【论文速读】Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
作者和代码

关键词
文字检测、多方向、FCN、$$xywh\theta$$、multi-stage、border
方法亮点
- 采用Bootstrapping进行数据扩增
- 增加border-loss
方法概述
本文方法是直接回归的方法,除了学习text/non-text分类任务,四个点到边界的回归任务(类似EAST),还增加了四条边界的border学习任务,最后输出不是直接用prediction的bounding box,而是用了text score map和四个border map来获得textline。
方法细节
bootstrapping样本扩增
简单说其实就是对文字的polygon做一些重复局部采样,丰富文字patch的多样性。

Fig. 2: Illustration of the bootstrapping based scene text sampling: Given an image with a text line as annotated by the green box, three example text line segments are extracted as highlighted by red boxes where the centers of the sampling windows are taken randomly along the center line of the text line (the shrunk part in yellow color). The rest text regions outside of the sampling windows are filled by inpainting.
具体步骤:
- 确定中心线,进行shrink 0.1L'
- 沿中心线随机均匀采样点(确定框中心)
- 确定框大小(H = 0.9H',W 从[0.2L',2$$d_{min}$$]选取随机值。$$d_{min}$$表示中心点到两条短边的距离的最小值)
- 把处在原文字框内,但在采样框外(上图的绿色框内红色框外)的部分都进行inpainting(涂抹成单色),以此得到新的训练图和text的groundTruth
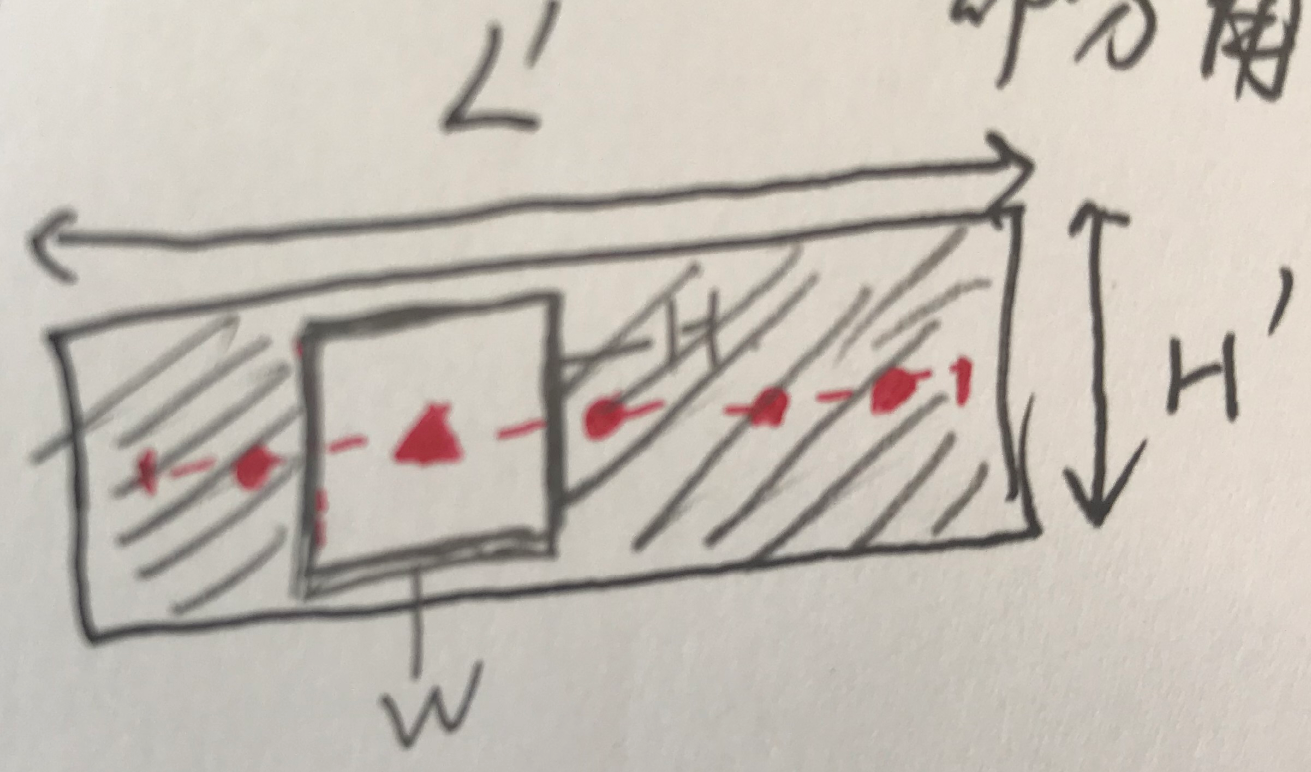
是否有进行bootstrapping的效果图如下:
作者认为,进行augmentation之后,feature map上特征更具有一致性,所以distance map更加平滑。
It can be seen that the inclusion of the augmented images helps to produce more consistent text feature maps as well as smoother geometrical distance maps (for regression of text boxes) which leads to more complete instead of broken scene text detections.
我的理解是,一段很长的文本,处在不同段的文字appearance特征可能很不一样。例如Fig 2中有的地方光很强,有的地方光照很弱,因此,bootstrapping采样的是某个文字的segment,越短则这段text的特征越一致,特征学习就会越concentrate在更一致的区域上(其实是把一个学习问题难度降低了)

Fig. 3: The inclusion of augmented images improves the scene text detection: With the inclusion of the augmented images in training, more consistent text feature maps and more complete scene text detections are produced as shown in (d) and (e), as compared with those produced by the baseline model (trained using original training images only) shown in (b) and (c). The coloring in the text feature maps shows the distance information predicted by regressor (blue denotes short distances and red denotes long distance).
增加四个border-pixel的classification
增加4个要学习的border/non-border的classification map。

Fig. 4: Semantics-aware text border detection: Four text border segments are automatically extracted for each text annotation box including a pair of shortedge text border segments in yellow and red colors and a pair of long-edge text border segments in green and blue colors. The four types of text border segments are treated as four types of objects and used to train deep network models, and the trained model is capable of detecting the four types of text border segments as illustrated in Fig. 5c.
具体的四个border的大小如下。上下取0.2H',左右取0.8H',比较特别的是左右的宽度取得比较大,是H'。主要是担心同一文本行文字黏连问题比较多,而且不像上下border具有很长的边(面积大一些)。上下边界主要为了解决多行文字黏连问题。border要学习的是从text到background的transition(...the extracted text border segments capture the transition from text to background or vice versa...)。
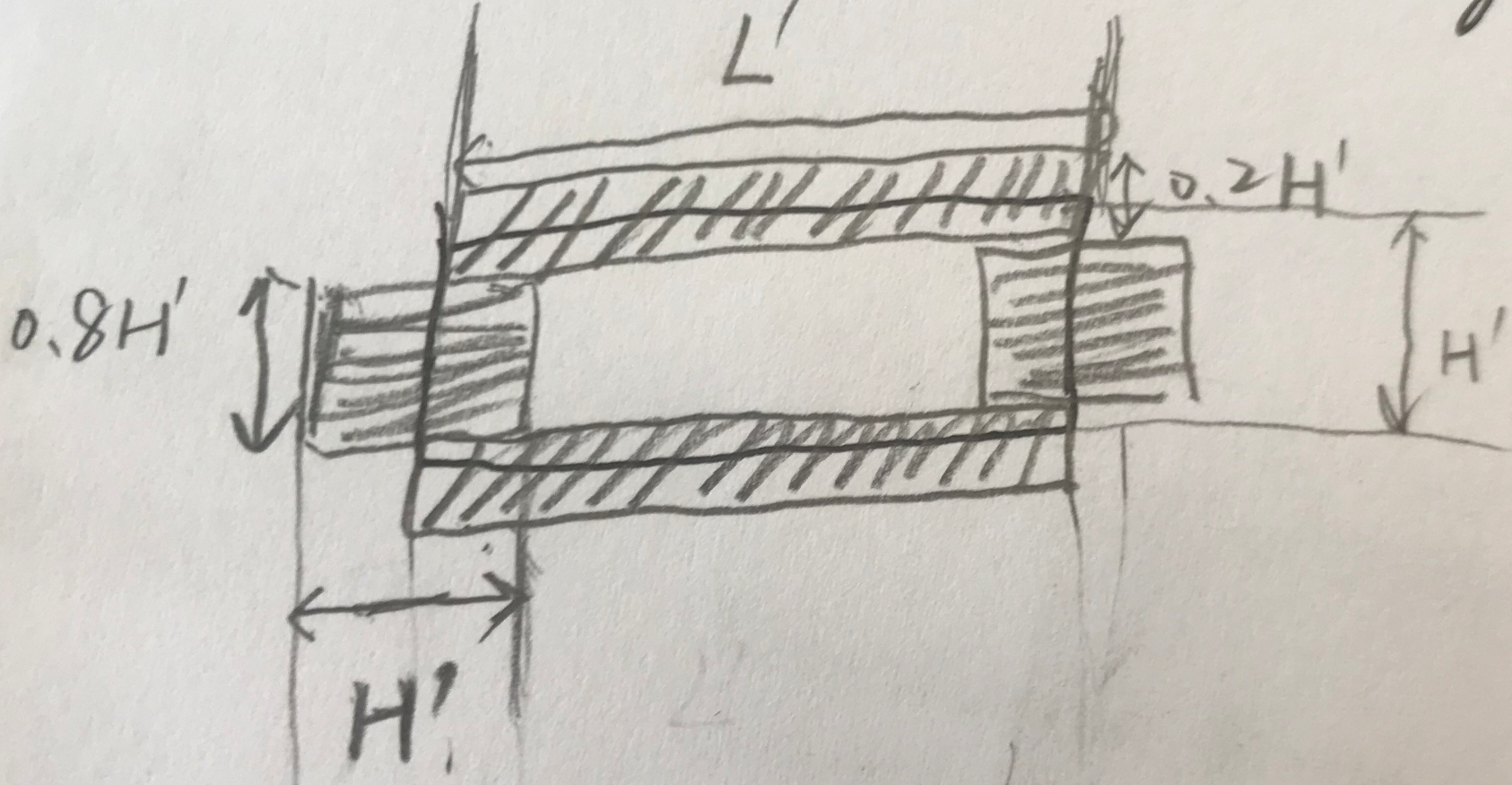
作者认为增加短的border之所以可以提升效果是因为处在文字中心部分的像素离两条短边比较远(长条文字),容易产生回归误差,导致检测结果不精确,而增加border像素的loss可以帮助解决这个问题。另一方面,增加两条长border的目的是为了解决挨的比较近的上下两行文本行的黏连问题。
The reason is that text pixels around the middle of texts are far from the text box vertices for long words or text lines which can easily introduce regression errors and lead to inaccurate localization as illustrated in Fig. 5b. At the other end, the long text border segments also help for better scene text detection performance. In particular, the long text border segments can be exploited to separate text lines when neighboring text lines are close to each other.
