Elastic Stack-Elasticsearch使用介绍(五)
一、前言
前4篇将Elasticsearch用法的API和原理方面东西介绍了一下,相信大家对Elasticsearch有了一定的认知,接下我们主要从索引的建立到后期的一些优化做一些介绍;
二、Mapping构建
之前介绍过Index就如同我们的数据库database,type相当于我们的表,而Mapping就是构建这些字段和索引关系的桥梁。数据库构建的时候我们要遵守三范式,那Mapping构建的时候我们要考虑那些因素?我认为要有以下几方面的考虑:
1.字段是什么类型;
对字段的类型做过介绍,考虑这个时候和数据库字段设置考虑问题基本一样;
2.是否需要被检索,也就是是否需要分词;
不需要检索的字段:index设置为false;不需要检索的字符类型直接设置成keyword类型;
需要检索的字段,可以通过index_options设定需要的存储分词的粒度,主要有以下四种参数docs 、 freqs 、 position 、 offsets,根据需要自行设定;
3.是否需要排序和聚合;
不需要排序或者聚合分析功能:doc_values设置为 false,fielddata设置为 false;
如果一个字段不需要检索、排序、聚合分析,则enabled设置为false;
4.是否需要另外的存储;
通过store 设定 true,即可存储该字段的原始内容,这里这个举个例子

以上就是我们建立Mapping时候需要考虑一些东西,接下来我们还有另外一个问题,数据库中表与表之间是有关联关系的,这个在Elasticsearch中是如何体现的?
在Elasticsearch中有两种方式可以去实现关联关系,
1.Nested Object(嵌套对象)
举个例子:

这个时候user字段会被映射成为object类型,这个时候JSON文档会被处理成为:

当我们查询的时候,就会意外出现的结果;

结果:

Elasticsearch针对这种情况提供Nested Object(嵌套对象)这个解决方案,
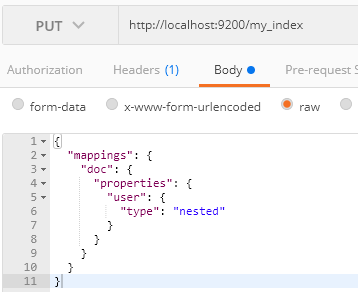
增加这一个步骤然后再按照上面步骤操作,就得到我们想要的结果;

当使用Nested Object内部是使用嵌套文档,当搜索first name为Alice和last name为White的时候就查询不到;
2.join
join数据类型是在同一个索引通过Parent和Child去指定父文档和子文档,然后形成1对多或者1对1的关系,举个例子:
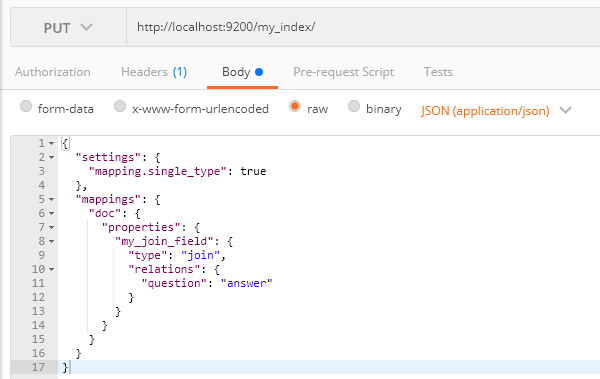
我这个是5.0以上的版本,不是6.0的版本,这个我还是忘记说,大家注意下版本问题,我大概说下这个意思就是只指定my_join_field字段question的父级为answer;
接下来我们再加入2条父级文档:
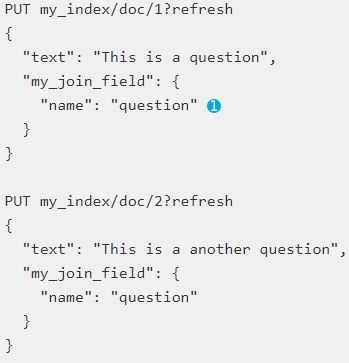
接下来在加入2条子文档:

