检测。
python
"""
版权所有 Coding茶水间。保留所有权利。
本代码仅限个人学习、研究之用,禁止用于任何商业用途。
未经许可,不得公开分发、复制、修改或用于盈利性项目。
"""
import sys
import cv2
from PyQt5.QtWidgets import QApplication, QMainWindow, QVBoxLayout, QHBoxLayout, QPushButton, QLabel, QFileDialog, QWidget, QMessageBox
from PyQt5.QtGui import QPixmap, QImage
from PyQt5.QtCore import Qt, QTimer
from ultralytics import YOLO
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("基于yolo12进行深度学习的机动车车牌检测")
self.setGeometry(100, 100, 800, 600)
self.setStyleSheet("background-color: white;")
# 主布局
self.main_widget = QWidget()
self.setCentralWidget(self.main_widget)
self.main_layout = QVBoxLayout()
self.main_widget.setLayout(self.main_layout)
# 标题
self.title_label = QLabel("基于yolo12进行深度学习的机动车车牌检测")
self.title_label.setStyleSheet("font-size: 20px; font-weight: bold; color: #333; margin-bottom: 10px; margin-top: 10px;")
self.title_label.setAlignment(Qt.AlignCenter)
self.main_layout.addWidget(self.title_label)
# 按钮区域
self.button_layout = QHBoxLayout()
self.main_layout.addLayout(self.button_layout)
self.select_image_btn = QPushButton("选择图片")
self.select_image_btn.setStyleSheet("QPushButton { background-color: #f0f0f0; border: 1px solid #ccc; padding: 10px; font-size: 14px; }")
self.button_layout.addWidget(self.select_image_btn)
self.select_video_btn = QPushButton("选择视频")
self.select_video_btn.setStyleSheet("QPushButton { background-color: #f0f0f0; border: 1px solid #ccc; padding: 10px; font-size: 14px; }")
self.button_layout.addWidget(self.select_video_btn)
self.process_btn = QPushButton("分割")
self.process_btn.setStyleSheet("QPushButton { background-color: #4CAF50; color: white; border: none; padding: 10px; font-size: 14px; }")
self.button_layout.addWidget(self.process_btn)
self.save_btn = QPushButton("保存结果")
self.save_btn.setStyleSheet("QPushButton { background-color: #2196F3; color: white; border: none; padding: 10px; font-size: 14px; }")
self.button_layout.addWidget(self.save_btn)
# 展示区域(固定尺寸)
self.display_layout = QHBoxLayout()
self.main_layout.addLayout(self.display_layout)
# 原始图像显示区域
self.original_display = QLabel()
self.original_display.setAlignment(Qt.AlignCenter)
self.original_display.setStyleSheet("border: 1px solid #ccc; background-color: #f9f9f9;")
self.original_display.setFixedSize(400, 500) # 固定展示区域尺寸
self.display_layout.addWidget(self.original_display)
# 分割后图像显示区域
self.segmented_display = QLabel()
self.segmented_display.setAlignment(Qt.AlignCenter)
self.segmented_display.setStyleSheet("border: 1px solid #ccc; background-color: #f9f9f9;")
self.segmented_display.setFixedSize(400, 500) # 固定展示区域尺寸
self.display_layout.addWidget(self.segmented_display)
# 作者信息(固定高度)
self.author_label = QLabel("作者:Coding茶水间")
self.author_label.setStyleSheet("font-size: 12px; color: #777; margin-top: 10px;")
self.author_label.setAlignment(Qt.AlignCenter)
self.main_layout.addWidget(self.author_label)
# 连接信号
self.select_image_btn.clicked.connect(self.select_image)
self.select_video_btn.clicked.connect(self.select_video)
self.process_btn.clicked.connect(self.process)
self.save_btn.clicked.connect(self.save_result)
# 创建定时器,控制帧率
self.video_timer = QTimer(self)
self.video_timer.timeout.connect(self.update_frame)
self.isprocess = False
self.isPrcVideo = True
self.mode = YOLO("runs/weights/weights/best.pt") # 加载你的模型
# 初始化存储处理后的帧数组
self.processed_frames = []
def select_image(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Image Files (*.png *.jpg *.jpeg)")
if file_path:
pixmap = QPixmap(file_path)
self.im_path = file_path
self.original_display.setPixmap(pixmap.scaled(self.original_display.size(), Qt.KeepAspectRatio))
self.isPrcVideo = False
def select_video(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择视频", "", "Video Files (*.mp4 *.avi *.mov)")
if file_path:
# 清除原有显示内容
if hasattr(self, 'video_capture'):
self.video_capture.release()
if hasattr(self, 'video_timer'):
self.video_timer.stop()
# 初始化 OpenCV 视频捕获
self.video_capture = cv2.VideoCapture(file_path)
# 检查视频是否成功打开
if not self.video_capture.isOpened():
QMessageBox.warning(self, "错误", "无法打开视频文件!")