是否增加border的效果对比如下图:
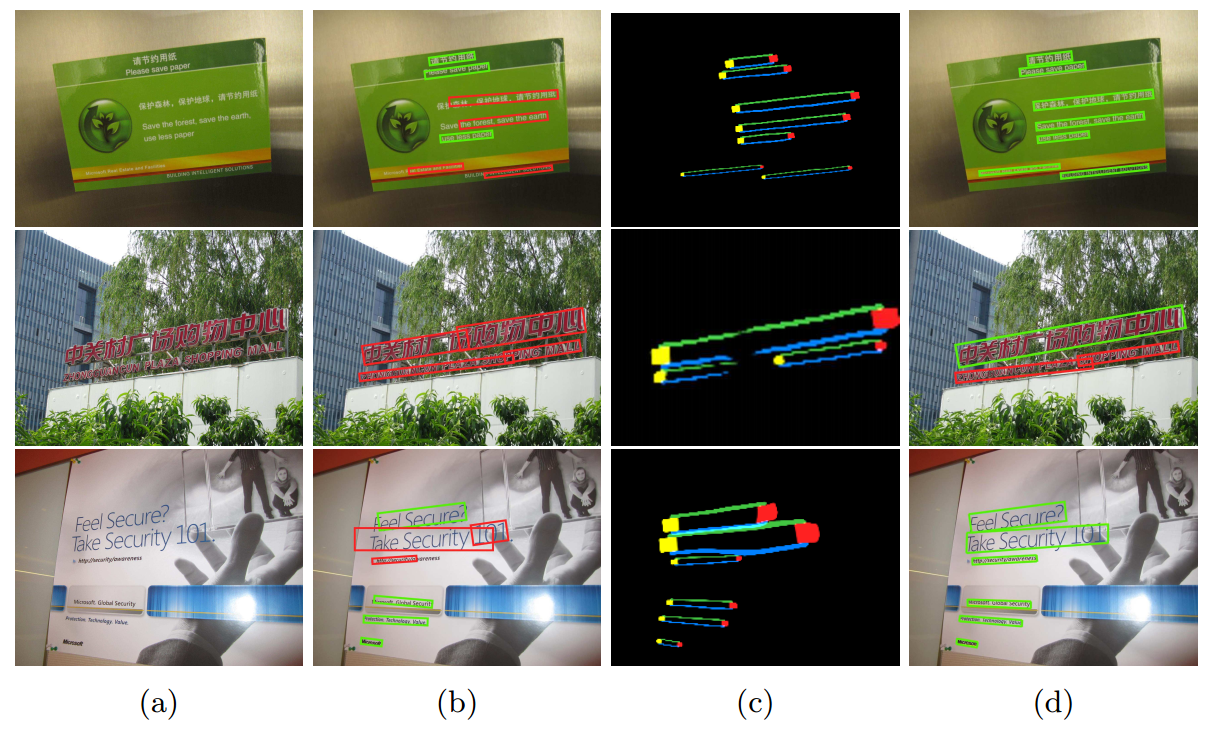
Fig. 5: The use of semantics-aware text borders improves scene text detection: With the identified text border semantics information as illustrated in (c), scene texts can be localized much more accurately as illustrated in (d) as compared with the detections without using the border semantics information as illustrated in (b). Green boxes give correct detections and red boxes give false detections.
损失函数
- 总的损失
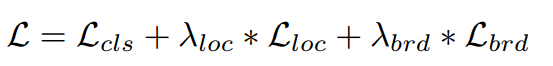
分类损失:采用DIces Coefficient损失(confidence score of each pixel being a text pixel )
- 回归损失:采用IOU损失(distances from each pixel to four sides of text boundaries)
边界损失:采用DIces Coefficient损失(confidence score of each pixel being a border pixel)
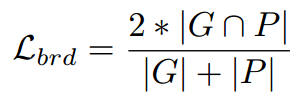
后处理文本线形成算法
- 二值化五个map(1个text region map,4个text border map):采用mean_score
- 算出region map和4个border map的overlap
- 提取文本行(上下边)
- 提取左右边界
- merge四个边界组成的boungding box
- NMS

实验结果
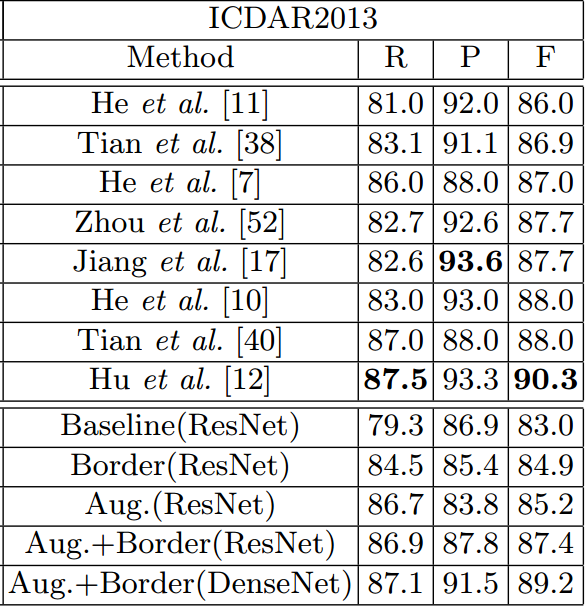
- ICDAR2013
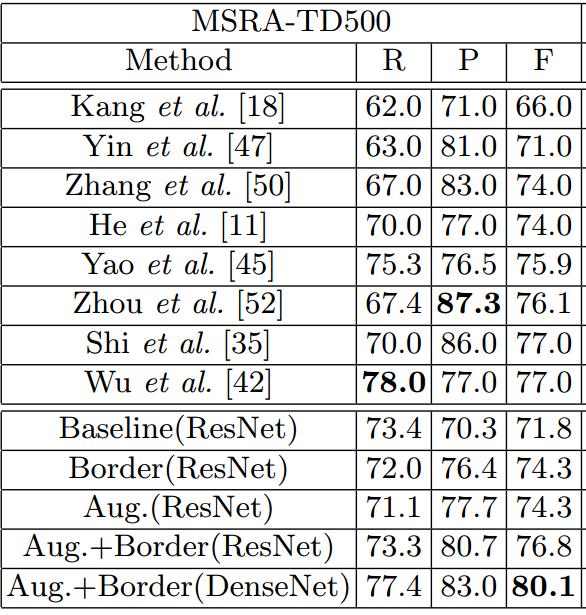
- MSRA-TD500
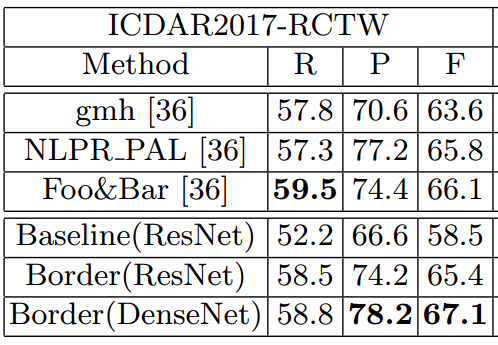
- ICDAR2017-RCTW
- ICDAR2017-MLT
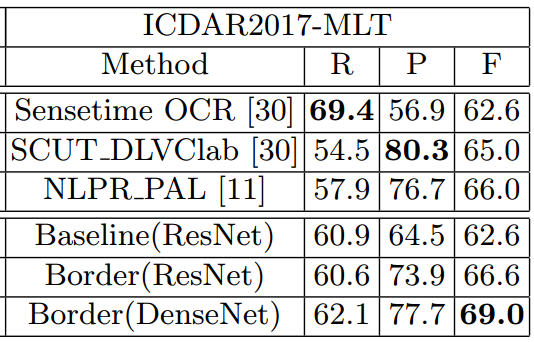
总结与收获
这篇方法的bootstrap来扩增样本的方式很有意思,虽然是在目标检测领域里早有人这么用了,但这是第一次引入到OCR。另外,增加border loss的思路也很直接,与Yue Wu_ICCV2017_Self-Organized Text Detection With Minimal Post-Processing via Border Learning的border有点像。
【论文速读】Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping的更多相关文章
- 【论文速读】Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation[2018-CPVR]
方法概述 该方法用一个端到端网络完成文字检测整个过程——除了基础卷积网络(backbone)外,包括两个并行分支和一个后处理.第一个分支是通过一个DSSD网络进行角点检测来提取候选文字区域,第二个分支 ...
- 论文速读(Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection)
Chuhui Xue--[arxiv2019]MSR_Multi-Scale Shape Regression for Scene Text Detection 论文 Chuhui Xue--[arx ...
- 【论文速读】XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection
XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection 作者和代码 caffe代码 关键词 ...
- 论文速读(Yongchao Xu——【2018】TextField_Learning A Deep Direction Field for Irregular Scene Text)
Yongchao Xu--[2018]TextField_Learning A Deep Direction Field for Irregular Scene Text Detection 论文 Y ...
- 论文阅读(Xiang Bai——【arXiv2016】Scene Text Detection via Holistic, Multi-Channel Prediction)
Xiang Bai--[arXiv2016]Scene Text Detection via Holistic, Multi-Channel Prediction 目录 作者和相关链接 方法概括 创新 ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- XiangBai——【CVPR2018】Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
XiangBai——[CVPR2018]Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentat ...
- Learning Markov Clustering Networks for Scene Text Detection
Learning Markov Clustering Networks for Scene Text Detection 论文下载:https://arxiv.org/pdf/1805.08365v1 ...
- 【论文速读】ChengLin_Liu_ICCV2017_Deep_Direct_Regression_for_Multi-Oriented_Scene_Text_Detection
ChengLin Liu_ICCV2017_Deep Direct Regression for Multi-Oriented Scene Text Detection 作者 关键词 文字检测.多方向 ...
随机推荐
- 《Ray Tracing in One Weekend》、《Ray Tracing from the Ground Up》读后感以及光线追踪学习推荐
<Ray Tracing in One Weekend> 优点: 相对简单易懂 渲染效果相当好 代码简短,只看书上的代码就可以写出完整的程序,而且Github上的代码是将基类与之类写在一起 ...
- 探索JavaScript中Null和Undefined的深渊
当讨论JavaScript中的原始数据类型时,大多数人都知道的基本知识,从String,Number到Boolean.这些原始类型相当简单,行为符合常识.但是,本文将更多聚焦独特的原始数据类型Null ...
- Windows下自带压缩文件工具之-makecab
在内网渗透时,当没有rar.7z等压缩工具时候,拖取文件的时候为了防止流量过大,又必须压缩把文件压缩.当然你可以自己上传一个压缩工具.Windows自带制作压缩文件工具makecb你可以了解哈.压缩单 ...
- 5m21d缓冲区溢出学习笔记
mysql链接字符串函数 concat(str1,str2) concat_ws(separator,str1,str2....) group_concat(str1,str2....) mysql的 ...
- Nginx负载均衡后端健康检查(支持HTTP和TCP)
之前有一篇文章记录nginx负载均衡后端检查,链接为 https://www.cnblogs.com/minseo/p/9511456.html 但是只包含http健康检查不包含tcp下面安装ngin ...
- ASP.NET Core 集成测试中结合 WebApplicationFactory 使用 SQLite 内存数据库
SQLite 内存数据库(in-memory database)的连接字符串是 Data Source=:memory: ,它的特点是数据库连接一关闭,数据库就会被删除.而使用 services. ...
- ide phpStorm常用代码片段设置
1.打开设置(File -> Settings) 2.如图 3 . 最后,在PHP文件中输入 ll 并按 TAB 即可打出代码块
- 20175303 2018-2019-2 《Java程序设计》第7周学习总结
20175303 2018-2019-2 <Java程序设计>第7周学习总结 教材学习内容总结 1.String类: Java专门提供了用来处理字符序列的String类 构造String对 ...
- LeetCode 606 Construct String from Binary Tree 解题报告
题目要求 You need to construct a string consists of parenthesis and integers from a binary tree with the ...
- java-方法重载、参数传递、
1.Java的方法重载overload:同一个类内,可以有多个同名的方法,只要参数不同即可(包括参数类型和个数.多类型顺序) 2.基本类型(8种:byte\short\int\long\double\ ...