这里需要注意的问题是路由必须要指定,父级文档必须和自己文档在同一个分片上,另外就是指定join的文档和父id;
这个时候我们查看下我们形成的文档:
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_source": {
"text": "This is a question",
"my_join_field": {
"name": "question"
}
},
"sort": [
""
]
},
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_source": {
"text": "This is a another question",
"my_join_field": {
"name": "question"
}
},
"sort": [
""
]
},
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_routing": "",
"_source": {
"text": "This is an answer",
"my_join_field": {
"name": "answer",
"parent": ""
}
},
"sort": [
""
]
},
{
"_index": "my_index",
"_type": "doc",
"_id": "",
"_score": null,
"_routing": "",
"_source": {
"text": "This is another answer",
"my_join_field": {
"name": "answer",
"parent": ""
}
},
"sort": [
""
]
}
]
}
}
看到结果我们就可以知道我们的1对多关系已经建立起来了,接下来我们按照父id来查询父id为1的文档:

这个地方还要提醒下,也是可以使用get的,只是使用神器的时候这样比较方便;
结果如下:

还可以使用has_child 返回包含某子文档的父文档,has_parent 返回包含某父文档的子文档这些就不写例子自己探索一下吧;
接下来做个对比:
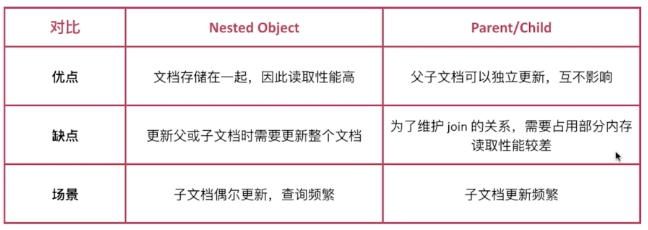
注意:Mapping字段不要设置太多;
三、部分优化的意见
elasticsearch.yml中建议设定的参数:
之前集群搭建的时候大家肯定设置一些参数,另外上面你的介绍也设置了一些参数,我们也具体来说下在上生产环境之前到底要设置那些参数:
1.cluster.name集群名称;
2.node.name节点名称;
3.node.master是否是主节点;
4.node.data是否存放数据,主节点不建议存放数据;
5.discovery.zen.ping.unicast.hosts设置集群的其他节点;
6.network.host IP;
7.path.data and path.logs 存放记录和日志的目录,默认是在Elasticsearch目录下;
8.discovery.zen.minimum_master_nodes 集群挂掉以后选举主的个数;
JVM设置:
1.将最小堆大小(Xms)和最大堆大小(Xmx)设置为彼此相等,防止垃圾回收过于频繁;
2.将Xmx设置为不超过物理RAM的50%,以确保有足够的物理RAM用于内核文件系统缓存;
3.不要超过32GB,这是JVM优化的建议;
分片的设置:
建议阅读这篇文章;
读写优化:
写入的优化,这个参考下Elastic Stack-Elasticsearch使用介绍(三)这篇文章,这篇文章我介绍写入时候的一些步骤,我们优化的方向就是从这3个方向:
当然要贯彻多线程、批量写入这个不能变得方针,针对refresh、translog、flush这3个方面做优化:
1.refresh
每refresh一次都会生成一个segment,如果refresh频率过高,可能会照成segment包含的文档数是很少,生成很多的segment;
调整方向
增大refresh_interval,降低实时性,默认是1s,设置为-1直接禁止自动refresh;
增大缓存区的大小,参数为indices.memory.index_buffer_size(静态参数,在elasticsearch.yml中设定,该参数设置后必须重启节点),默认为10%;
2.translog
目标是降低translog写磁盘的频率,从而提高效率,但是这样就会有掉丢数据的风险;
调整方向
index.translog.durabiliy设置为asyn,index.translog.sync_interval设置写入时间的间隔,单位是秒,比如10s,那么translog会改为每10s写一次磁盘,这个时候如果宕机就会丢失数据;
index.translog.flush_threshold_size 默认为512MB,超过该大小时会触发一次flush;
3.合理设置节点和分片的个数,通过设置index.routing.allocation.total_shards_per_node 限定每个索引在每个节点上可分配的总主副分片的个数;
读取的优化:
1.合理设置分片数
通过测试一个分片性能,然后根据业务进行计算,设置合理的分片个数;怎么测试一个分片的性能?首先搭建与生产一样的环境,接下来设定一个单分片无副本的索引,然后进行写入数据测试 和查询数据,然后根据提供的监控指标进行监控压力测试的情况,这部分监控内容下一章进行讲解;压测工具可以使用esrally,参考下这篇文章;
2.优化查询语句
尽量使用Filter上下文,减少算分的场景,由于Filter有缓存机制,可以提升查询性能;
四、结束
接下来会开始说一说监控的问题,欢迎大家加群438836709,欢迎大家关注我公众号!

Elastic Stack-Elasticsearch使用介绍(五)的更多相关文章
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- Elastic Stack核心产品介绍-Elasticsearch、Logstash和Kibana
Elastic Stack 是一系列开源产品的合集,包括 Elasticsearch.Kibana.Logstash 以及 Beats 等等,能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地 ...
- ES 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析和可视化. 最近查看 ELK 官方网站,发现新一代的日志采集器 File ...
- 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 二.ELK的几种常见架构 >>ELK 介绍<< ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析 ...
- Elastic Stack(ElasticSearch 、 Kibana 和 Logstash) 实现日志的自动采集、搜索和分析
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash(也称为 ELK Stack).能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据 ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 浅尝 Elastic Stack (一) Elasticsearch、Kibana、Beats 安装
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash,也称为 ELK Stack.能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据进 ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- Elastic Stack 笔记(四)Elasticsearch5.6 索引及文档管理
博客地址:http://www.moonxy.com 一.前言 在 Elasticsearch 中,对文档进行索引等操作时,既可以通过 RESTful 接口进行操作,也可以通过 Java 也可以通过 ...
随机推荐
- MySql开启慢查询日志并使用pt-query-digest 分析
慢查询日志会将查询过程中超出你设置的时间的查询记录下来,以便供开发者进行分析和优化. 1. 开启慢查询 1.1 查看当前设置 mysql> show variables like "% ...
- N元模型
在自然语言处理的任务中,拼音纠错.机器翻译等任务都需要对某个句子的下一个单词进行预测,或者评估某个句子的概率大小.例如预测如下句子的下一个单词: Please turn your home work. ...
- Java基础——集合(持续更新中)
集合框架 Java.util.Collection Collection接口中的共性功能 1,添加 booblean add(Object obj); 往该集合中添加元素,一次添加一个 boolea ...
- linux(centos)上安装mysql教程,为需要远程登录的用户赋予权限
最近把之前学生时代的win server换成了linux(centos)系统,因为win对于部署一些项目时候比较麻烦,直接入正题 1.准备阶段 我使用xshell工具管理服务器,相应下载和安装自行百度 ...
- Python爬虫入门教程 46-100 Charles抓取手机收音机-手机APP爬虫部分
1. 手机收音机-爬前叨叨 今天选了一下,咱盘哪个APP呢,原计划是弄荔枝APP,结果发现竟然没有抓到数据,很遗憾,只能找个没那么圆润的了.搜了一下,找到一个手机收音机 下载量也是不错的. 2. 爬虫 ...
- springcloud~配置中心实例搭建
server端 build.gradle相关 dependencies { compile('org.springframework.cloud:spring-cloud-config-server' ...
- 卷积神经网络 CNN 学习笔记
激活函数Relu 最近几年卷积神经网络中,激活函数往往不选择sigmoid或tanh函数,而是选择relu函数.Relu函数的定义 $$f(x)= max(0,x)$$ Relu函数图像如下图所示: ...
- Python编程从入门到实践笔记——操作列表
Python编程从入门到实践笔记——操作列表 #coding=utf-8 magicians = ['alice','david','carolina'] #遍历整个列表 for magician i ...
- Linux权限管理(week1_day5)--技术流ken
权限概述 Linux系统一般将文件可存/取访问的身份分为3个类别:owner(拥有者).group(和所有者同组的用户).others(其他人,除了所有者,除了同组的用户以及除了超级管理员),且3种身 ...
- vue中使用provide和inject刷新当前路由(页面)
1.场景 在处理列表时,常常有删除一条数据或者新增数据之后需要重新刷新当前页面的需求. 2.遇到的问题 1. 用vue-router重新路由到当前页面,页面是不进行刷新的 2.采用window.rel ...