return
self.isprocess = False
self.isPrcVideo = True
self.video_timer.start(30) # 根据帧率设置定时器间隔
def update_frame(self):
# 读取下一帧
ret, frame = self.video_capture.read()
if ret:
# 将 OpenCV 帧转换为 QImage
if self.isprocess:
ori_frame = frame.copy()
results = self.mode.predict(frame)
frame = results[0].plot()
# 存储处理后的帧
self.processed_frames.append(frame.copy())
# 提取车牌边界框并显示在右侧窗口
if hasattr(results[0], 'boxes') and len(results[0].boxes) > 0:
# 获取边界框坐标
box = results[0].boxes.xyxy[0].cpu().numpy()
x1, y1, x2, y2 = map(int, box)
# 裁剪车牌区域
cropped_plate = ori_frame[y1:y2, x1:x2]
# # 转换为RGB格式
cropped_plate = cv2.cvtColor(cropped_plate, cv2.COLOR_BGR2RGB)
# 显示裁剪后的车牌
h, w, ch = cropped_plate.shape
bytes_per_line = ch * w
q_image_plate = QImage(cropped_plate.data, w, h, bytes_per_line, QImage.Format_RGB888)
self.plate_pixmap = QPixmap.fromImage(q_image_plate)
self.segmented_display.setPixmap(self.plate_pixmap.scaled(
self.segmented_display.width(), self.segmented_display.height(),
Qt.KeepAspectRatio, Qt.SmoothTransformation
))
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, ch = frame.shape
bytes_per_line = ch * w
q_image = QImage(frame.data, w, h, bytes_per_line, QImage.Format_RGB888)
self.video_pixmap = QPixmap.fromImage(q_image)
self.original_display.setPixmap(self.video_pixmap.scaled(
self.original_display.width(), self.original_display.height(),
Qt.KeepAspectRatio, Qt.SmoothTransformation
))
else:
self.video_timer.stop()
pass
def process(self):
if self.isPrcVideo:
if hasattr(self, 'video_capture') and self.video_capture is not None:
# 重置视频到第一帧
self.video_capture.set(cv2.CAP_PROP_POS_FRAMES, 0)
self.processed_frames = []
self.isprocess = True
if hasattr(self, 'video_timer'):
self.video_timer.stop()
self.video_timer.start(30)
else:
QMessageBox.warning(self, "错误", "请先选择视频!")
else:
if self.im_path:
im0 = cv2.imread(self.im_path)
results = self.mode.predict(im0)
self.img_result = results[0].plot()
# 显示原始图像
img_result2 = cv2.cvtColor(self.img_result, cv2.COLOR_BGR2RGB)
h, w, ch = img_result2.shape
bytes_per_line = ch * w
q_image = QImage(img_result2.data, w, h, bytes_per_line, QImage.Format_RGB888)
self.video_pixmap = QPixmap.fromImage(q_image)
self.original_display.setPixmap(self.video_pixmap.scaled(
self.original_display.width(), self.original_display.height(),
Qt.KeepAspectRatio, Qt.SmoothTransformation
))
# 提取车牌边界框并显示在右侧窗口
if hasattr(results[0], 'boxes') and len(results[0].boxes) > 0:
# 获取边界框坐标
box = results[0].boxes.xyxy[0].cpu().numpy()
x1, y1, x2, y2 = map(int, box)
# 裁剪车牌区域
cropped_plate = im0[y1:y2, x1:x2]
#保存最后裁剪结果
self.result_cropped = cropped_plate
# 转换为RGB格式
cropped_plate = cv2.cvtColor(cropped_plate, cv2.COLOR_BGR2RGB)
# 显示裁剪后的车牌
h, w, ch = cropped_plate.shape
bytes_per_line = ch * w
q_image_plate = QImage(cropped_plate.data, w, h, bytes_per_line, QImage.Format_RGB888)
self.plate_pixmap = QPixmap.fromImage(q_image_plate)
self.segmented_display.setPixmap(self.plate_pixmap.scaled(
self.segmented_display.width(), self.segmented_display.height(),
Qt.KeepAspectRatio, Qt.SmoothTransformation
))
else:
# 如果没有检测到车牌,显示提示信息
self.segmented_display.setText("未检测到车牌区域")
else:
QMessageBox.warning(self, "错误", "请先选择图片或视频!")
