Andrew Ng机器学习公开课笔记 -- 线性回归和梯度下降
网易公开课,监督学习应用.梯度下降
notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf
线性回归(Linear Regression)
先看个例子,比如,想用面积和卧室个数来预测房屋的价格
训练集如下 
首先,我们假设为线性模型,那么hypotheses定义为  ,
,
其中x1,x2表示面积和#bedrooms两个feature
那么对于线性模型,更为通用的写法为 
其中把θ和X看成向量,并且x0=1,就可以表示成最后那种,两个向量相乘的形式
那么线性回归的目的,就是通过训练集找出使得误差最小的一组参数θ(称为学习)
为了可以量化误差,定义损失函数(cost function) 
比较好理解,就是训练集中所有样本点,真实值和预测值之间的误差的平方和
其中1/2是为了后面计算方便,求导时会消掉
所以我们目的就是找到θ使得J(θ)最小,这就是最小二乘法(最小平方)
看似很容易理解,可是为什么要使用最小二乘来作为损失函数,为何不是差值的绝对值,或4次方?
后面会给出基于概率最大似然的解释
梯度下降(gradient descent)
为了求解这个最优化问题,即找到θ使得J(θ)最小,可以有很多方法
先介绍梯度下降法
这是一种迭代方法,先随意选取初始θ,比如θ=0,然后不断的以梯度的方向修正θ,最终使J(θ)收敛到最小
当然梯度下降找到的最优是局部最优,也就是说选取不同的初值,可能会找到不同的局部最优点
但是对于最小二乘的损失函数模型,比较简单只有一个最优点,所以局部最优即全局最优
对于某个参数的梯度,其实就是J(θ)对该参数求导的结果
所以对于某个参数每次调整的公式如下, 
α is called the learning rate,代表下降幅度,步长,小会导致收敛慢,大会导致错过最优点
所以公式含义就是,每次在梯度方向下降一步
下面继续推导,假设训练集里面只有一个样本点,那么梯度推导为, 
就是求导过程,但是实际训练集中会有m个样本点,所以最终公式为, 
因为θ中有多个参数,所以每次迭代对于每个参数都需要进行梯度下降,直到J(θ)收敛到最小值
这个方法称为batch gradient descent,因为每次计算梯度都需要遍历所有的样本点
这是因为梯度是J(θ)的导数,而J(θ)是需要考虑所有样本的误差和
这个方法问题就是,扩展性问题,当样本点很大的时候,基本就没法算了
所以提出一种stochastic gradient descent(随机梯度下降)
想法很简单,即每次只考虑一个样本点,而不是所有样本点
那么公式就变为, 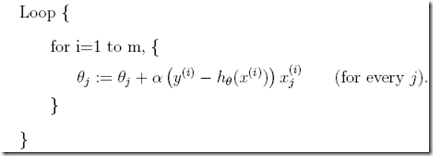
其实意思就是,每次迭代只是考虑让该样本点的J(θ)趋向最小,而不管其他的样本点
这样算法会很快,但是收敛的过程会比较曲折
整体效果,还是可以will be reasonably good approximations to the true minimum
所以适合用于较大训练集的case
Normal Equations
前面说了如何用梯度下降来解线性回归问题
其实对于线性回归,也可以不用这种迭代最优的方式来求解
因为其实可以通过normal equations直接算出θ,即具有解析解
首先对于训练集,可以写成下面的向量形式


由于 ,所以
,所以 
并且 ,故有
,故有 
可以看到经过一系列的推导,J(θ)有了新的表达形式
那么J(θ)的梯度,即求导,可以得到 
而J(θ)最小时,一定是梯度为0时,即可以推出normal equations 
所以使J(θ)最小的θ的值可以直接求出, 
可以参考,Normal Equations
Probabilistic interpretation,概率解释
解释为何线性回归的损失函数会选择最小二乘  ,
, 表示误差,表示unmodeled因素或随机噪声
表示误差,表示unmodeled因素或随机噪声
真实的y和预测出来的值之间是会有误差的,因为我们不可能考虑到所有的影响结果的因素
比如前面的例子,我们根据面积和卧室的个数来预测房屋的价格
但是影响房屋价格的因素其实很多,而且有很多随机因素,比如买卖双方的心情
而根据中心极限定理,大量独立的随机变量的平均值是符合正态分布或高斯分布的
所以这里对于由大量unmodeled因素导致的误差的分布,我们假设也符合高斯分布
因为你想想,大量独立随机变量大部分误差会互相抵消掉,而出现大量变量行为相似造成较大误差的概率是很小的 
可以写成,因为误差的概率和预测出是真实值的概率是一样的 
注意,这里 
不同于 
;,表示这里θ不是一个随机变量,而是翻译成 
因为对于训练集,θ是客观存在的,只是当前还不确定
所以有, 
这个很容易理解,真实值应该是以预测值为中心的一个正态分布
给出θ似然性的定义 
给定训练集X和参数θ,预测结果等于真正结果的概率,等同于该θ为真实θ的可能性(似然性)
这里probability和likelihood有什么不同,答案没有什么不同
但是对于数据使用probability,但对于参数使用likelihood
故最大似然法(maximum likelihood),就是找出L(θ)最大的那个θ,即概率分布最fit训练集的那个θ
继续推导,把上面的式子带入,得到 
实际为了数学计算方便,引入log likelihood, 
可以看到,最终我们从L(θ)的最大似然估计,推导出损失函数J(θ),最小二乘 
所以结论为,最小二乘回归被认为是进行最大似然估计的一个很自然的方法
To summarize: Under the previous probabilistic assumptions on the data, least-squares regression corresponds to finding the maximum likelihood estimate of θ. This is thus one set of assumptions under which least-squares regression can be justified as a very natural method that’s just doing maximum likelihood estimation.
Locally weighted linear regression,局部加权线性回归
对于线性回归,问题是选取的特征的个数和什么特征会极大影响fit的效果
比如下图,是分布使用下面几个模型进行拟合的 



