SQLServer之创建唯一聚集索引
创建唯一聚集索引典型实现
唯一索引可通过以下方式实现:
PRIMARY KEY 或 UNIQUE 约束
在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动对一列或多列创建唯一聚集索引。 主键列不允许空值。
在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束。 如果不存在该表的聚集索引,则可以指定唯一聚集索引。
有关详细信息,请参阅 Unique Constraints and Check Constraints 和 Primary and Foreign Key Constraints。
独立于约束的索引
可以为一个表定义多个唯一非聚集索引。
有关详细信息,请参阅 CREATE INDEX (Transact-SQL)。
索引视图
若要创建索引视图,请对一个或多个视图列定义唯一聚集索引。 视图将执行,并且结果集存储在该索引的页级别中,其存储方式与表数据存储在聚集索引中的方式相同。 有关详细信息,请参阅 创建索引视图。
创建唯一聚集索引限制和局限
如果数据中存在重复的键值,则不能创建唯一索引、UNIQUE 约束或 PRIMARY KEY 约束。
唯一非聚集索引可以包括包含性非键列。 有关详细信息,请参阅 Create Indexes with Included Columns。
使用SSMS数据库管理工具创建唯一聚集索引
使用表设计器创建唯一索引
1、连接数据库,选择数据库,选择数据表-》右键点击数据表-》选择设计。
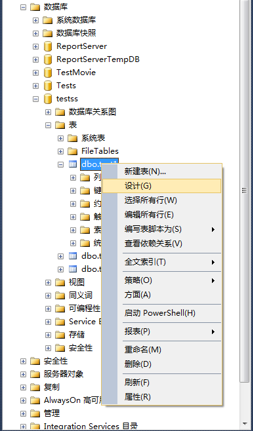
2、在表设计器窗口-》选择要添加索引的数据列-》右键点击-》选择索引/键。
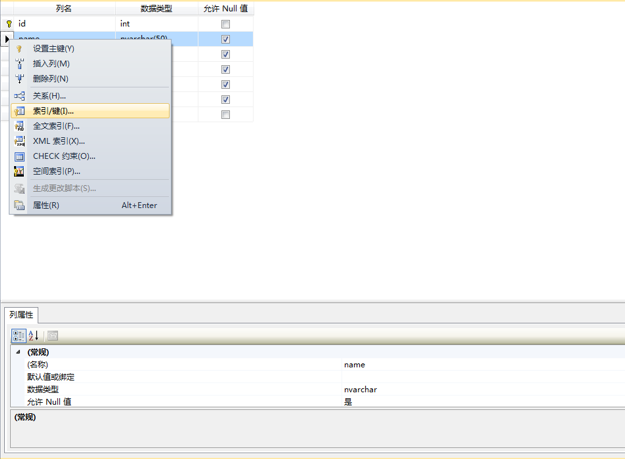
3、在索引/键弹出款-》点击添加-》类型选择索引-》点击选择列。