def save_result(self):
if self.isPrcVideo:
if len(self.processed_frames) > 0:
# 弹出保存视频对话框
file_path, _ = QFileDialog.getSaveFileName(self, "保存视频", "", "Video Files (*.mp4 *.avi *.mov)")
if file_path:
# 获取第一帧的尺寸
height, width, _ = self.processed_frames[0].shape
# 初始化视频写入器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(file_path, fourcc, 30.0, (width, height))
# 写入所有帧
for frame in self.processed_frames:
video_writer.write(frame)
# 释放资源
video_writer.release()
QMessageBox.information(self, "成功", "视频保存成功!")
else:
QMessageBox.warning(self, "错误", "请先处理视频!")
else:
if self.im_path:
file_path, _ = QFileDialog.getSaveFileName(self, "保存图片", "", "Image Files (*.png *.jpg *.jpeg)")
if file_path:
cv2.imwrite(file_path, self.result_cropped)
QMessageBox.information(self, "成功", "图片保存成功!")
else:
QMessageBox.warning(self, "错误", "请先选择图片或视频!")
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
代码关键部分解释
- 初始化界面:在__init__中设置布局、按钮和显示区域。加载YOLO模型:self.mode = YOLO("runs/weights/weights/best.pt")。
- 选择图片/视频:使用QFileDialog打开文件,选择后显示在左侧。
- 分割处理:点击“分割”按钮,对于图片,直接使用YOLO预测,绘制边界框并裁剪车牌显示在右侧。对于视频,使用定时器逐帧处理,存储处理帧。
- 保存结果:对于图片,保存裁剪车牌;对于视频,保存处理后的视频文件。
- 视频处理:使用QTimer控制帧率(30ms间隔),在update_frame中预测并更新显示。
使用方法
- 运行代码:python main.py。
- 图片检测:
- 点击“选择图片”,选一张含车牌的图像。
- 点击“分割”,左侧显示标注后的图像,右侧显示裁剪车牌(带置信度)。
- 点击“保存结果”,保存裁剪车牌。
- 视频检测:
- 点击“选择视频”,选一个视频文件(首次会播放原视频)。
- 点击“分割”,处理视频,实时标注车牌并显示裁剪区域。
- 点击“保存结果”,保存处理后的视频。
训练模型(可选)
如果想自己训练:
- 准备数据集:images文件夹放图片,labels文件夹放YOLO格式标注(.txt文件,每行:class x_center y_center width height)。
- 我们这里也提供了训练脚本:
# -*- coding: utf-8 -*-
"""
该脚本用于执行YOLO模型的训练。 它会自动处理以下任务:
1. 动态修改数据集配置文件 (data.yaml),将相对路径更新为绝对路径,以确保训练时能正确找到数据。
2. 从 'pretrained' 文件夹加载指定的预训练模型。
3. 使用预设的参数(如epochs, imgsz, batch)启动训练过程。 要开始训练,只需直接运行此脚本。
"""
import os
import yaml
from pathlib import Path
from ultralytics import YOLO def main():
"""
主训练函数。 该函数负责执行YOLO模型的训练流程,包括:
1. 配置预训练模型。
2. 动态修改数据集的YAML配置文件,确保路径为绝对路径。
3. 加载预训练模型。
4. 使用指定参数开始训练。
"""
# --- 1. 配置模型和路径 --- # 要训练的模型列表
models_to_train = [
{'name': 'yolo12n.pt', 'train_name': 'train_yolo12n'}
] # 获取当前工作目录的绝对路径,以避免相对路径带来的问题
current_dir = os.path.abspath(os.getcwd()) # --- 2. 动态配置数据集YAML文件 --- # 构建数据集yaml文件的绝对路径
data_yaml_path = os.path.join(current_dir, 'train_data', 'data.yaml') # 读取原始yaml文件内容
with open(data_yaml_path, 'r', encoding='utf-8') as f:
data_config = yaml.safe_load(f) # 将yaml文件中的 'path' 字段修改为数据集目录的绝对路径
# 这是为了确保ultralytics库能正确定位到训练、验证和测试集
data_config['path'] = os.path.join(current_dir, 'train_data') # 将修改后的配置写回yaml文件
with open(data_yaml_path, 'w', encoding='utf-8') as f:
yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True) # --- 3. 循环训练每个模型 --- for model_info in models_to_train:
model_name = model_info['name']
train_name = model_info['train_name'] print(f"\n{'='*60}")
print(f"开始训练模型: {model_name}")
print(f"训练名称: {train_name}")
print(f"{'='*60}") # 构建预训练模型的完整路径
pretrained_model_path = os.path.join(current_dir, 'pretrained', model_name)
if not os.path.exists(pretrained_model_path):
print(f"警告: 预训练模型文件不存在: {pretrained_model_path}")
print(f"跳过模型 {model_name} 的训练")
continue try:
# 加载指定的预训练模型
model = YOLO(pretrained_model_path) # --- 4. 开始训练 --- print(f"开始训练 {model_name}...")