通常会认为第一个模型underfitting,而第三个模型overfitting,第二个模型相对比较好的fit到训练集
所以可以看出,找出一个全局的线性模型去fit整个训练集,是个比较困难的工作,因为选择特征成为一个关键的因素
局部加权线性回归的思路,就是我不需要去fit整个训练集而产生全局的模型
而是在每次predict x的时候,只去拟合x附近的一小段训练集
无论全局训练集是多么复杂的一个分布曲线,但在局部小段数据上,都可以用线性去逼近
所以算法如下, 
其中

可以看到我们通过weight来选取局部样本点
这里weight定义有点类似高斯分布,虽然这里和高斯分布没有关系,只是恰好相似
但是他的分布曲线确实和高斯分布一样,钟型,所以通过weight,只有距离x很近的样本点才会对于损失函数有作用
局部加权线性回归算法是一种non-parametric algorithm
而普通的线性回归是parametric learning algorithm
parametric learning algorithm有一组有限的,固定的参数,一旦完成fit,只需要保存下参数值来做预测,而不需要保存完整的训练集
non-parametric algorithm,相反,我们需要保存完整的训练集来进行预测,而不是仅仅保存参数
正式定义为,the amount of stuff we need to keep in order to represent the hypothesis h grows linearly with the size of the training set.
为了表达假设h而保存的数据随着训练集的size而线性增长
Andrew Ng机器学习公开课笔记 -- 线性回归和梯度下降的更多相关文章
- 局部加权回归、欠拟合、过拟合 - Andrew Ng机器学习公开课笔记1.3
本文主要解说局部加权(线性)回归.在解说局部加权线性回归之前,先解说两个概念:欠拟合.过拟合.由此引出局部加权线性回归算法. 欠拟合.过拟合 例如以下图中三个拟合模型.第一个是一个线性模型.对训练数据 ...
- 损失函数 - Andrew Ng机器学习公开课笔记1.2
线性回归中提到最小二乘损失函数及其相关知识.对于这一部分知识不清楚的同学能够參考上一篇文章<线性回归.梯度下降>. 本篇文章主要解说使用最小二乘法法构建损失函数和最小化损失函数的方法. 最 ...
- Andrew Ng机器学习公开课笔记 -- 支持向量机
网易公开课,第6,7,8课 notes,http://cs229.stanford.edu/notes/cs229-notes3.pdf SVM-支持向量机算法概述, 这篇讲的挺好,可以参考 先继 ...
- Andrew Ng机器学习公开课笔记–Principal Components Analysis (PCA)
网易公开课,第14, 15课 notes,10 之前谈到的factor analysis,用EM算法找到潜在的因子变量,以达到降维的目的 这里介绍的是另外一种降维的方法,Principal Compo ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
网易公开课,第16课 notes,12 前面的supervised learning,对于一个指定的x可以明确告诉你,正确的y是什么 但某些sequential decision making问题,比 ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
- Andrew Ng机器学习公开课笔记 -- Generative Learning algorithms
网易公开课,第5课 notes,http://cs229.stanford.edu/notes/cs229-notes2.pdf 学习算法有两种,一种是前面一直看到的,直接对p(y|x; θ)进行建模 ...
随机推荐
- 转 Angular2优质学习资源收集
文档博客书籍类 官方网站: https://angular.io 中文站点: https://angular.cn Victor的blog(Victor是Angular路由模块的作者): https: ...
- requests模块
import requests url='https://www.cnblogs.com/Eva-J/p/7277026.html' get = requests.get(url) print(get ...
- SQL CHECK 约束
SQL CHECK 约束 CHECK 约束用于限制列中的值的范围. 如果对单个列定义 CHECK 约束,那么该列只允许特定的值. 如果对一个表定义 CHECK 约束,那么此约束会在特定的列中对值进行限 ...
- 23 python初学(模块和包)
模块(module): 好处: 提高代码可维护性 + 编写代码不必从零开始 模块有三种: python标准库.第三方模块.应用程序自定义模块 另外,使用模块还可以避免函数名和变量名冲突,相同名字的函数 ...
- Parallel 类并行任务(仅仅当执行耗时操作时,才有必要使用)
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...
- 基于C#的钉钉SDK开发(1)--对官方SDK的重构优化
在前段时间,接触一个很喜欢钉钉并且已在内部场景广泛使用钉钉进行工厂内部管理的客户,如钉钉考勤.日常审批.钉钉投影.钉钉门禁等等方面,才体会到原来钉钉已经已经在企业上可以用的很广泛的,因此回过头来学习研 ...
- Spring 使用AOP——xml配置
目录 AOP介绍 Spring进行2种实现AOP的方式 导入jar包 基于schema-based方式实现AOP 创建前置通知 创建后置通知 修改Spring配置文件 基于schema-based方式 ...
- Kubernetes — Job与CronJob
有一类作业显然不满足这样的条件,这就是“离线业务”,或者叫作 Batch Job(计算业务). 这 种业务在计算完成后就直接退出了,而此时如果你依然用 Deployment 来管理这种业务的话,就会 ...
- Linux C/C++ 链接选项之静态库--whole-archive,--no-whole-archive和--start-group, --end-group
参照这两篇博客: http://stackoverflow.com/questions/805555/ld-linker-question-the-whole-archive-option http: ...
- 使用FaceNet 图像相识度对比
1. 模型结构: