python爬取youtube视频 多线程 非中文自动翻译
声明:我写的所有文章都是发在博客园的,我看到其他复制粘贴过去的 连个出处也不写,直接打上自己的水印。。。真是没的说了。
前言:前段时间搞了一些爬视频的项目,代码都写好了,这里写文章那就在来重新分析一遍吧。有不好的地方 莫见怪 : )
环境:python2.7 + win10
开始先说一下,访问youtube需要科学上网,请自行解决,最好是全局代理。
ok,现在开始,首先打开网站观察

网站很干净清爽,这次做的是基于关键字搜索来爬那些相关视频,这样就能很好的分类了,若输入中文搜索,那结果也一般都是国内视频,英文的话 那就是国外的。
这里先来测试中文的 ,输入''搞笑'',搜出来很多视频,也可以根据条件筛选,YouTube视频链接很有规律,都是这种https://www.youtube.com/watch?v=v_OVBHGwOaU,只有后面的 v值不一样,这里就叫id吧。
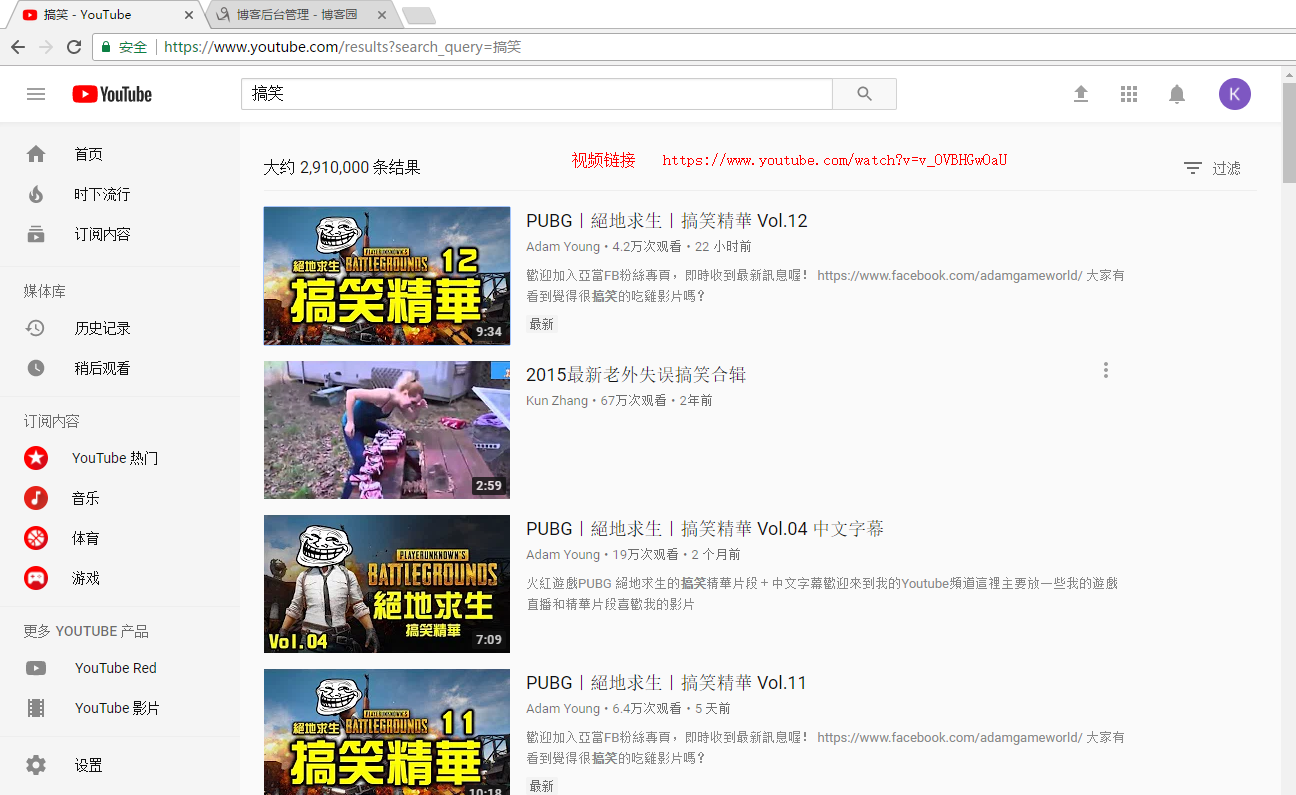
ok,先从最简单的开始,查看网页源代码看看这些视频链接是否都是在里面,我睁大了我的24k单身狗的眼睛找出来了。。。看了一下,视频信息全在这个<script>标签里面。
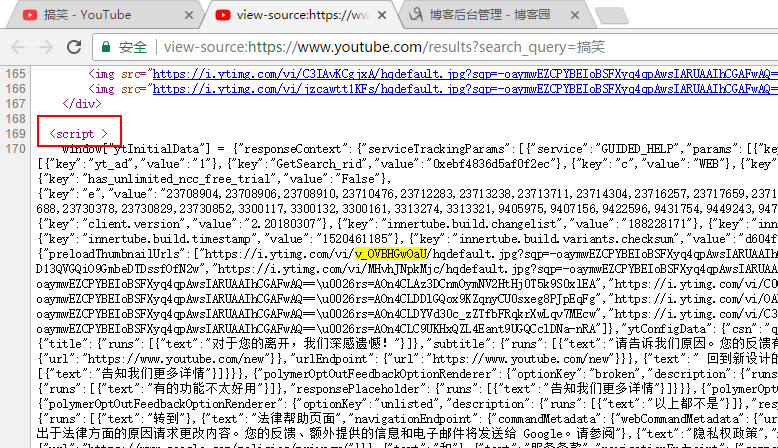
既然如此,那就直接上正则表达式来匹配
"url":"/watch\?v=(.*?)","webPageType"
这样就能匹配出ID来。但是 这好像只有第一页的视频,那第二页的呢,经常观察,此方法不行,视频翻页是基于ajax请求来的,源码里面的信息始终都是第一页的数据,ok 那既然这样,我们来分析ajax请求,我喜欢用谷歌浏览器,打开开发者工具,network,来抓包。
鼠标一直往下拉,会自动请求,是个post请求,一看就是返回的视频信息。
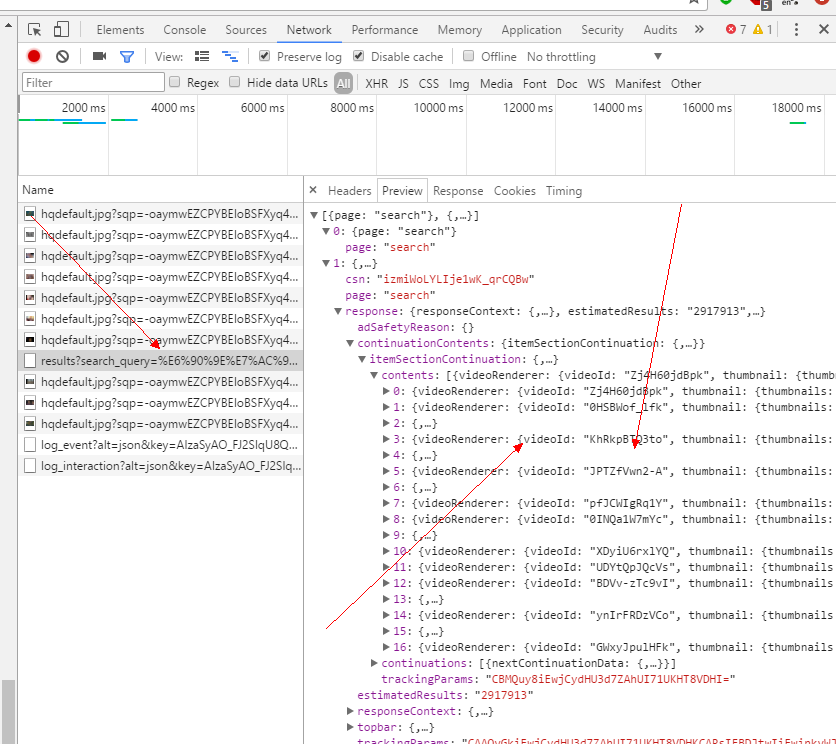
看到这里很高兴,离胜利已经不远了。但,我们先来看下headers 以及发送的post参数,看了之后 就一句 wtf。。。
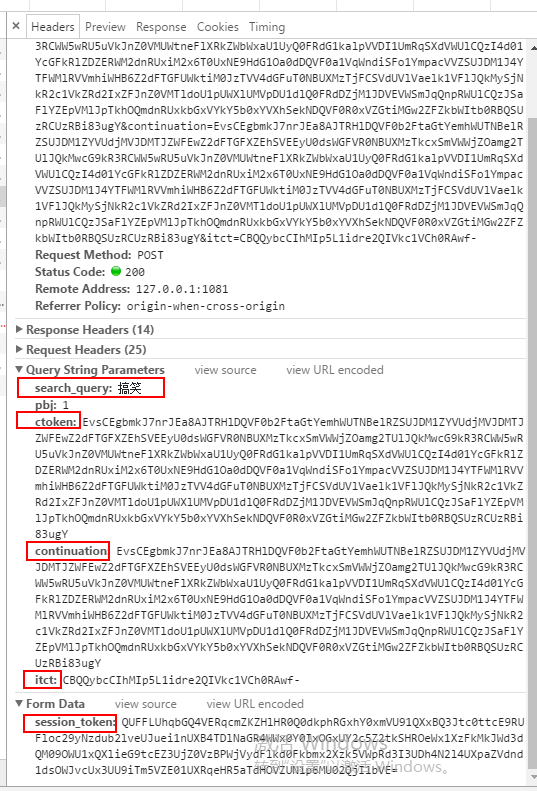