# 调用train方法开始训练
model.train(
data=data_yaml_path, # 数据集配置文件
epochs=100, # 训练轮次
imgsz=640, # 输入图像尺寸
batch=16, # 每批次的图像数量
name=train_name, # 模型名称
) print(f"{model_name} 训练完成!") except Exception as e:
print(f"训练 {model_name} 时出现错误: {str(e)}")
print(f"跳过模型 {model_name},继续训练下一个模型")
continue print(f"\n{'='*60}")
print("所有模型训练完成!")
print(f"{'='*60}") if __name__ == "__main__":
# 当该脚本被直接执行时,调用main函数
main()![]()
- 参数:epochs(训练轮次)、batch(批次大小)等。
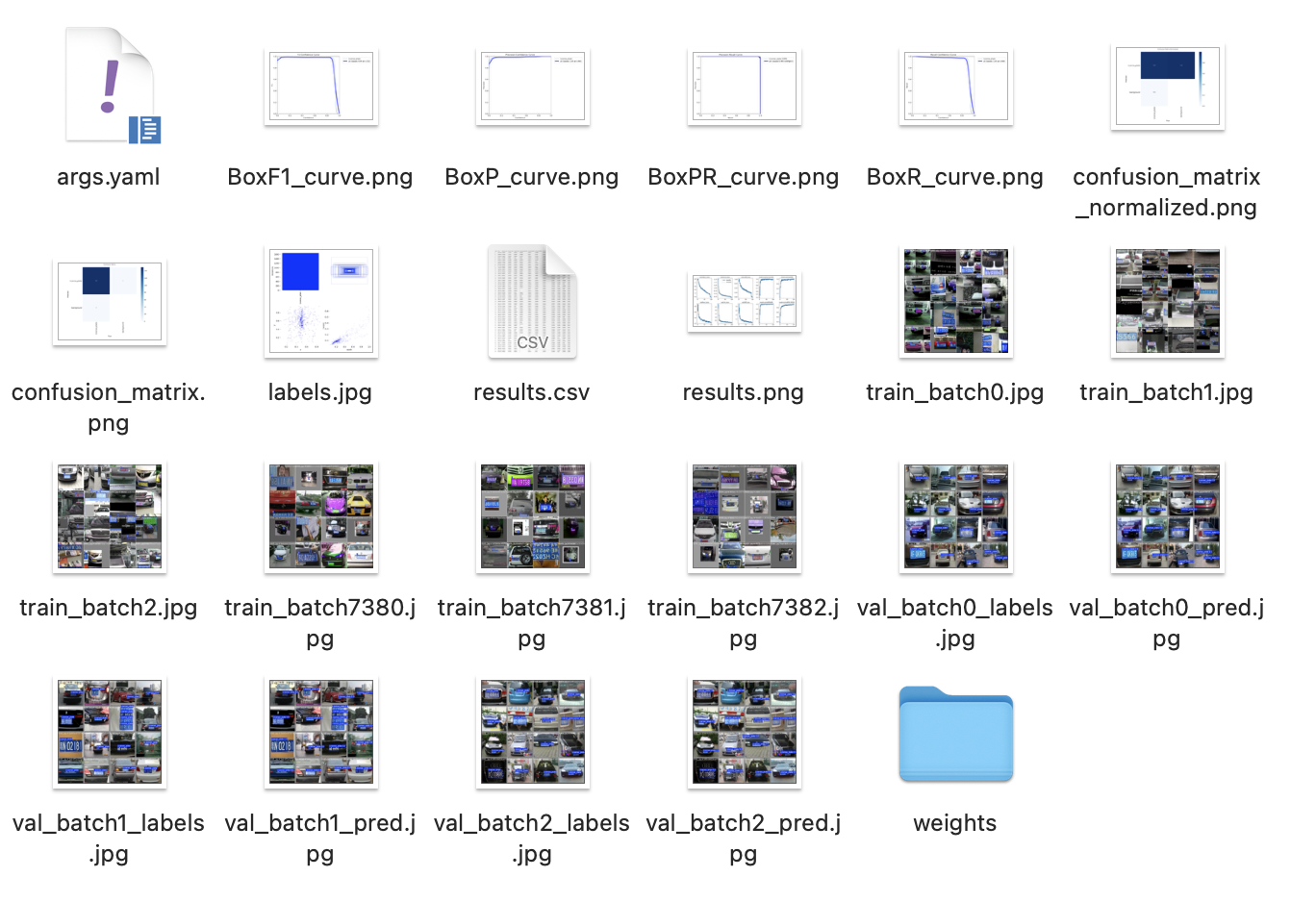
- 训练后,权重文件在runs/detect/train/weights/best.pt。
训练结果示例:F1分数、召回率等指标可在runs文件夹查看。
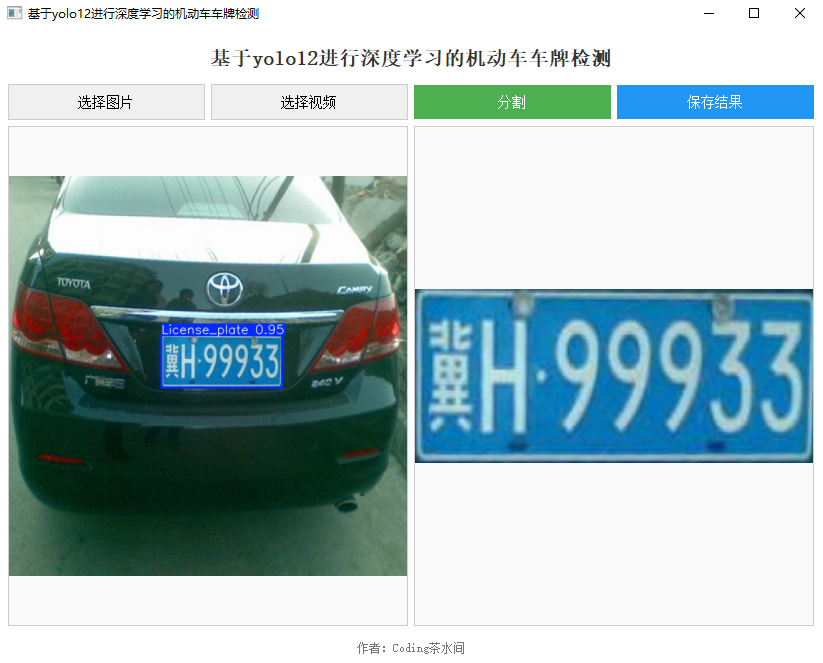
效果展示
- 图片效果:输入一张车牌图像,输出蓝色框标注 + 置信度 + 单独车牌图像。
- 视频效果:实时检测前景明显的车牌,支持新能源车牌。
- 数据集示例:1300+张训练图像,包含多角度、多颜色变化。
结语
这个基于YOLOv12的车牌检测项目简单高效,适合入门深度学习目标检测。如果你有自己的车牌数据集,可以用这套代码训练和验证。欢迎交流改进思路!
基于yolo12进行深度学习的机动车车牌检测的更多相关文章
- 从Theano到Lasagne:基于Python的深度学习的框架和库
从Theano到Lasagne:基于Python的深度学习的框架和库 摘要:最近,深度神经网络以“Deep Dreams”形式在网站中如雨后春笋般出现,或是像谷歌研究原创论文中描述的那样:Incept ...
- (转) 基于Theano的深度学习(Deep Learning)框架Keras学习随笔-01-FAQ
特别棒的一篇文章,仍不住转一下,留着以后需要时阅读 基于Theano的深度学习(Deep Learning)框架Keras学习随笔-01-FAQ
- 基于TensorFlow的深度学习系列教程 2——常量Constant
前面介绍过了Tensorflow的基本概念,比如如何使用tensorboard查看计算图.本篇则着重介绍和整理下Constant相关的内容. 基于TensorFlow的深度学习系列教程 1--Hell ...
- 基于 Keras 用深度学习预测时间序列
目录 基于 Keras 用深度学习预测时间序列 问题描述 多层感知机回归 多层感知机回归结合"窗口法" 改进方向 扩展阅读 本文主要参考了 Jason Brownlee 的博文 T ...