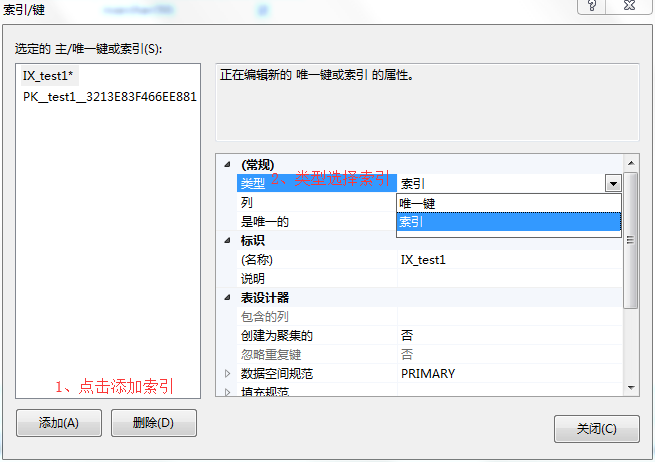
4、在索引列弹出框-》选择索引数据列-》选择索引排序方式-》可以添加多个索引列-》点击确定。
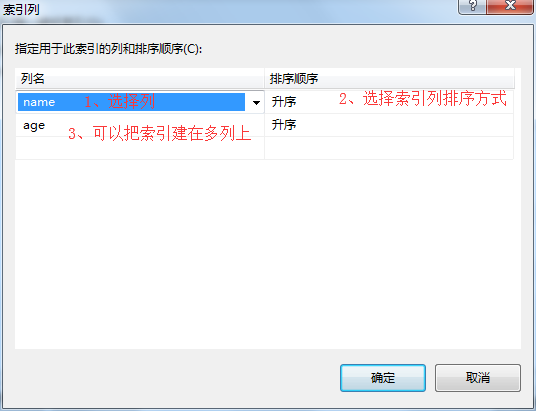
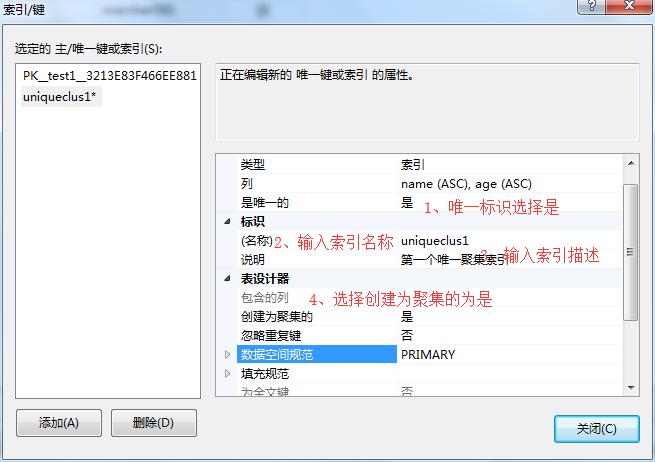
5、在索引/键弹出框-》是唯一的选择是-》输入索引名称-》输入索引描述-》创建为聚集的选择为是-》其它可以选择默认或者自己设置-》点击关闭。
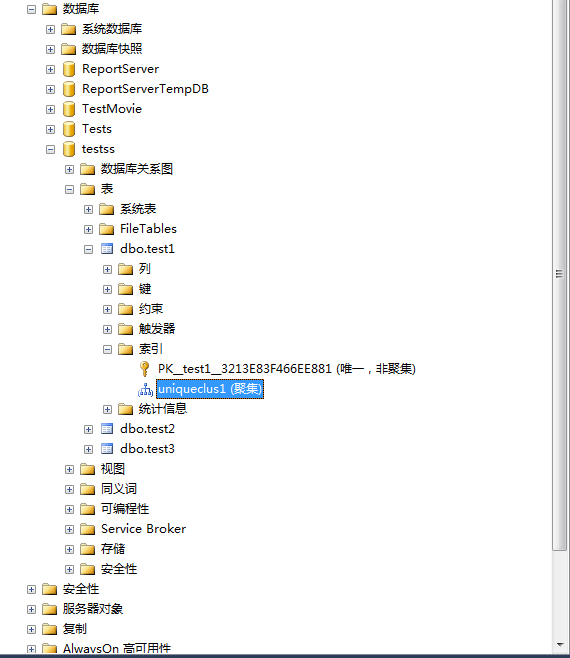
6、点击保存(或者按下ctrl+s)-》关闭表设计器-》刷新表-》查看创建结果。
使用对象资源管理器创建唯一索引
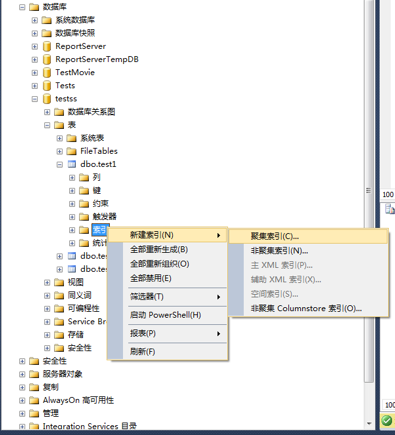
1、连接数据库,选择数据库,选择数据表-》展开对象资源管理器-》右键点击索引-》点击新建索引-》选择聚集索引。
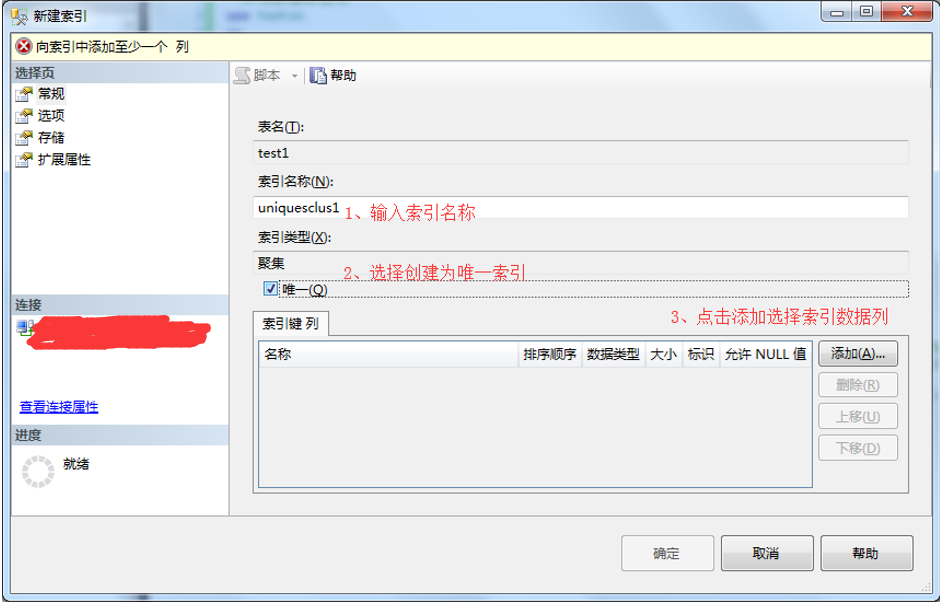
2、在新建索引弹出框-》输入索引名称-》选择唯一创建为唯一聚集索引-》点击添加选择索引数据列。
3、在表选择列弹出框中-》选择数据列,可以选择多个-》点击确定。
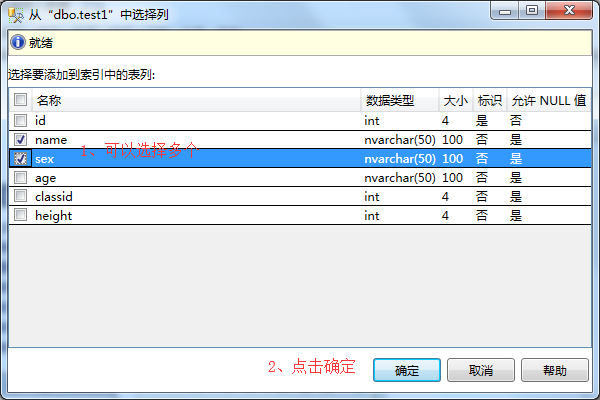
4、在新建索引弹出框-》点击选项-》可以自行设置索引属性。
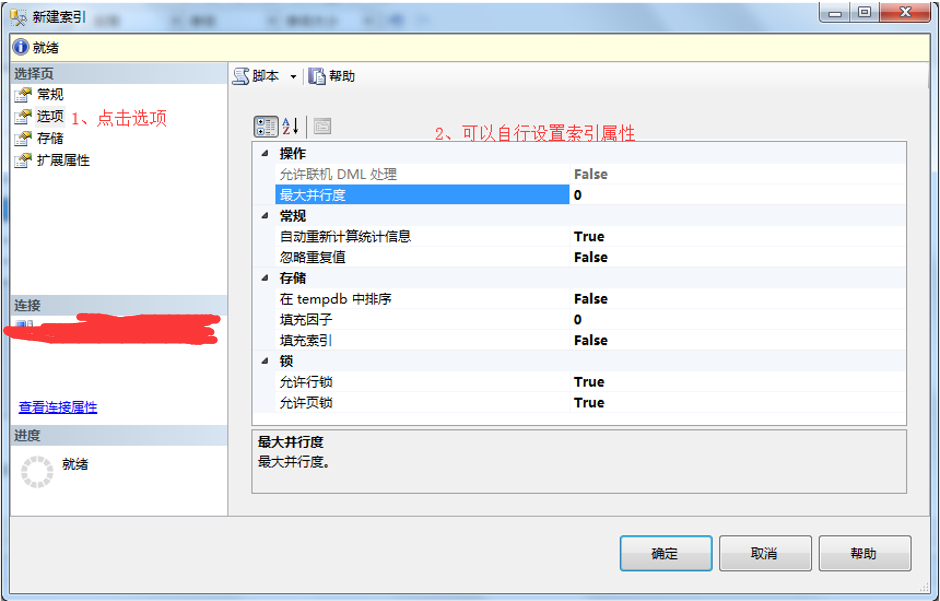
5、在新建索引弹出框-》点击存储-》选择设置存储存储属性。
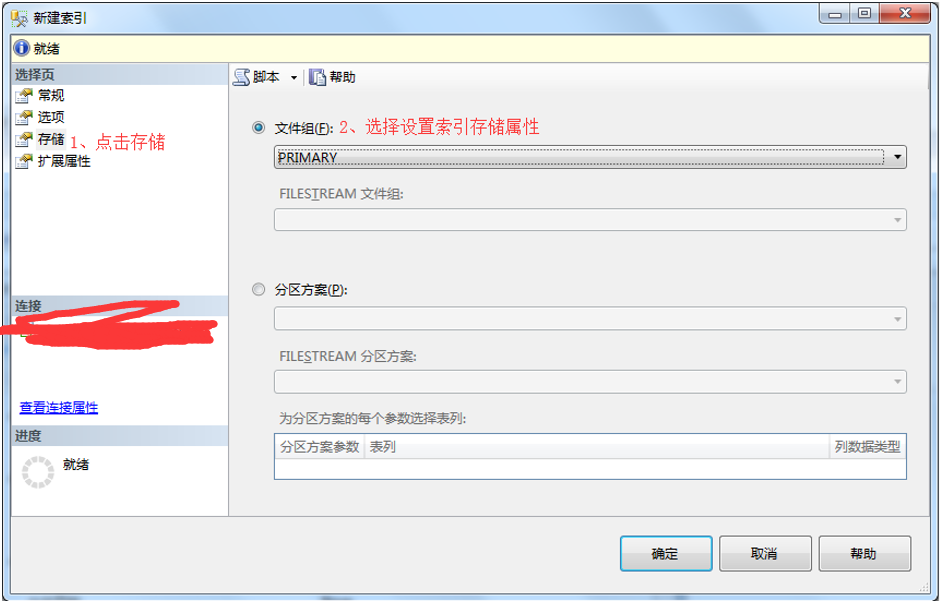
6、在新建索引弹出框-》点击扩展属性-》添加扩展属性名称-》添加扩展属性值-》点击确定。
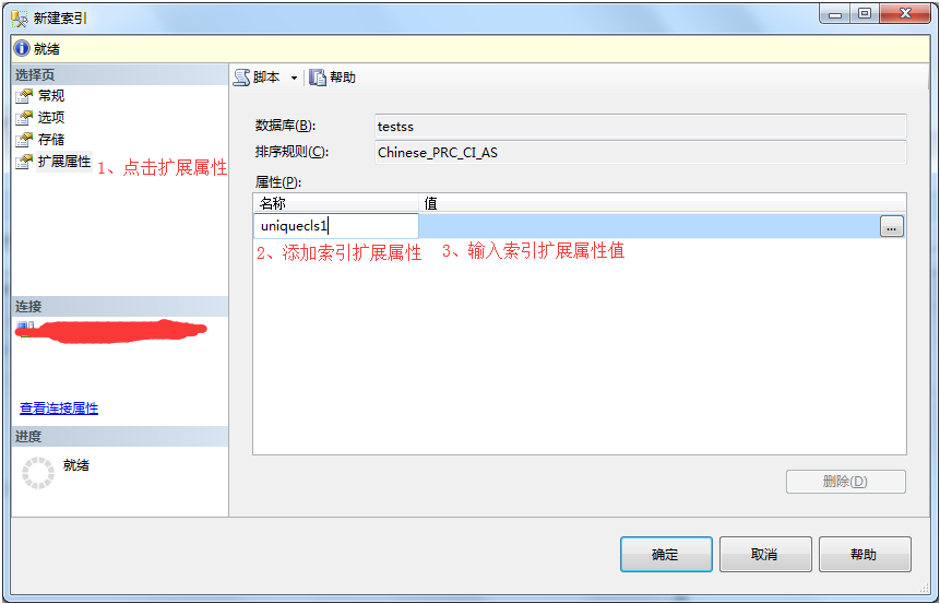
7、查看创建结果。
使用T-SQL脚本创建唯一聚集索引
语法:
--声明数据库引用
use 数据库名;
go
--判断索引是否存在
if exists(select * from sysindexes where name=索引名)
drop index 索引名 on 表名 with (online=off);
go
--添加索引
create
--[unique] --指定聚集索引是否唯一
[clustered | nonclustered] --指定为聚集索引
index 索引名称 --索引名称
on 表名 --索引添加在哪个表
(列名 [asc | desc],列名 [asc | desc],...) --索引添加在哪个数据列
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index={ on | off },
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute={ on | off },
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb={ on | off },
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key={ on | off },
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing={ on | off },
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online={ on | off },
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
-- allow_page_locks=off:不使用页锁。
allow_page_locks={ on | off },
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=n
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
--maxdop=max_degree_of_parallelism,
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression={ none | row | page | columnstore | columnstore_archive }
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2)
)
on [primary];--数据空间规范
go
--添加注释
execute sp_addextendedproperty N'MS_Description',N'索引说明',N'schema',N'dbo',N'table',N'表名',N'index',N'索引名称';
go
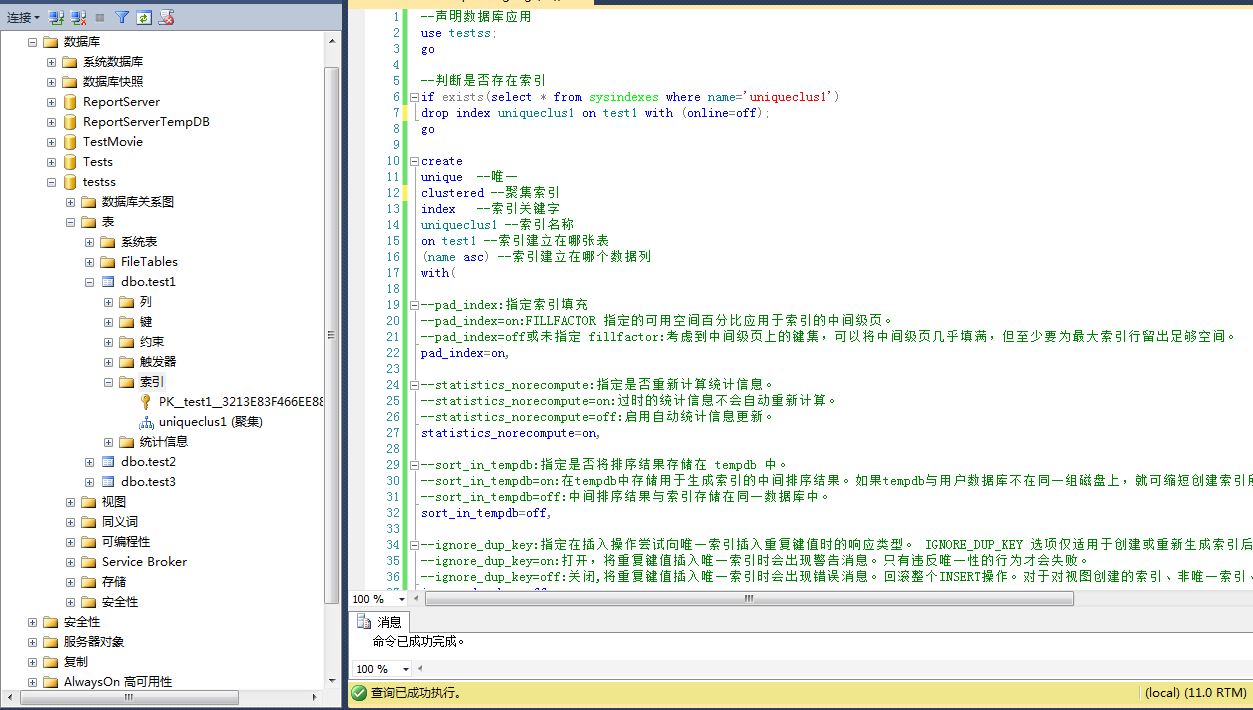
示例:
--声明数据库应用
use testss;
go
--判断是否存在索引
if exists(select * from sysindexes where name='uniqueclus1')
drop index uniqueclus1 on test1 with (online=off);
go
create
unique --唯一
clustered --聚集索引
index --索引关键字
uniqueclus1 --索引名称
on test1 --索引建立在哪张表
(name asc) --索引建立在哪个数据列
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index=on,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute=on,
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb=off,
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key=off,
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing=off,
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online=off,
--allow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks=on,
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
--allow_page_locks=off:不使用页锁。
allow_page_locks=on,
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=1,
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=1
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression=none
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2)
)
on [primary];
go
--添加唯一聚集索引描述
execute sp_addextendedproperty N'MS_Description',N'第一个唯一聚集索引',N'schema',N'dbo',N'table',N'test1',N'index',N'uniqueclus1';
go
创建唯一索引优缺点
优点:
1、多列唯一索引能够保证索引键中值的每个组合都是唯一的。
2、只要每个列中的数据是唯一的,就可以为同一个表创建一个唯一聚集索引。
3、唯一索引能够确保定义的列的数据完整性。
4、唯一索引提供帮助查询优化器生成更高效的执行计划的其他信息。
5、创建唯一索引只会创建一个唯一索引,不会创建约束。
缺点:
1、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
2、索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
3、当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
SQLServer之创建唯一聚集索引的更多相关文章
- SQLServer之创建非聚集索引
开始之前 典型实现 可以通过下列方法实现非聚集索引: UNIQUE 约束 在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束. 如果不存在该表的聚集索引,则可以 ...
- SqlServer中创建非聚集索引和非聚集索引
聚集索引与非聚集索引,其实已经有很多的文章做过详细介绍. 非聚集索引 简单来说,聚集索引是适合字段变动不大(尽可能不出现Update的字段).出现字段重复率小的列,因为聚集索引是对数据物理位置相同的索 ...
- SQLServer之创建唯一非聚集索引
创建唯一非聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自 ...
- SQLServer之创建辅助XML索引
创建辅助XML索引 使用 CREATE INDEX (Transact-SQL)Transact-SQL DDL 语句可创建辅助 XML 索引并且可指定所需的辅助 XML 索引的类型. 创建辅助 XM ...
- SQL Server ->> 分区表上创建唯一分区索引
今天在读<Oracle高级SQL编程>这本书的时候,在关于Oracle的全局索引的章节里面有一段讲到如果对一张分区表创建一条唯一索引,而索引本身也是分区的,那就必须把分区列也加入到索引列表 ...
- sqlserver获得数据库非聚集索引的代码
创建Index DECLARE @zindex_sql NVARCHAR(max); SET @zindex_sql = N''; SELECT @zindex_sql = @zindex_sql + ...
- SQLServer之创建索引视图
索引视图创建注意事项 对视图创建的第一个索引必须是唯一聚集索引. 创建唯一聚集索引后,可以创建更多非聚集索引. 为视图创建唯一聚集索引可以提高查询性能,因为视图在数据库中的存储方式与具有聚集索引的表的 ...
- SQLServer之添加聚集索引
聚集索引添加规则 聚集索引按下列方式实现 PRIMARY KEY 和 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动对一列或多列创 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
随机推荐
- C# 多线程学习笔记 - 2
本文主要针对 GKarch 相关文章留作笔记,仅在原文基础上记录了自己的理解与摘抄部分片段. 遵循原作者的 CC 3.0 协议. 如果想要了解更加详细的文章信息内容,请访问下列地址进行学习. 原文章地 ...
- scala时间和时间戳互转
时间转换为时间戳: import java.text.SimpleDateFormat object test { def main(args: Array[String]): Unit = { va ...
- 网络协议 8 - TCP协议(上):性恶就要套路深
系列文章: 网络协议 1 - 概述 网络协议 2 - IP 是怎么来,又是怎么没的? 网络协议 3 - 从物理层到 MAC 层 网络协议 4 - 交换机与 VLAN:办公室太复杂,我要回学校 网络协议 ...
- shell的exec命令
工作中遇到运维人员挂supervisor的时候建议启动使用命令control.sh start, 并且在control.sh 里面启动命令: exec -c ./bin/xxx -f config/x ...
- mybatis框架(6)---mybatis插入数据后获取自增主键
mybatis插入数据后获取自增主键 首先理解这就话的意思:就是在往数据库表中插入一条数据的同时,返回该条数据在数据库表中的自增主键值. 有什么用呢,举个例子: 你编辑一条新闻,同时需要给该新闻打上标 ...
- 并发编程(十五)——定时器 ScheduledThreadPoolExecutor 实现原理与源码深度解析
在上一篇线程池的文章<并发编程(十一)—— Java 线程池 实现原理与源码深度解析(一)>中从ThreadPoolExecutor源码分析了其运行机制.限于篇幅,留下了Scheduled ...
- 用Javascript方式实现LeetCode中的算法(更新中)
前一段时间抽空去参加面试,面试官一开始让我做一道题,他看完之后,让我回答一下这个题的时间复杂度并优化一下,当时的我虽然明白什么是时间复杂度,但不知道是怎么计算的,一开局出师不利,然后没然后了,有一次我 ...
- 【SpringCloud Eureka源码】从Eureka Client发起注册请求到Eureka Server处理的整个服务注册过程(下)
目录 一.Spring Cloud Eureka Server自动配置及初始化 @EnableEurekaServer EurekaServerAutoConfiguration - 注册服务自动配置 ...
- 通过 Ansible 安装 Docker
本文的演示环境为 ubuntu 16.04. 先在 Ansible Galaxy 搜索 docker,由 geerlingguy 贡献的 docker role 是目前最受欢迎的: 通过 ansibl ...
- [二十四]JavaIO之PrintWriter
功能简介 PrintWriter 向文本输出流打印对象的格式化表示形式 他与PrintStream的逻辑上功能目的是相同的--他们都想做同一件事情--更便捷的格式化打印输出 Print ...