一万个羊驼在奔腾,我把那些加密的参数都标记了,前后端交互,既然是发过去的数据,那肯定已经在前端产生了,至于什么产生的,那就要一步一步分析来了,最后。对 我没有分析出来。。。刚开始挨着挨查看js文件,参数的确是在js里面产生的,但。。。tmd写的太复杂了。。。能力有限,解决不了。难道就这样放弃了吗。肯定不会,不然 各位也不会看到这篇文章了。于是,我灵机一动,在地址栏里面输入&page= 结果,真的返回视频了。。。卧槽 哈哈哈,我当时真是很开心呢。因为前端页面上并没有翻页按钮,没想到竟然还真的可以这样翻页。。。哈哈

既然这都被我猜出来了,那思路就很清晰了,翻页--获得源代码-- 正则匹配 --就可以批量得到视频链接了,然后去重后 在想办法直接通过这个链接去下载。于是,一阵百度 谷歌 找到很多方法,也找到很多api,ok 那就不必要重复造轮子,直接拿来用吧。
有一个开源项目youtube-dl 在github上 是个命令行的应用,安装之后,他是这样的。
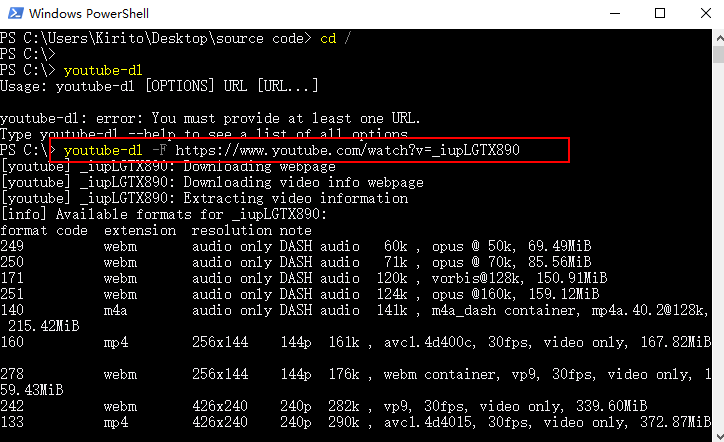
youtube-dl -F https://www.youtube.com/watch?v=_iupLGTX890
这样就能直接分析出所有视频格式的信息,然后通过id 就可以下载下来了。是很好用的一个工具。
在代码里面怎么使用呢,直接调用cmd命令就行了,但是。经过我测试发现呢,批量下载时候,老是有一些视频没有下载完整,所以 我就没用这个方法了,在国外网站上找到一个api 还蛮不错。
怎么找 怎么使用api 我就不用介绍了吧,等会直接贴代码,大家一看便知。
这里在说下,当我输入关键字是英文的话,搜出来的结果全部是英文的,于是 我就下载成功后,保存文件 翻译一下他的标题。翻译成中文的,我去找翻译,最后就用金山词霸了,如果使用官方api的话,好像也有收费。。那不行,我要直接爬页面,于是,我就直接还是爬他的翻译页面,提交英文,返回中文,解析网页,正则匹配出来。就这样 嘿嘿嘿。。
ok。说了这么多了 现在上代码。
# -*-coding:utf-8-*-
# author : Corleone
from bs4 import BeautifulSoup
import lxml
import Queue
import requests
import re,os,sys,random
import threading
import logging
import json,hashlib,urllib
from requests.exceptions import ConnectTimeout,ConnectionError,ReadTimeout,SSLError,MissingSchema,ChunkedEncodingError
import random reload(sys)
sys.setdefaultencoding('gbk') # 日志模块
logger = logging.getLogger("AppName")
formatter = logging.Formatter('%(asctime)s %(levelname)-5s: %(message)s')
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter
logger.addHandler(console_handler)
logger.setLevel(logging.INFO) q = Queue.Queue() # url队列
page_q = Queue.Queue() # 页面 def downlaod(q,x,path):
urlhash = "https://weibomiaopai.com/"
try:
html = requests.get(urlhash).text
except SSLError:
logger.info(u"网络不稳定 正在重试")
html = requests.get(urlhash).text
reg = re.compile(r'var hash="(.*?)"', re.S)
result = reg.findall(html)
hash_v = result[0]
while True:
data = q.get()
url, name = data[0], data[1].strip().replace("|", "")
file = os.path.join(path, '%s' + ".mp4") % name
api = "https://steakovercooked.com/api/video/?cached&hash=" + hash_v + "&video=" + url
api2 = "https://helloacm.com/api/video/?cached&hash=" + hash_v + "&video=" + url
try:
res = requests.get(api)
result = json.loads(res.text)
except (ValueError,SSLError):
try:
res = requests.get(api2)
result = json.loads(res.text)
except (ValueError,SSLError):
q.task_done()
return False
vurl = result['url']
logger.info(u"正在下载:%s" %name)
try:
r = requests.get(vurl)
except SSLError:
r = requests.get(vurl)
except MissingSchema:
q.task_done()
continue
try:
with open(file,'wb') as f:
f.write(r.content)
except IOError:
name = u'好开心么么哒 %s' % random.randint(1,9999)
file = os.path.join(path, '%s' + ".mp4") % name
with open(file,'wb') as f:
f.write(r.content)
logger.info(u"下载完成:%s" %name)
q.task_done() def get_page(keyword,page_q):
while True:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'
}
page = page_q.get()
url = "https://www.youtube.com/results?sp=EgIIAg%253D%253D&search_query=" + keyword + "&page=" + str(page)
try:
html = requests.get(url, headers=headers).text
except (ConnectTimeout,ConnectionError):
print u"不能访问youtube 检查是否已翻墙"
os._exit(0)
reg = re.compile(r'"url":"/watch\?v=(.*?)","webPageType"', re.S)
result = reg.findall(html)
logger.info(u"第 %s 页" % page)
for x in result:
vurl = "https://www.youtube.com/watch?v=" + x
try:
res = requests.get(vurl).text
except (ConnectionError,ChunkedEncodingError):
logger.info(u"网络不稳定 正在重试")
try:
res = requests.get(vurl).text
except SSLError:
continue
reg2 = re.compile(r"<title>(.*?)YouTube",re.S)
name = reg2.findall(res)[0].replace("-","")
if u'\u4e00' <= keyword <= u'\u9fff':
q.put([vurl, name])
else:
# 调用金山词霸
logger.info(u"正在翻译")
url_js = "http://www.iciba.com/" + name
html2 = requests.get(url_js).text
soup = BeautifulSoup(html2, "lxml")
try:
res2 = soup.select('.clearfix')[0].get_text()
title = res2.split("\n")[2]
except IndexError:
title = u'好开心么么哒 %s' % random.randint(1, 9999)
q.put([vurl, title])
page_q.task_done() def main():
# 使用帮助
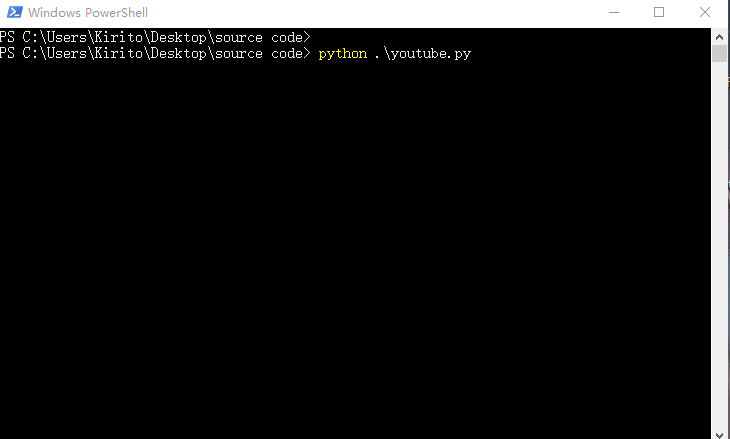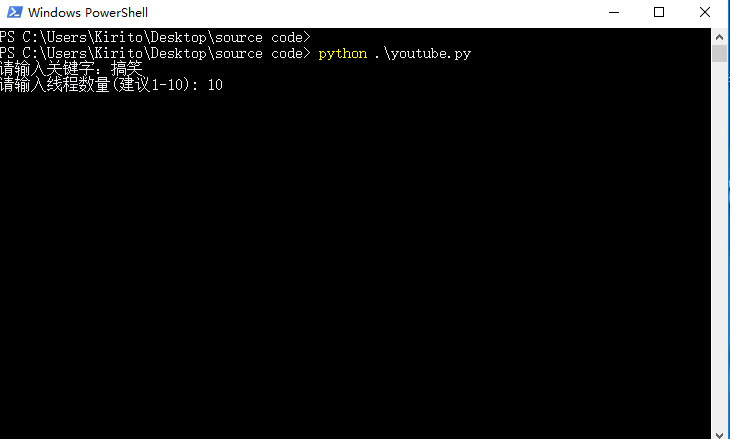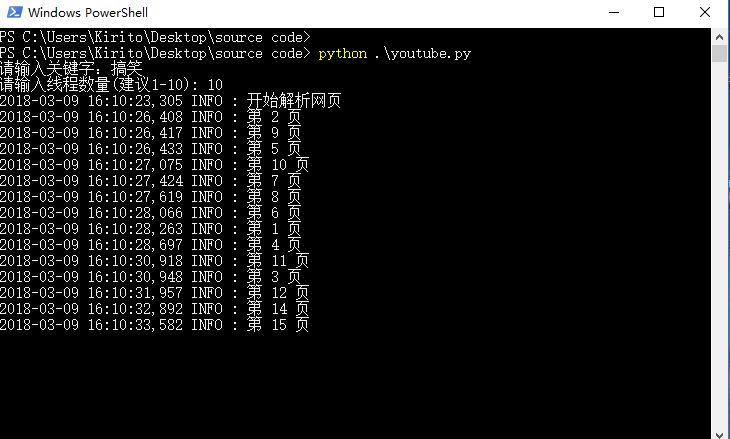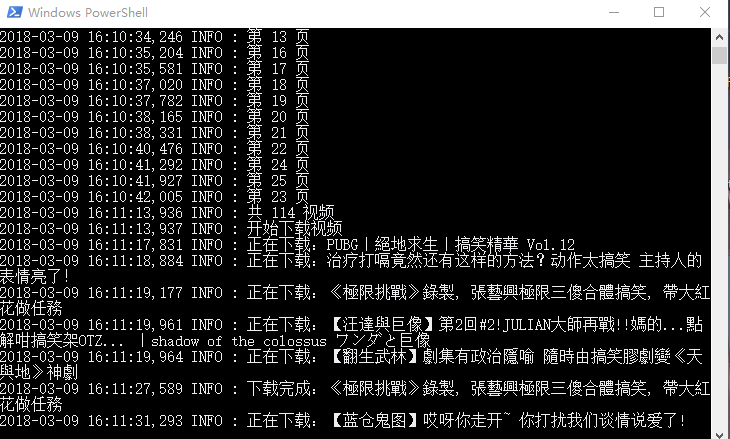
keyword = raw_input(u"请输入关键字:").decode("gbk")
threads = int(raw_input(u"请输入线程数量(建议1-10): "))
# 判断目录
path = 'D:\youtube\%s' % keyword
if os.path.exists(path) == False:
os.makedirs(path)
# 解析网页
logger.info(u"开始解析网页")
for page in range(1,26):
page_q.put(page)
for y in range(threads):
t = threading.Thread(target=get_page,args=(keyword,page_q))
t.setDaemon(True)
t.start()
page_q.join()
logger.info(u"共 %s 视频" % q.qsize())
# 多线程下载
logger.info(u"开始下载视频")
for x in range(threads):
t = threading.Thread(target=downlaod,args=(q,x,path))
t.setDaemon(True)
t.start()
q.join()
logger.info(u"全部视频下载完成!") main()
在这里在说一下,我当时用的win10 所有编码全是gbk的,若在linux上面跑,请自行修改。也是多线程下载的,默认下载目录 d:\youtube 然后会根据关键字在创建子目录,视频都放在里面。对了 还有我代码里面用筛选了,只爬1天之内更新的。每天爬一遍即可。
来测试一下。下载的时候 就是考验网速的时候了,网不好了,可能会出现一些我没捕获的异常。。。可能是我找的fq服务器网速还行。。
ok 到这里整篇文章就结束了,写文章都快弄了一个小时了。。不容易呢 :-
我的github地址 https://github.com/binglansky/spider
嘿嘿,欢迎一块学习交流 :) ~~~
python爬取youtube视频 多线程 非中文自动翻译的更多相关文章
- python爬取快手视频 多线程下载
就是为了兴趣才搞的这个,ok 废话不多说 直接开始. 环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为htt ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- python爬取百思不得姐视频
# _*_ coding:utf-8 _*_ from Tkinter import * from ScrolledText import ScrolledText import urllib #im ...
- python 爬取bilibili 视频信息
抓包时发现子菜单请求数据时一般需要rid,但的确存在一些如游戏->游戏赛事不使用rid,对于这种未进行处理,此外rid一般在主菜单的响应中,但有的如番剧这种,rid在子菜单的url中,此外返回的 ...
- python 爬取bilibili 视频弹幕
# -*- coding: utf-8 -*- # @author: Tele # @Time : 2019/04/09 下午 4:50 # 爬取弹幕 import requests import j ...
- 【Python爬虫案例学习2】python多线程爬取youtube视频
转载:https://www.cnblogs.com/binglansky/p/8534544.html 开发环境: python2.7 + win10 开始先说一下,访问youtube需要那啥的,请 ...
- 用 pytube 爬取 youtube 视频
这个方法比直接用浏览器插件逼格高点 1. 简介 需要用到 pytube 这个第三方库:https://github.com/nficano/pytube 这里只是把这个页面捡重要部分翻译了一下. py ...
- python爬取网站视频保存到本地
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Woo_home PS:如有需要Python学习资料的小伙伴可以加点 ...
- 2019-02-09 python爬取mooc视频项目初级简单版
今天花了一下午时间来做这东西,之前没有自己写过代码,50几行的代码还是查了很多东西啊,果然学起来和自己动起手来完全是两码事. 方案:requests库+正则表达式提取视频下载链接+urlretriev ...
随机推荐
- 关于git post-receive 钩子
登录 git服务器 进入你项目所在git文件夹 cd /var/opt/gitlab/git-data/repositories/liangyuquan/yfg.git cd hooks vim po ...
- markdown语法探究
\[\sum_{i=1}^n a_i=0\] \[f(x_1,x_x,\ldots,x_n) = x_1^2 + x_2^2 + \cdots + x_n^2 \] \[\sum^{j-1}_{k=0 ...
- 一个网卡配置多个ip配置实现,centos7系统
仅一个网卡情况下,配置多个ip可以让该设备通过几个ip被访问,或隐藏常用ip,让其他人访问临时ip 一.永久性增加一个IP 方法1: vim /etc/sysconfig/network-script ...
- C++11 标准库也有坑(time-chrono)
恰巧今天调试程序遇到时间戳问题, 于是又搜了搜关于取时间戳,以及时间戳转字符串的问题, 因为 time() 只能取到秒(win和linux) 想试试看能不能找到 至少可以取到毫秒的, 于是, 就找 ...
- 【linux之find及awk】
一.find命令 find 精确查找,根据提供的条件或组合条件进行查找,遍历所有文件,因此速度比较慢. 语法: find 目录 条件 动作 默认目录是当前目录默认条件是所有条件默认动作是显示查找到的信 ...
- http权威指南笔记
请求报文 响应报文GET /test/hi.txt HTTP/1.0 起始行 HTTP/1.0 200 OKAccept: text/* 首部 Content-type: text/plainAcce ...
- PHP秒杀系统全方位设计(二)
商品页面开发 静态化展示页面[效率要比动态PHP高很多,PHP程序需要解析等步骤,本身就需要很多流程,整个下来PHP的处理花的时间和资源要多] 商品状态的控制 开始前.进行中.库存不足.结束 数据逻辑 ...
- Mysql内置的profiling性能分析工具
要想优化一条 Query,我们就需要清楚的知道这条 Query 的性能瓶颈到底在哪里,是消耗的 CPU计算太多,还是需要的的 IO 操作太多?要想能够清楚的了解这些信息,在 MySQL 5.0 和 M ...
- java线程间通信1--简单实例
线程通信 一.线程间通信的条件 1.两个以上的线程访问同一块内存 2.线程同步,关键字 synchronized 二.线程间通信主要涉及的方法 wait(); ----> 用于阻塞进程 noti ...
- linux链接
( 1 )软连接可以跨文件系统,硬连接不可以 ( 2 )硬连接不管有多少个,都指向的是同一个 I 节点,会把结点连接数增加,只要结点的连接数不是 0 ,文件就一直存在不管你删除的是源文件还是连接的文件 ...