- 基于pythpn的深度学习 - 记录
[基于pythpn的深度学习] 环境: windows/linux-ubuntu Tensorflow (基于anaconda) *安装 (python3.5以上不支持) ...
- 基于OpenCL的深度学习工具:AMD MLP及其使用详解
基于OpenCL的深度学习工具:AMD MLP及其使用详解 http://www.csdn.net/article/2015-08-05/2825390 发表于2015-08-05 16:33| 59 ...
- 学习Keras:《Keras快速上手基于Python的深度学习实战》PDF代码+mobi
有一定Python和TensorFlow基础的人看应该很容易,各领域的应用,但比较广泛,不深刻,讲硬件的部分可以作为入门人的参考. <Keras快速上手基于Python的深度学习实战>系统 ...
- 语义分割:基于openCV和深度学习(二)
语义分割:基于openCV和深度学习(二) Semantic segmentation in images with OpenCV 开始吧-打开segment.py归档并插入以下代码: Semanti ...
- 语义分割:基于openCV和深度学习(一)
语义分割:基于openCV和深度学习(一) Semantic segmentation with OpenCV and deep learning 介绍如何使用OpenCV.深度学习和ENet架构执行 ...
- [AI开发]centOS7.5上基于keras/tensorflow深度学习环境搭建
这篇文章详细介绍在centOS7.5上搭建基于keras/tensorflow的深度学习环境,该环境可用于实际生产.本人现在非常熟练linux(Ubuntu/centOS/openSUSE).wind ...
随机推荐
- 简单的sqlHelper类
public class SQLHelper { //连接数据库 static string connStr = ConfigurationManager.Conn ...
- Linux 基金会报告解读:开源 AI 重塑经济格局,有人失业,有人涨薪!
译自 | Linux Foundation Research 随着生成式 AI 技术飞速发展,开源模式正在成为推动经济转型的重要驱动力.Linux Foundation Research 发布的报告& ...
- Excel中的数字转文本和文本转数字
公式方法: 数字转文本: =TEXT(A1,"?") 文本转数字: 直接乘以1即可 数字转文本: =A1*1 或者使用value函数 =value() 分列方法: 在数据工具&qu ...
- rtl8723bs/ds 蓝牙和wifi共存造成蓝牙的卡顿解决方案.
首先.先确认 POWER_SAVING 这个宏是否打开,如果打开了请关掉,因为这个功能是路由器把对应的设备的流量包存储在路由器上,然后到一定的包的数量的时候,分发给嵌入式设备.如果这样可能造成天线通过 ...
- 蓝牙 bluez 的编程 C C++
蓝牙 bluez 的编程 C C++ 简介 bluez目录有一个libbluetooth.a文件 有一个目录 lib目录里面存储这网络连接的部分代码 基于库的代码编程. 在linux下如果自带了蓝牙, ...
- Cursor——Tab 标签:智能代码补全的终极工具
引言 在现代软件开发中,代码自动补全功能已经成为提高开发效率的重要工具.Cursor 编辑器中的 Tab 标签功能通过先进的 AI 技术,将传统的代码补全提升到了一个全新的水平.它不仅提供基础的代码建 ...
- 4月18日“RestCloud ETL社区版”重磅推出
- -/ 新一代ETL数据集成平台 /-- 数据价值的挖掘应用为当今社会的数字化进程开辟出了一个新的发展方向,未来更多的企业将逐渐进行数字化转型,以便于参与到数据产业体系当中,从而获得更强的创新能力和 ...
- Linux新建txt文档以及vim编辑
1.touch + qwe.txt(文件名 ) 创建文件akk.txt文件 2.vi akk.txt vi为进入vim编辑器命令,意为在vim编辑器中编辑qwe.txt文件 3.i i意为insert ...
- Object Sense (OSE):一款从编辑器脚本发展起来的编程语言
引言:从Vim编辑器走出的语言 在编程语言的世界里,许多革命性的创新往往源于看似简单的工具.Object Sense(简称OSE)的诞生,便与一款经典文本编辑器--Vim息息相关.它的前身是Vim的脚 ...
- 人人都需要重视的Prompt Engineering
去年一直在做AI agent应用的开发,每天和大模型(LLM)打交道,慢慢体会到了提示词工程(Prompt Engineering)的重要性. 一个好的提示词,能让大模型更精准地认识到用户的需求,高效 ...